
June 3, 2009, 8:07 am
In the third and final part of this series on examining filesystem benchmarks, we’ll examine the obvious benchmark of how many open, write, fsync, close, rename cycles can be performed per second, as well as the benchmark program itself.
The next benchmark I chose was the most obvious: how many open, write, fsync, close, rename cycles can be performed per second. The benchmark includes both with and without the fsync call and was performed with and without a kernel compile loop happening on the same filesystem. The benchmark program was run using 10,000 open-to-rename cycles, each time writing 16,000 bytes of data to the new file. The benchmark program is shown below:
#define _XOPEN_SOURCE
#include
#include
#include
#include
#include
#include
int main( int argc, char** argv )
{
int idx=1;
char* basepath = argv[idx++];
const int cycleloops = atoi(argv[idx++]);
const int writesz = atoi(argv[idx++]);
const int writeloops = atoi(argv[idx++]);
const int perform_fsync = atoi(argv[idx++]);
char* writebuffer = calloc(writesz,1);
const int pathsz = 4096;
char oldpath[ pathsz ];
char newpath[ pathsz ];
snprintf( oldpath, pathsz, "%s/%s", basepath, "foo" );
snprintf( newpath, pathsz, "%s/%s", basepath, "foo.new" );
int rc = 0;
for( int cyclecount = 0; cyclecount < cycleloops; ++cyclecount )
{
int fd = open( newpath, O_CREAT|O_TRUNC|O_WRONLY, S_IRWXU );
if( fd == -1 )
{
fprintf( stderr, "open error! path:%sn",newpath);
exit(1);
}
for( int i=0; i
{
rc = write( fd, writebuffer, writesz );
if( rc != writesz )
{
fprintf( stderr, "underwrite!n");
exit(1);
}
}
if( perform_fsync && fsync( fd ) )
{
perror( "fsync failed!n");
exit(1);
}
if( close(fd) )
{
perror( "close failed!n");
exit(1);
}
if( rename( newpath, oldpath ) )
{
perror( "rename failed!n");
exit(1);
}
}
return 0;
}
The first round of tests were run with the arguments 10000 16000 1 $FSYNC where the latter option was used to turn on and off the fsync(2) call. This amounts to 10,000 rename(2) calls where each new file has 16,000 bytes written to it in a single write(2) call.
Shown below is the test on an idle filesystem without the fsync call.
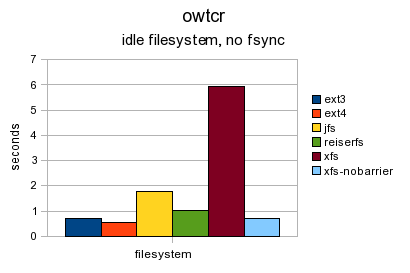
Shown below is the exact same benchmark on an idle filesystem but an fsync is performed before the close each loop. It is interesting that the two slowest filesystems are ext4 and XFS (with barriers enabled). This would seem to indicate that the block level write barriers used by the fsync call are the major slowdown. For the remaining filesystems, the ext3 filesystem shows the largest slowdown due to the added fsync call.
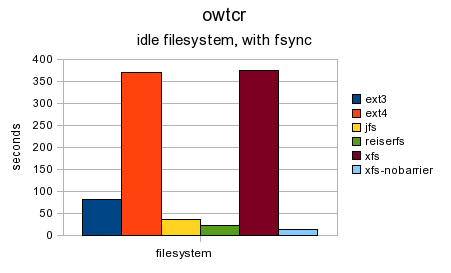
Shown below is the test without using fsync but when a kernel compilation is happening in the background. There is little difference in the benchmark between an idle filesystem and the loaded one.
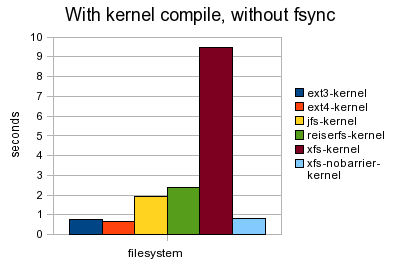
The final graph is using fsync while compiling a kernel. Compared to the idle filesystem with fsync (two graphs up) there is a slight jump across the board in the time required but it is not many times slower than when fsync was used on an idle system.
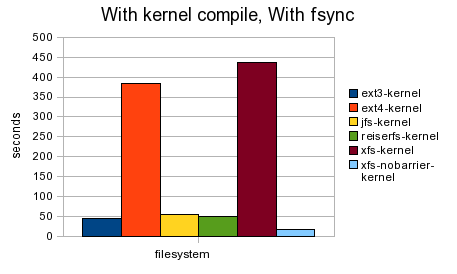
The big stand out is that if fsync was used both ext4 and XFS were much slower. Both of these filesystems enable barriers by default. Note that the time is in seconds so there is a huge difference in the run-time when fsync is turned on.
The next tests were to determine how the number of bytes written to the file each iteration and the number of rename() iterations performed changed the time required to run the benchmark.
The graph shown below varies the number of times rename() is called and the number of bytes written. When rename is called 10,000 times only one lot of 16,000 bytes is written to the file each iteration. When rename() is called only once, 10,000 lots of 16,000 bytes are written to the file. The benchmark is meant to determine how performance is effected when writing larger files less frequently. As you can see there isn’t much of a difference for the benchmark with fsync is not called as shown in the below graph.
