
Author: Brian Jones
understand the motivations for moving to LDAP, and you should already have an OpenLDAP server up and running
(covered in Part
I). This time, we’ll discuss the LDAP data model, and how to apply it to
your environment.
Understanding LDAP Data
LDAP is a protocol for interacting with data. The way the LDAP views data is as
a hierarchical collection of objects, each of which has one or more
attributes. This view of the data works well in many environments,
because most environments store facts (or attributes) about people, places, or
things (objects). Furthermore, these objects generally fall under some sort of
top-level managerial or human resources domain, like “accounting,” “legal,” or
“inventory.” But how do we map this theoretical babble to something that
can actually be understood by LDAP? How do we tell LDAP that “Tom” is a person,
and how do we tell our systems how to grab Tom’s password attribute?
The answer lies in schemas. We touched on schema files in our
last article during the configuration of our OpenLDAP server. Schema files are
imported by the slapd process at startup, and they define which objects are
supported by the LDAP directory. The OpenLDAP tarball you unpacked in our last discussion includes many of the most popular and useful schemas, so you won’t have to grep the entire Internet to find what you’re looking for. Just cd /etc/openldap/schema and you can peruse some of the schemas available. No matter what problem you’re trying to get LDAP to solve, there is probably already a schema
available tailored to the task.
To get a taste of how schemas work, let’s
have a look at just one object definition. This one from the standard
nis.schema file, which comes with OpenLDAP:
objectclass ( 1.3.6.1.1.1.2.0 NAME 'posixAccount' SUP top AUXILIARY
DESC 'Abstraction of an account with POSIX attributes'
MUST ( cn $ uid $ uidNumber $ gidNumber $ homeDirectory )
MAY ( userPassword $ loginShell $ gecos $ description )
)
This is the object definition of the posixAccount object. If you include
nis.schema in your slapd.conf file, then you can define objects of this type
to store in your directory, which we’ll do in a minute. First let’s understand
what this object definition is telling us.
The DESC line is self explanatory, and sometimes isn’t as helpful as you
might like. The MUST line
consists of a list (separated by dollar signs) of required attributes that every
posixAccount object must have associated with it. The MAY line is a similar list, but these attributes are all optional, or allowed.
Do not discount the part of this block that says SUP top AUXILIARY. This
is actually a crucial part of the object’s definition, which we’ll come back to
when we have a better context to put that information in. For now, we know that
if we use nis.schema and define a posixAccount object, that object must
have, for example, a homeDirectory. But how do we know what a homeDirectory
is supposed to look like? Well, we can look at the homeDirectory attribute
definition (also from the nis.schema file), which will give us a clue:
attributetype ( 1.3.6.1.1.1.1.3 NAME 'homeDirectory'
DESC 'The absolute path to the home directory'
EQUALITY caseExactIA5Match
SYNTAX 1.3.6.1.4.1.1466.115.121.1.26 SINGLE-VALUE )
The DESC line tells most *nix administrators all they need to know. A
homeDirectory attribute is in the form of an absolute path to the home
directory of that particular posixAccount.
Blowing the cover
The simple truth, in practice, is that the purpose of the posixAccount object
type is to store information about accounts that is typically found in an
/etc/passwd file, or a NIS passwd map. The two are very similar. If you
work with either of these account storage mechanisms, then most of these
objects and attributes mean exactly what you think they should mean.
For now, you should understand that each entry in an LDAP directory is
considered an object. Each object has one or more attributes. The objects and attributes that will be understood by your directory are defined in
schema files, which are simple text files created
to allow admins like us can get real work done with a minimum of hassle.
LDAP data migration: Laying the (hierarchical) foundation
Importing data from files or NIS to LDAP requires that you extract the data and
transform it into a format called LDAP Data Interchange Format that can be readily understood by your LDAP directory. LDIF is easy to
understand and work with, and there are tools available to automate the
transformation. In addition, it’s easy enough to use that I generally script my
own transformation routines, and I’m not really known for my coding
abilities.
The first bit of LDIF we need to write and import into our directory server
should define some hierarchy for the rest of our objects to sit under. There is
more than one way to structure this, but the most popular method nowadays (at
least for new deployments) is the domainComponent model. In most cases, this
model maps the parts of your DNS domain (e.g. linuxlaboratory.org) to separate
domain components (e.g. dc=linuxlaboratory,dc=org). This new object becomes the
top-level of your directory server.
