
Author: Corrado Cau
To begin, we need the annoyance-filter executable, a trained dictionary (and the related binary-only fast dictionary), and a little bash script that should look like this:
#!/bin/bash
# af-T-TP2
#
# To be used as a pipe-thru stdin-stdout for KMail filter 'pipe through'.
#
# Test the classification (Junk or Mail or Indeterminate) of the mail message
# received from stdin, adding the relevant X-Annoyance Filter msg headers.
#
# 'af' is a symlink in /usr/local/bin pointing to ~/.annoyance-filter/annoyance-filter
# 'FastDict.bin' is a symlink pointing to ~/.annoyance-filter/FastDict.bin
#
af --fread /usr/local/bin/FastDict.bin --phrasemin 1 --phrasemax 2 --transcript - --test -
Copy this script to /usr/local/bin/af-T-TP2 (or whatever name you see fit), run chmod to make it executable, and grant read/execute permissions to it for the user(s).
The script reads an e-mail from stdin (‘–test -‘), classifies it as either ‘Junk’, ‘Mail,’ or ‘Indeterminate,’ and writes it to stdout (‘–transcript -‘), with two new X-headers added:
X-Annoyance Filter-Junk-Probability: 0 (between 0 and 1; Mail 0.9)
X-Annoyance Filter-Classification: Mail (Junk, Mail or Indeterminate)
By default, whatever scores below 0.9 is mail and whatever scores over 0.9 is junk; thus there is no possibility of getting an ‘Indeterminate’ status, unless we purposely leave a gap between the ‘–treshmail’ and the ‘–treshjunk’ options and explicitly specify them when invoking Annoyance Filter.
Most of our e-mails will receive a Junk-Probability of 0 if acceptable, and 1 if junk; with a good dictionary it’s unlikely you’ll see intermediate probabilities between 0 and 1, even though it’s a possibility. But we don’t really have to look at that X-header line. Our best bet is to evaluate the Classification X-header; thus inside KMail we’ll simply check for its value being either ‘Junk’ or ‘Mail.’
By the way, don’t worry about spammers embedding an ‘X-Annoyance Filter-Classification: Mail’ header in their junk mailings. Annoyance Filter automatically discards pre-existing classifications (deeming them spoofed headers) and starts a new classification afresh.
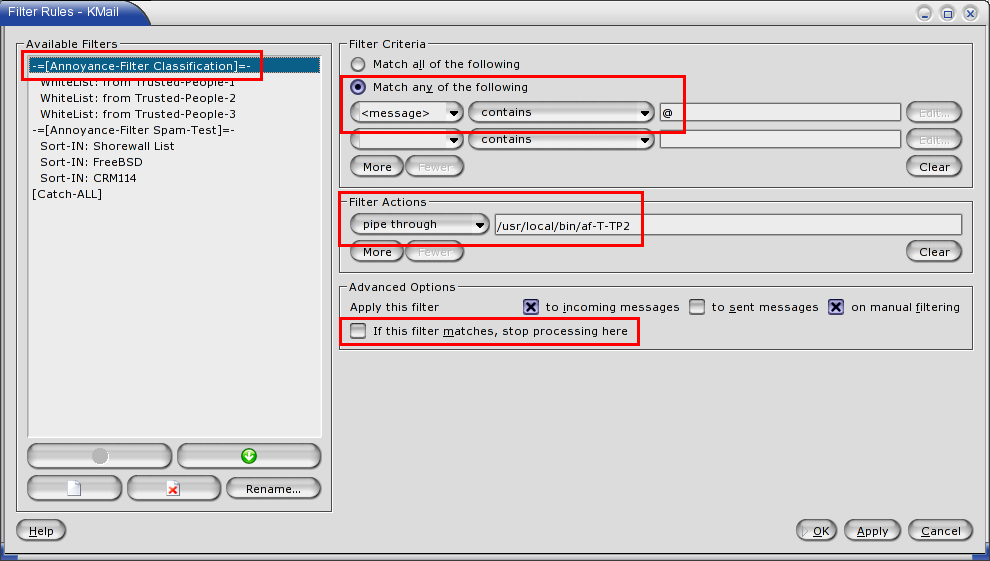
Now that we’ve created our bash script, we’ll fire up KMail and create a new mail folder called ‘Junk-Mail.’ Then from the KMail menu we choose Settings/Configure Filters and add rule-based filters organized as follow:
1. Annoyance Filter classification (af-T-TP2): must be applied to every incoming e-mail message. Checking for an @-sign in a message is a trick for being sure they all are processed.
(Click on images to enlarge them.)
2. White-Lists: we need a safety net, a set of filters for people or content we can’t afford to lose, whatever the Annoyance Filter classification will be. This is called ‘whitelisting.’
3. Spam-Filter: check for the presence of ‘X-Annoyance Filter-Classification: Junk,’ move the message to the Junk-Mail folder, and stop processing subsequent filter rules.
4. If desired, move any message not intercepted by the Spam-Filter step to an appropriate folder based on other filter criteria.
That’s all, folks. From here on, every message will be appropriately classified by Annoyance Filter and spam will be moved to the Junk-Mail folder automatically. As a general rule, always move the alleged spam messages to a folder; don’t nuke them. That way you can (and should) verify that no legitimate messages ended up in the junk folder. In the process, you’ll also collect a personal junk collection, good for training your next spam filter.
I’ve put together a utilities tarball you can download that includes a pre-built dictionary — spam only, you’ll need to add training for your own legitimate mails — and a bunch of scripts for simplifying your Annoyance Filter experience.
Enjoy.
Corrado Cau has worked in the IT field for 15 years and spent most of his career as a system and network administrator on many platforms.
Category:
- Enterprise Applications



{kind=link}