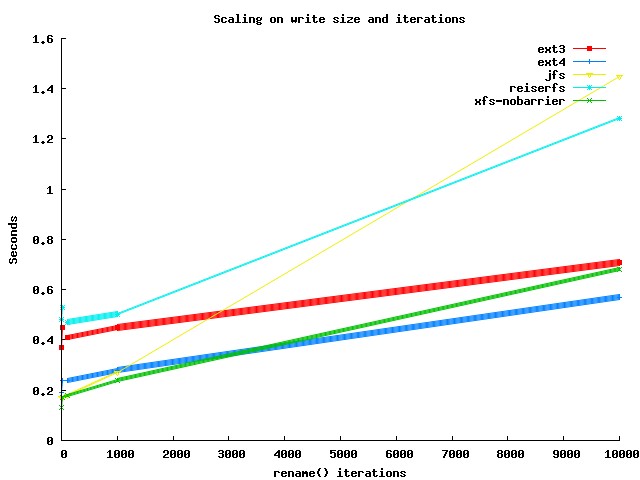
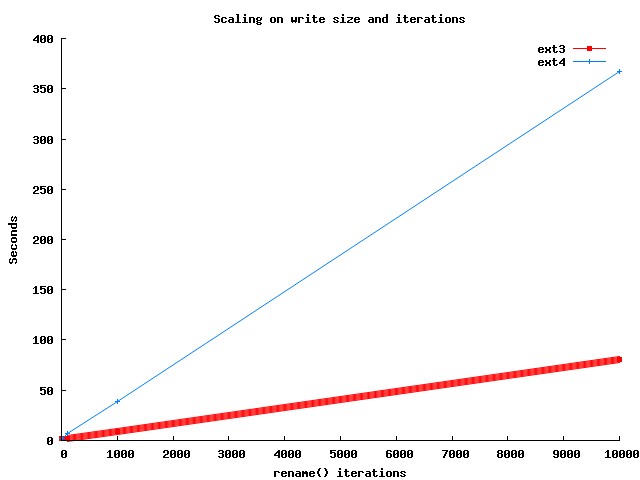
Once you turn on fsync things change dramatically. Because there is such a difference in performance, the below graph shows just ext3 and ext4 for the same test as shown above.
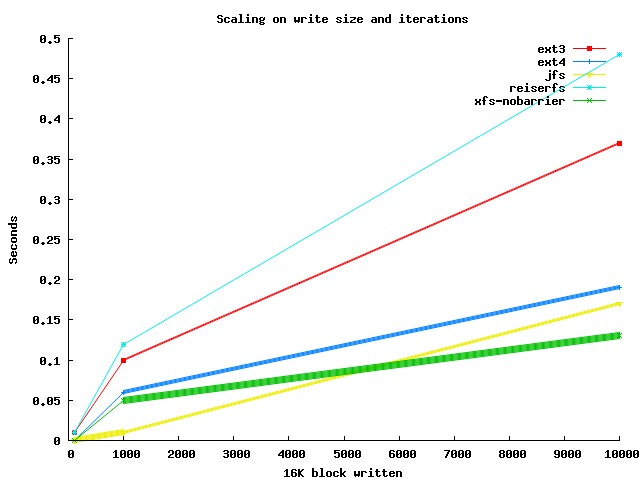
The graph shown below is still not using fsync and shows how performance changes when using only a single rename() call but dropping the amount of data from 10,000 to 100 lots of 16,000 bytes. As you would expect there is little difference in time when fsync is not used.
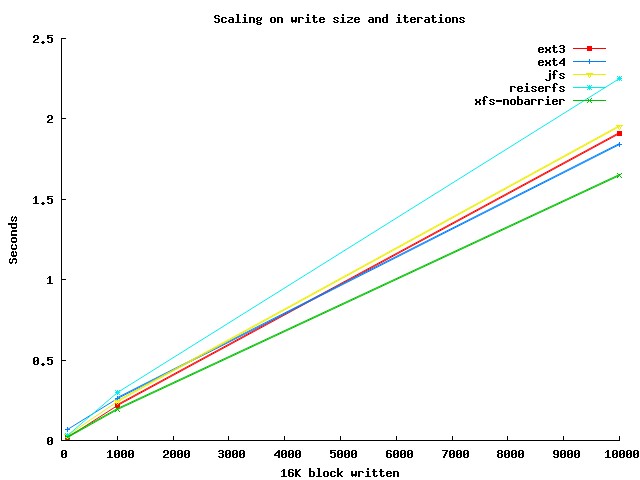
As you would expect, when turning fsync on the graph for a single rename() rises as the number of bytes written to the new file does.
Future Ideas and More Testing
The use of block level barriers seems to hit ext4 and XFS very hard for some of the tests, so moving the journal onto an SSD should help to level the play field again. Given the rapidly dropping cost of SSDs, performing these tests using a single fast small SLC SSD to store the filesystem journal would be quite interesting. Especially since a single sub-$200 SSD could service the journal of many filesystems on a single server machine.
The background kernel compilation was run with a nice priority. This meant for some tests the compilation would be slowed down or halted at times waiting for the filesystem. It would be interesting to perform similar tests and record the number of source files compiled during each test. I found that there is quite a bit of variation but did not alter the kernel compile loop to record the exact figures. In particular operations like make clean performed before a second kernel compilation is performed were very slow on XFS with barrier as it was running at a nice priority and has many metadata operations.