Here’s the LDIF for my test directory’s top-level object:
dn: dc=linuxlaboratory,dc=org
objectClass: top
objectClass: dcObject
objectClass: organization
o: LinuxLaboratory
dc: linuxlaboratory.org
description: Your Source for (more) Advanced Linux Knowledge
In the first line of this entry, “dn” stands for Distinguished Name. Every object in your
directory, no matter what type of object it is, is uniquely identified by
the value of this attribute. In fact, your LDAP directory will throw an error
if you try to import two objects that have the same value for dn.
Notice that this object has three
objectClass lines. That’s because I want to take advantage of an attribute
I’m allowed to use with the “organization” object that I’m not
allowed to use with the “dcObject” object: namely, the “description” attribute.
It’s okay to combine object types to take advantage of different attributes
allowed by each one, provided you follow the rules. Those rules harken back to the first line of the objectClass definitions we looked at earlier. Remember when I said not to discount the part that said SUP top AUXILIARY? Here’s where that can make or break your directory design.
Aside from “AUXILIARY,” an object can also be described as being “STRUCTURAL.” There are other types as well, but these are the two most prevalent.
In addition, each object definition lists its superior, as noted by the “SUP
top” in the earlier posixAccount definition. “top” is the highest-level
object, but objects can have other objects as their superiors. For
every entry, there can be one and only one “SUP top STRUCTURAL” objectClass
used to define it. The rest must be AUXILIARY, or STRUCTURAL objects with a
different superior object. In this example, “organization” is the only
STRUCTURAL objectClass, and dcObject is AUXILIARY. But take a look at this
string of objectClasses, taken from an account entry we’ll se a bit later:
objectClass: top
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: inetLocalMailRecipient
objectClass: shadowAccount
The objects organizationalPerson, person, and inetOrgPerson are all
STRUCTURAL. The reason this works is that, in short, this string forms a proper
“chain of superiors,” as I like to call it. The person object’s superior is the top-level “top,” and it is STRUCTURAL.
organizationalPerson is STRUCTURAL, but its SUP is person. inetOrgPerson
is also STRUCTURAL, but its SUP is organizationalPerson. The rest of the
objectClasses listed are AUXILIARY (which I think of as supplementary). Since
I do not have any two STRUCTURAL objectClasses listed with the same SUP object,
the chain is never broken.
To be clear, if I went back and added another
objectClass to this list which was A) STRUCTURAL, and B) had the same SUP as
another already-listed STRUCTURAL object, I would break my design. This constraint
was not strictly enforced in earlier versions of OpenLDAP, but later versions,
as they strive to conform to the LDAPv3 spec, have begun throwing errors for
bad design. In the long run, good design saves more headaches than
conforming to good design causes.
More on page 2…
More data: Branching out
With my top-level entry out of the way, it’s time to think about how I want to
divide up the entities within my organization. Without a doubt, I know that I
want to keep track of users and groups on my systems. You may decide you
want to keep track of hosts, mount maps, and NIS netgroups as well.
However, these entities have among them a logical separation, so it would
be nice to be able to look for, say, people under a People subtree, groups
under a Group subtree, and so on. This is traditionally done by creating what
are called organizationalUnit or “ou” objects, under which sit the subjects of
that organizationalUnit.
For now, I’m going to keep things simple and create only People and Groups trees, with an entry or two under each tree. Here’s some more LDIF:
dn: ou=People,dc=linuxlaboratory,dc=org
ou: People
objectClass: top
objectClass: organizationalUnit
description: Parent object of all UNIX accounts
dn: ou=Groups,dc=linuxlaboratory,dc=org
ou: Groups
objectClass: top
objectClass: organizationalUnit
description: Parent object of all UNIX groups
dn: cn=jonesy,ou=People,dc=linuxlaboratory,dc=org
objectClass: top
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: inetLocalMailRecipient
objectClass: shadowAccount
uid: jonesy
sn: Jones
givenName: Brian
cn: jonesy
userPassword:: p455^/0rD
loginShell: /bin/bash
uidNumber: 12
gidNumber: 12
homeDirectory: /home/jonesy
gecos: Brian K. Jones,IT,434,x231
mail: jonesy@linuxlaboratory.org
roomNumber: 434
telephoneNumber: x231
labeledURI: http://www.linuxlaboratory.org
description: All-around good guy
homePostalAddress: NONE
displayName: Brian K. Jones
homePhone: 000-000-0000
title: Chief
dn: cn=cartman,ou=People,dc=linuxlaboratory,dc=org
objectClass: top
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: inetLocalMailRecipient
objectClass: shadowAccount
uid: cartman
sn: Cartman
givenName: Eric
cn: cartman
userPassword:: c4r7m@n!
