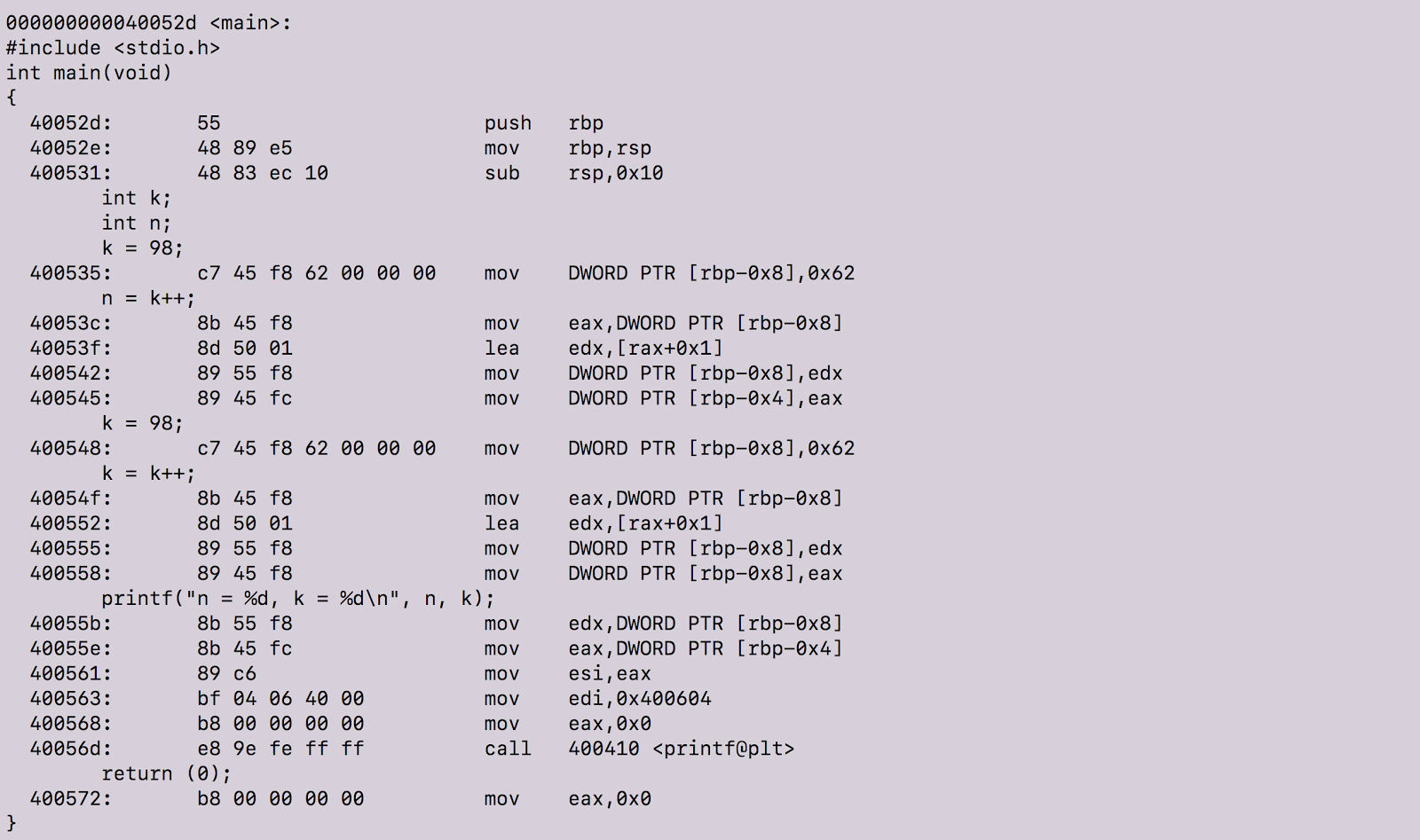
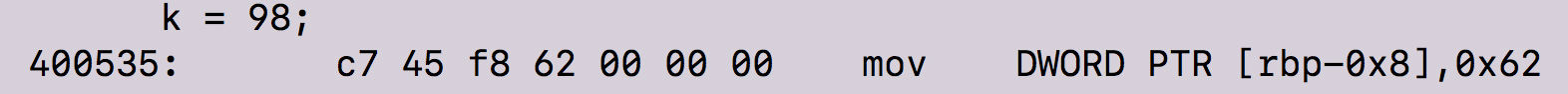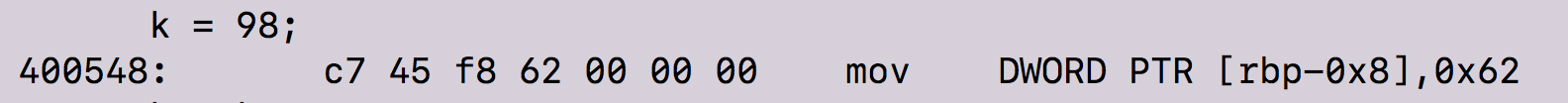Looking at this code, what would you anticipate the respective values of variables ’n’ and ‘k’ to be?
Despite the confidence expressed in the blogosphere and forums, a number of software engineers would be incorrect….
To understand why ‘k’ increments in this way, we need an abbreviated understanding of how the function’s operations are managed.
For these examples, we are using a 64 bit machine, Ubuntu 14.04 LTS, GCC 4.8.4, and 3.13.0–107-generic GNU/Linux.
As we’ve covered in priorposts, when you compile a program (obviously, comprised of arguments and variables), it goes through a multitude of steps to be executable. The executable arguments and variables need a place to be stored, so that it can be managed and manipulated — resulting in the fulfillment of the function’s requests and directives. This is where