
Regular expressions are a powerful means for pattern matching and string parsing that can be applied in so many instances. With this incredible tool you can:
-
Validate text input
-
Search (and replace) text within a file
-
Batch rename files
-
Undertake incredibly powerful searches for files
-
Interact with servers like Apache
-
Test for patterns within strings
-
And so much more
The thing about regular expressions is that they are confusing. To the new Linux user, regular expressions may as well be another language (which they sort of are anyway). Considering the power this tool offers, it is something that every system administrator should learn. Although it may take quite some to master regular expressions, it will be time very well spent.
I want to introduce you to regular expressions, assuming you are starting at square zero. In other words, this is focused specifically on beginners. If you have yet to dive into regular expressions or have barely a rudimentary understanding, you will benefit from these words.
With that said, let’s begin.
What makes up regular expressions
There are two types of characters to be found in regular expressions:
-
literal characters
-
metacharacters
Literal characters are standard characters that make up your strings. Every character in this sentence is a literal character. You could use a regular expression to search for each literal character in that string.
Metacharacters are a different beast altogether; they are what give regular expressions their power. With metacharacters, you can do much more than searching for a single character. Metacharacters allow you to search for combinations of strings and much more. The list of regular expression metacharacters is:
-
Indicates the next character is either a special character, a literal, a backreference, or an octal escape
-
^ Indicates the beginning of an input string
-
$ Indicates the end of the an input string
-
* Indicates the preceding subexpression is to be matched zero or more times
-
+ Indicates the preceding subexpression is to be matched one or more times
-
? Indicates the preceding subexpression is to be matched zero or one time
-
{n} Match exactly n times (Where n is a non-negative integer)
-
{n,} Match at least n times (Where n is a non-negative integer)
-
{n,m} Match at least n and at most m times (Where m and n are non-negative integers and n <= m)
-
. Matches any single character except “n”
-
[xyz] Match any one of the enclosed characters
-
x|y Match either x or y
-
[^xyz] Match any character not enclosed
-
[a-z] Matches any character in the specified range.
-
[^a-z] Matches any character not in the specified range
-
b Matches a word boundary (the position between a word and a space)
-
B Matches a nonword boundary (example: ‘uxB’ matches the ‘ux’ in “tuxedo” but not the ‘ux’ in “Linux”
-
d Matches a digit character
-
D Matches a non-digit character
-
f Matches a form-feed character
-
n Matches a newline character
-
r Matches a carriage return character
-
s Matches any whitespace character (including space, tab, form-feed, etc.)
-
S Matches any non-whitespace character
-
t Matches a tab character
-
v Matches a vertical tab character
-
w Matches any word character including underscore
-
W Matches any non-word character
-
un Matches n, where n is a Unicode character expressed as four hexadecimal digits (such as, u0026 for the ampersand symbol)
How do you use metacharacters? Simple. Say you want to match the string 1+2=3. Although 1+2=3 is a valid regular expression, if you attempted to search for that string without metacharacters, the match would fail. Instead, you would have to make use of the backslash character, like so:
1+2=3
Why are we only using the backslash before the + and not the =? Go back to the list of metacharacters, and you’ll see that + is listed and = is not. The + metacharacter indicates the preceding is to be matched one or more times, so 1+2 would mean 1 is repeated two more times, as in 111. If we were to go without the in that string, it wouldn’t match 1+2=3, it would match 111=2 in 123+111=234.