loginShell: /bin/pdksh
uidNumber: 13
gidNumber: 12
homeDirectory: /home/cartman
gecos: Eric Cartman,IT,433,x233
mail: cartman@linuxlaboratory.org
roomNumber: 433
telephoneNumber: x233
labeledURI: http://www.linuxlaboratory.org
description: Round
homePostalAddress: NONE
displayName: Eric Cartman
homePhone: 000-000-0000
title: worker bee
dn: cn=staff,ou=Groups,dc=linuxlaboratory,dc=org
objectClass: posixGroup
objectClass: top
cn: staff
gidNumber: 12
memberUid: jonesy
memberUid: cartman
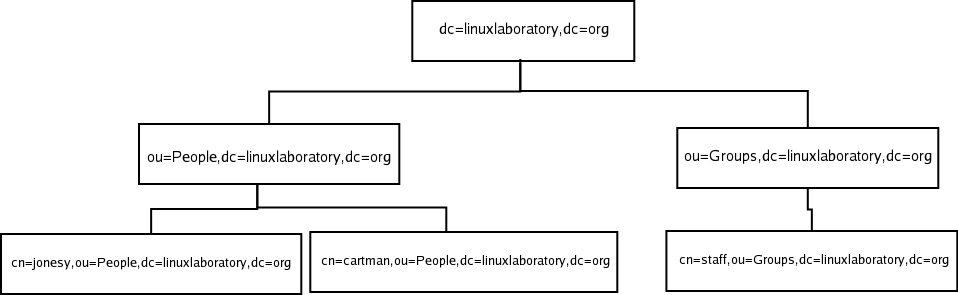
At this point, though we haven’t done an actual import yet, we have designed an LDAP directory that can
be drawn on paper, and it would look something like the figure in diagram
1.
How’d you do that?
How did that mass of LDIF magically appear? I started (in the case of
the jonesy account) with an NIS map entry just like this one:
jonesy:p455^/0rD:12:12:Brian K. Jones,IT,434,x231:/home/jonesy:/bin/bash
Then:
- Map the NIS map fields to actual LDAP attributes
- Figure out the objectclasses needed to support those attributes
- Figure out any additional attributes you’d like to keep track of that your
current scheme lacks, and which objectclasses are needed for those attributes - Write up a quick sample LDIF account entry, and test an import
- Automate, automate, automate!
In the LDIF I’ve presented, all of the NIS map fields map to attributes of
the posixAccount object. Since I plan to employ some things in the future like password aging and
expiration, I’ve also employed the shadowAccount class. It’s
currently unused, but this keeps me from having to add it to the users’ account
entries later. This foresight can potentially save gobs of time.
Some of the other account attributes, like room, mail, and telephoneNumber, are attributes that come from one or more of the other objectclasses used to define the entry. They can be used by application developers creating an online
directory, and even by existing email clients like evolution or pine, which can be configured to perform email address auto-completion based on a search of the mail attributes under the People tree. Just remember to make sure your objectclasses don’t form a clash.
Implementing the Design: Importation
Our final trick is to
import the LDIF we’ve created. At this point I assume you have a running slapd
server. Make sure that
your slapd.conf file includes the core, cosine, inetorgperson, misc, and nis schema files. For the purposes of this example, I’ll also assume your LDIF is stored in a file called my.ldif in your current working directory. Last but not
least, I assume you’ve followed my slapd.conf example from our last article and
used cn=Manager as your administrative user in slapd.conf, and that you’ve assigned (and remember) the password for this user.
With this in mind, the command to import your data into a running LDAP server is:
[jonesy@livid ~]$ ldapadd -x -W -D'cn=Manager,dc=linuxlaboratory,dc=org' -f my.ldif -c
You can find a quick explanation of the command’s flags by running ldapadd by itself. The ones I’ve used here are:
-c: This means don’t die on every error; list errors,
but continue and add those entries that did not contain errors-x: use simple authentication-W: prompt for the bind password-f filename: get entries from filename-D'binddn: Bind using binddn — essentially a username
expressed in LDAP’s language, using the full dn. For admin functions, this will
be the rootdn you specified in your slapd.conf file.
In closing
Don’t get frustrated if you get errors on your first import. Take a deep breath. Check your slapd.conf file. Make sure you’re importing the correct schemas. And make sure your rootdn and password are right. If you’ve made changes
to slapd.conf, remember that slapd needs to be restarted in order to see the changes. When all else fails, I’ve had tremendous success with simply pasting the errors into the Google search box and clicking Go. Usually, data import
errors are minor flubs in configuration or a typo in your LDIF.
In the next edition, we’ll look at the automation end of things, and add some
really helpful tools to your directory administration toolbox. We’ll also use
those tools to start poking at our directory server and have some fun.



{kind=link}