the loader comes into play; the loader creates a space of virtual memory addresses where our stack — as well as many other things — will be located. The stack is a data structure that has “last in first out” (LIFO) data storage; the first information entering the stack has a higher memory address, whereas the addition of subsequent information “grows” downward — having a lower memory address.
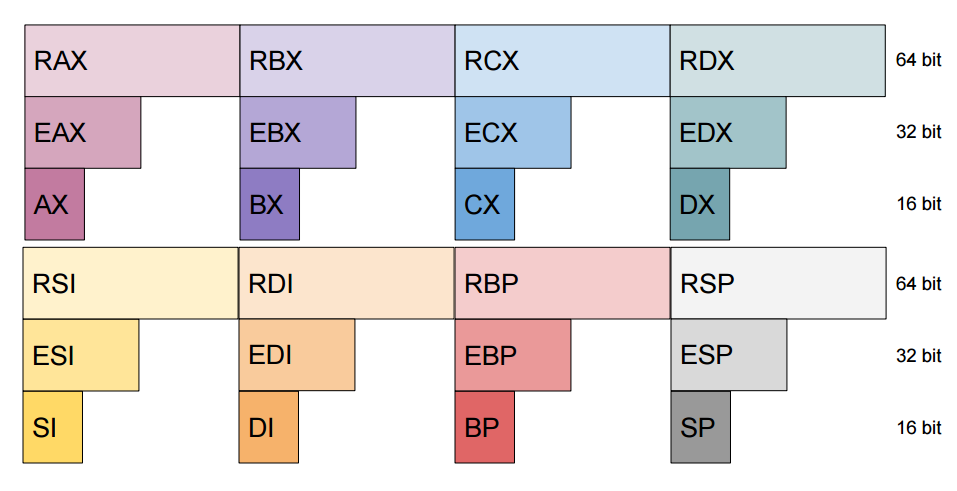
The stack’s data is navigated and controlled by registers. Registers allow for fast processing and internal memory storage without having to access the physical memory. There are eight 16 bit general registers — ax, bp, bx, cx, di, dx, si, and sp (they are case insensitive) — that handle respective tasks. Depending on the operation, program, or processor different register size is required. Extended 32 bit versions can be accessed with the prefix “e”, and the long 64 bit size by prefixing with an “r”.