A few easy examples
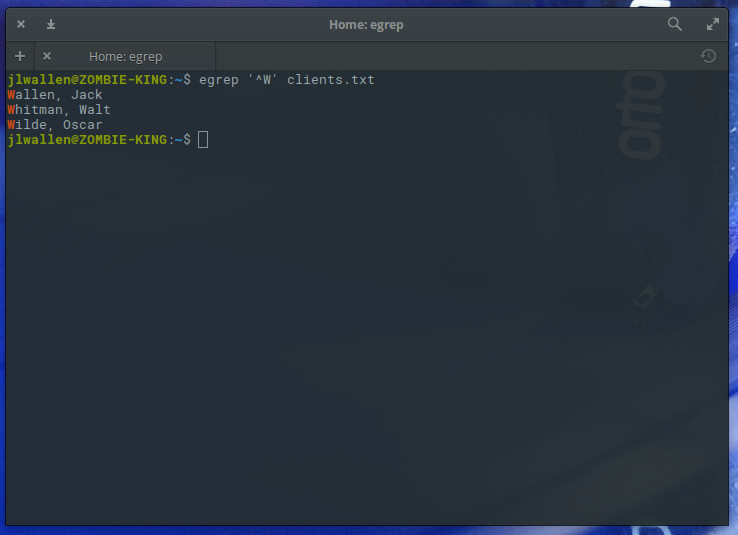
Two other very useful metacharacters are the ^ (indicates the beginning of an input string) and $ (indicates the end of an input string). Say, for example, you wanted to search a lengthy file of client names for all clients whose last name starts with W (assuming all names are listed last name, first name in the file). You could use regular expressions with the egrep command like so:
egrep ‘^W’ clients.txt
The resulting command would list out all clients whose last name started with “W” (Figure 1).
What if we want to run that same search, only this time we want to (for whatever reason) list out all clients whose first name ends with “n”. With regular expressions we can do that like so:
egrep ‘n$’ clients.txt
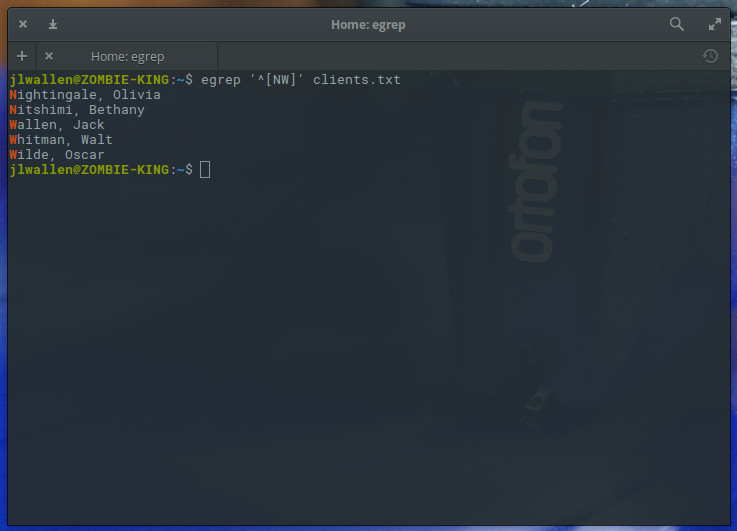
Naturally, this will only work if the first name is the last string of characters on each line. If you wanted to list out all clients whose last name started with either “N” or “W”, you could make use of the metacharacters ^ and [ ] like so:
egrep ‘^[NW]’ clients.txt
The above command would list out all clients whose last name started with either “N” or “W” (Figure 2).
What if, however, you wanted to list out clients whose first and/or last name contained either “N” or “W” (since this is case sensitive, we assume a capital letter will begin a client name)? That’s simple; we add the “|” metacharacter (along with the “^” metacharacter), which would contain the search to first characters, like so:
egrep ‘^[N|W]’ clients.txt
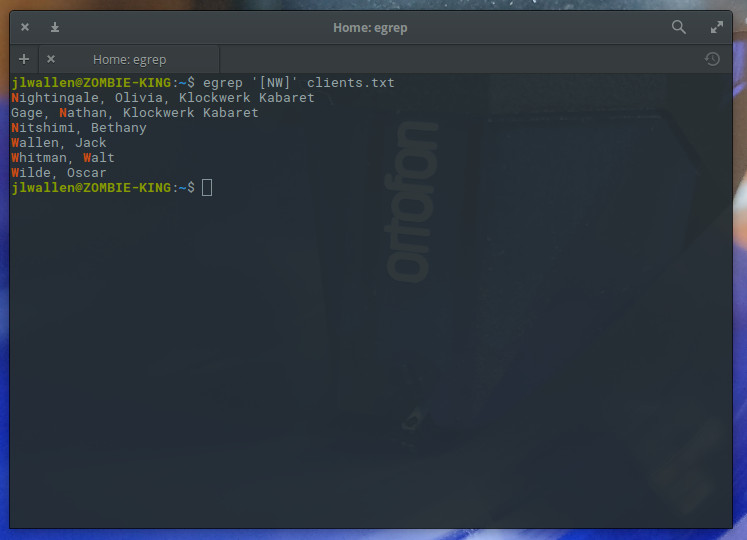
We could also remove the ^ metacharacter and run the command like so:
egrep ‘[NW]’ clients.txt
The resulting output would list all names containing either “N” or “W” (Figure 3), not limiting the search to initial characters within a string.
