
The Cloud today seems a bit like Dawson City in 1896 when the Klondike Gold Rush was about to get underway. Everybody is talking about the Cloud, and many want a piece of the action. The Open Source world has been abuzz with OpenStack in particular, with some going so far as to call it “the new Linux”.
![]()
Unfortunately, Cloud has been saddled up with some serious marketing-babble baggage, and OpenStack is hard to immediately relate to. Even the technically savvy computer user could be forgiven for wondering, “what is everybody talking about!?!” This article will help you understand the relationship between your Linux distribution and an OpenStack Cloud.
Software Computers
First things first, let’s ditch the capital “C” and some of the marketing. OpenStack bills itself as “a cloud operating system for data centers.” What does that mean? The National Institute of Standards and Technology puts it like this: “cloud computing is a model for enabling… on-demand… access to a shared pool of… computing resources… that can be rapidly provisioned and released with minimal management effort or service provider interaction.” OpenStack does that;the orchestration of pools of computing resources to do stuff.
If you are anything like me, your pool of computing resources is maybe a laptop, a little fileserver, and a desktop computer. In other words, a far cry from a data center. However, your Linux computers do have something in common with some data centers: KVM, the kernel-based virtual machine.
In 2007, a module was added to the Linux kernel that turned every Linux PC with the right hardware into a computer capable of running other computers, a hypervisor. Computers running software computers is called virtualization. For many Linux users, this meant being able to boot a Windows virtual machine from within their Linux distribution so they could run Quicken.
KVM to the Rescue
For businesses, KVM meant the end of single purpose hardware. Instead of having a server that did one thing, and sat idle when it wasn’t doing that one thing, a virtual machine running on a server could do the thing. When the virtual machine wasn’t doing the thing, its resources could be used by other virtual machines doing other things. So KVM was good for you, because it let you try out other Linux distributions and use Outlook without rebooting. KVM was good for businesses because it meant they could use their hardware more effectively.
Is that the cloud? No. But virtualization provided by the KVM hypervisor is a key cloud building block.
One of the ways that the cloud impacts you directly is through the web services you consume. This article was written using Google Docs while listening to music on SoundCloud. I used computing resources from shared pool, and released them with minimal service provider interaction. Neither of these service providers use OpenStack, but mentioning them helps answer a question: “What is the point of the cloud?”
The point of a hypervisor is virtual machines. Software computers have all of the benefits of hardware computers, and some bonuses. If a virtual machine has problems, there is almost no cost to throwing it away and replacing it with an exact copy of itself. Complex configurations of multiple computers are simpler to implement. KVM works with libvirt, and other Open Source projects like oVirt, to provide user friendly management interfaces for virtual machines. But even these enhanced KVM consumers are not the cloud, because the KVM hypervisor is all about virtual machines.
Gateway to the OpenStack Cloud
So what does KVM have to do with OpenStack? Virtual machines are the simplest route to the cloud. OpenStack can use a KVM hypervisor to provision virtual machines. For Openstack though, the point is no longer virtual machines, but rather what they can be used for. A virtual machine is a way of applying computing resources to a task. OpenStack is a collection of services that are used to apply computing resources from a pool to a task, and return them to the pool when the task is complete. The point of an OpenStack cloud is to automate the allocation of computing resources to temporally bound, distributed computing tasks.
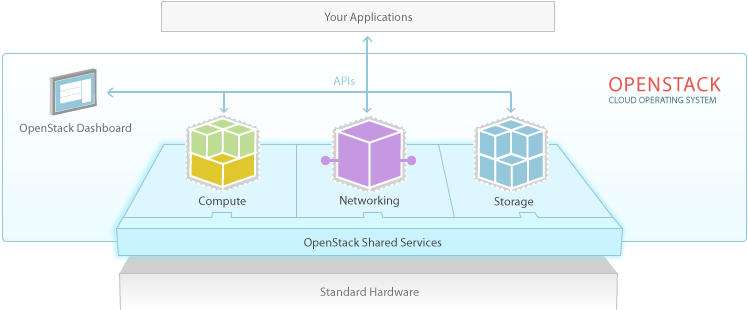
OpenStack use and improvement has been driven, like many things in the world of software, by developers. Before the cloud model of computing became prevalent, software was written mostly to be run on a single computer. The ability for a software program to scale on-demand was often added after the fact. Development of software that runs in a cloud environment like OpenStack is different, in that it presumes scalability. Developers can use the OpenStack application programming interfaces (APIs) to consume the OpenStack services as they are required. Virtual machines, storage resources, and networking are all represented in the APIs, and are added and removed to a computing task as usage demands.
Developers use OpenStack to deploy their software. End users use OpenStack by consuming software that is deployed on it. That could be a corporate web application like webmail, or a service that processes database requests. If everyone in the office logs on and checks their email first thing in the morning, OpenStack calls up more virtual machine instances on KVM hypervisors to provide additional computing power to make sure that everyone gets the reminder that their TPS reports are due.
And now you know what you, the Linux user, and OpenStack, the cloud operating system, have in common: the KVM hypervisor.