These are the basics (starting with the two most fundamental); having a reference for their utility will help you understand some object code…
BP, EBP, RBP is the base pointer which points to the address of the bottom of the stack; it’s a fixed reference point for the corresponding function’s parameters and variables within that stack frame.
SP, ESP, RSP on the other hand, is the stack pointer to the address of the top of the stack.
AX, EAX, RAX alongside DX, is responsible for arithmetic operations. It aids with transferring data.
BX, EBX, RBX is a data pointer — only register capable of indirect addressing.
CX, ECX, RCX does loop counting.
DI, EDI, RDI is the pointer to destination in string and memory operations.
DX, EDX, RDX handles input/output as well as arithmetic operations.
SI, ESI, RSI is the pointer to source in string and memory operations.
Moving forward (with all that in mind), what exactly is happening when we initialize k as k++? What exactly is happening in the machine code (or assembly code) that results in this output? Finding the answer to this question inches us closer to the exciting realm of reverse engineering.
In order to fully investigate this, there is a program called objdump we can use within the Linux shell that allows us to “see” inside the machine code. Before jumping into my explanation, let’s review this program:
objdumpis a program for displaying various information about object files. As you will recall from our previous posts, object code is generated during the third stage of compilation, also called assembly. In order to help us parse through the information displayed using objdump we will run it with several options:
-j Display information only for a specified section — today we will only be reviewing two sections: .rodata — this is where read-only data is stored .text this is the program’s actual code (the assembly) — _start and main are both part of this section
-s Displays the full contents of any sections requested. By default all non-empty sections are displayed.
-M Assembly has two versions of syntax — AT&T or Intel. We use -M intel to tell objdump to display output in intel format.
-d Display the assembler mnemonics for the machine instructions from objfile. This option only disassembles those sections which are expected to contain instructions.
-S Display source code intermixed with disassembly, if possible. This is helpful because it will show the lines from our program.
Now that we’ve reviewed objdump — let’s combine that with our investigation into what happens when we specify that k=k++.
The above tells us where the read-only data is stored.
Objdump program ran with flags introduced above
objdump with the above option flags produces our object code with our source code intermixed in the output. In fact, many lines of object code are produced and we are only referencing the section with our source code. To view all of the object code, click here.
There are definitely lots of cool things happening there. Before we proceed, let’s review machine instructions. According to this guide, “machine instructions generally fall into three categories: data movement, arithmetic/logic, and control-flow.” In the above screenshot, the data movement instructions occur in the second to last column.
A short summary of data movement instructions:
mov — Move — this instruction copies data item referred to by its second operand into the location referred to by its first operand. For example: mov eax, ebx— copy the value in ebx into eax
push — push stack — this instruction places its operand onto the top of the hardware supported stack in memory. For example: push eax— push eax on the stack
pop — pop stack — this instruction removes the 4-byte data element from the top of the hardware-support stack into the specified operand. For example: pop edi — pop the top element of the stack into EDI
lea — Load effective address — the instruction places the address specified by its second operand into the register specified by its first operand. Keep in mind, the contents of the memory location are not loaded, but only the effective address is computed and placed into the register. For example: lea eax, [var] — the value [var] is placed in EAX
There are arithmetic, logic and control flow instructions that I will not delve into more — for the purposes of this post, you will need to only know the above as well as one more:
call subroutine call — this control flow instruction pushes the current code location onto the hardware support stack in memory and then performs an unconditional jump to the code location indicated by the label operand. This instruction saves the location to return to when the subroutine completes.
Size directives
BYTE PTR indicates size of 1 byte
WORD PTR indicates size of 2 bytes
DWORD PTR indicates size of 4 bytes
Now that we know what machine instructions are, let’s step in and see what’s happening at a granular level in our program.