You could use a similar command to search for any characters within a name (such as egrep ‘[en]’ clients.txt), which would list out all strings that contained either letter “e” or “n”.
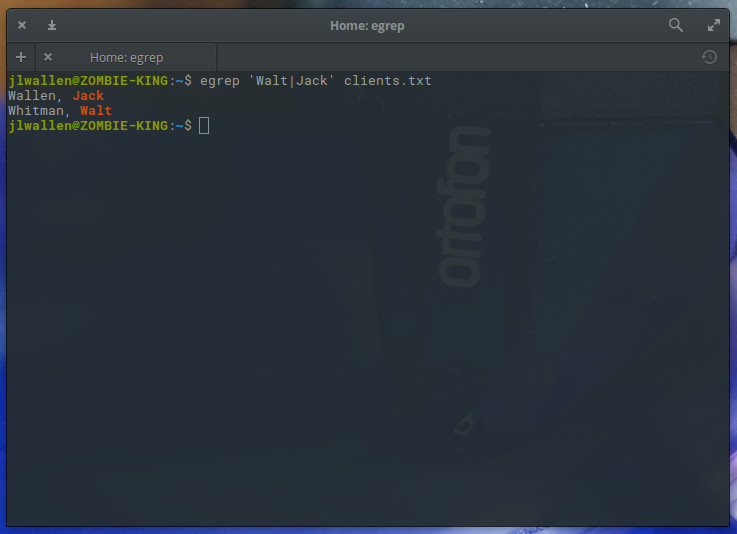
What if, however, you wanted to match all entries that included the first name Jack and the first name Walt? You could do that as well with the help of the the “|” metacharacter (which matches x or y. The following regular expression illustrates its usage:
egrep ‘Walt|Jack’ clients.txt
The output of the command should be exactly as you expected (Figure 4).
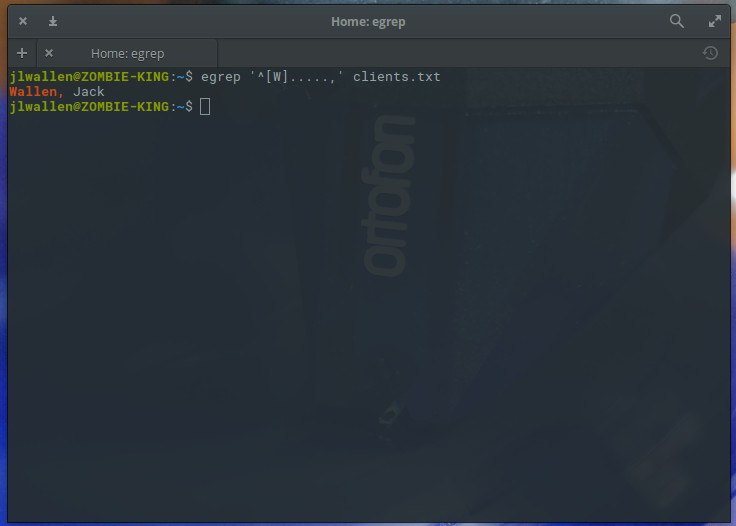
One final example will illustrate how you can use regular expressions to search for strings of a specific length. This is done with what is called a character set. Say (for whatever reason) you want to search the client listing for entries that start with the letter W and are only six characters long. For that you would use the “.” metacharacter like so:
egrep ‘^[W].....,’ clients.txt
Because all names in our clients.txt file are followed by a “,”, we can do this easily and the results will display only those names that are six characters in length and begin with the letter “W” (Figure 5).
So much more to learn
You have only now scratched the surface of regular expressions. For more information on this amazing tool, check out the regex(3) and regex(7) man pages. Regular expressions are definitely one element of Linux administration you are going to want to master. Take the time to further educate yourself with this tool and you’ll have considerable power at your fingertips.
Learn more about Linux through the free “Introduction to Linux” course from The Linux Foundation and edX.





{kind=link}