The instructions here tell the machine to copy the 32-bit integer representation of 0x62 into the stack at the address rbp-0x8. Remember, since we are compiling our program on a 64-bits machine running Ubuntu 14.04 LTS our integers will be 4 bytes long.
In case you were wondering what in the world 0x62 has to do with k = 98, a simple Google search reveals that 0x62 is the hexadecimal representation of the number 98.
So, at this moment, k = 98 — we know this because the machine instructions above corresponds to the C code k = 98 and the equivalent of k is stored at address rbp-0x8 in our assembly code.
Now, when we initialize our variable n to equal k++ we see the following happen in this order:
The value 98 is taken from rbp-8 (the equivalent of k in our C code) — 98 — and copied to the register eax
eax is a subregister of rax. Since eax contains 98, this line of machine instruction indicates that we are adding 98+1 and storing the result into edx
The value in edx (99) is copied to the location referred to by rbp-0x8. Since rbp-0x8 is the equivalent of k , now k = 99.
The value in eax (98) is copied to the location referenced by rbp-0x4. This means by the end of this line of instruction, n = 98.
As you can see, by the end of the fourth machine instruction, the original value of 98 is called. Similarly, we see the same as above instructions happen in the next two lines of code.
The only part where this is different from the above code is that the value of eax(98) is copied to the location referenced by rbp-0x8.
At this point, we know that both rbp-0x8 and rbp-0x4 carry the value of 98. From here the values are stored and then the call instruction tells program to use printf function to print the stored values to standard output.
Lastly, we see that the value of 0x0 is copied into eax — eax will store the return value of the functions. The return value of main will be 0, meaning that the program successfully ran.
So, from this, we can conclude that k = k++ returns k. Why? Well, k++ does in fact increment 98 to 99. The stored value resets the value of k to 98 by the end of the program. In other words, the iteration is only performed on a value stored in temporary location and that location was not called by the program.
Authors
Elaine Yeung is an elementary school dean turned software engineering student at Holberton School.
Naomi Sorrell is an enthusiastic tech newbie at Holberton School that enjoys man pages, fitness, and traveling
Resources
“Assembly Language Tutorial.” Assembly Language Tutorial. N.p., n.d. Web. 11 Mar. 2017.
Bacon, Jason W. “10.7. The Stack Frame.” 10.7. The Stack Frame. N.p., Mar. 2011. Web. 23 Mar. 2017.
Dang, Bruce, Alexandre Gazet, Elias Bachaalany, and SeÌbastien Josse. Practical Reverse Engineering: X86, X64, ARM, Windows Kernel, Reversing Tools, and Obfuscation. Indianapolis, IN: Wiley, 2014. Print.
Koopman, Phillip. “Stack Computers: 9.2 VIRTUAL MEMORY AND MEMORY PROTECTION.” Stack Computers: 9.2 VIRTUAL MEMORY AND MEMORY PROTECTION. N.p., 1989. Web. 11 Mar. 2017.
“Memory Layout of C Programs.” GeeksforGeeks. N.p., 30 Nov. 2016. Web. 11 Mar. 2017.
Milea, Andrea. “Dynamic Memory Allocation and Virtual Memory.” Understanding Virtual Memory and the Free Store (heap) — Cprogramming.com. C Programming, n.d. Web. 11 Mar. 2017.
“Stack (abstract Data Type).” Wikipedia. Wikimedia Foundation, 11 Mar. 2017. Web. 11 Mar. 2017.
Tutorialspoint.com. “Operating System — Virtual Memory.” www.tutorialspoint.com. N.p., n.d. Web. 11 Mar. 2017.
Tutorialspoint.com. “Assembly Registers.” www.tutorialspoint.com. N.p., n.d. Web. 11 Mar. 2017.
“Virtual Memory.” Wikipedia. Wikimedia Foundation, 10 Mar. 2017. Web. 11 Mar. 2017.