
By Ben Martin¬â€
Without going into details, SSDs may use single-level cell (SLC) or multi-level cell storage, with SLC drives typically offering better performance.
SSDs offer different read and write speeds, form factors, and capacity. I looked at several models from Mtron. The performance of the 3.5-inch and 2.5-inch form factors is identical, so you might as well get the 2.5-inch drive because you can use it inside laptops as well as desktop machines. Mtron’s Imation-branded drives use the MOBI brand for lower-end “personal” drives and PRO branding for the professional (faster) drive. The professional drive is reported to be about 10% faster in write and 20% better in read performance. The reported seek time is identical.
I used a 32GB 2.5-inch MOBI drive for these tests. Although the professional drive is slightly faster for transfers, it is also about 25-35% more expensive. Because the following tests focus on seek time, you can extrapolate a 10-20% difference to get an idea of the speed of the professional drive.
The 32GB SSD currently costs around $500. By contrast, a 750GB SATA drive can be had for about $130, which means that you can have about 2TB of usable conventional hard disk “spinning storage,” or about 60 times as much space as the SSD, protected against a single disk failure in a RAID-5, for the same price as the 32GB SSD.
Performance
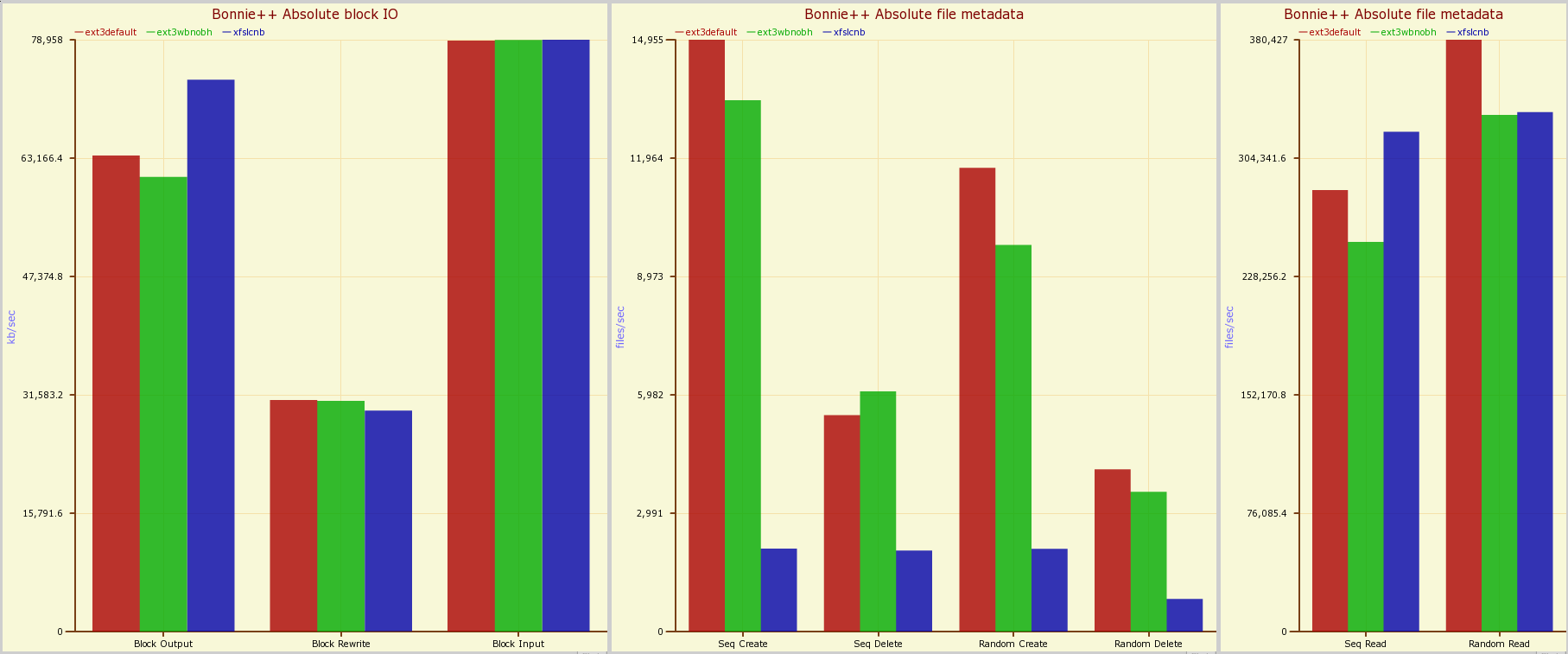
I measured the performance of the SDD with Bonnie++, using the XFS and ext3 filesystems. For comparison I included results of the same tests against 750GB drives both in a single drive and six-drive parity RAID. I performed the tests on a 2.2GHz AMD X2 with the SSD mounted in an external enclosure and connected via eSATA.
For testing with Bonnie++, I used the ext3 filesystem with no extra parameters to mkfs.ext3 and no additional mount parameters as ext3default. I created the ext3wbnobh filesystem with default parameters but mounted with the data=writeback,nobh options. The writeback option provides a little more throughput at the expense of a change in semantics when the power is suddenly cut. The default journaling mode for data is ordered, which forces file data to be written to the main filesystem before its metadata is updated. Using writeback, the data might be written to the filesystem before or after the metadata, so after a crash or power failure you might see the old file data with the new file metadata. Both the ordered and writeback methods guarantee internal filesystem integrity.
The nobh option is described in ext3.txt in the kernel distribution as relating to the association of buffer heads to data pages. Without digging into the kernel side details, the final line in ext3.txt mentions that nobh is supported only for writeback mode, which we are using, and thus the nobh option too.
For testing the XFS filesystem I used the -l lazy-count=1 parameter at filesystem creation time, and the filesystem was mounted with the nobarrier option. Setting lazy-count option to 1 when creating an XFS filesystem allows the filesystem to keep some counter information distributed throughout the filesystem rather than all in the superblock. If you keep all of this information in the superblock, then updating the superblock itself can slow down metadata operations.
When you mount an XFS filesystem it will try to use disk barriers to flush the filesystem journal out to disk at the end of a transaction. This can have a large impact on the performance of the filesystem when it is performing operations that use the journal, such as file creation and deletion. The nobarrier mount option for XFS filesystems disables the forced flushing of the journal to disk. If you are using the XFS filesystem in an environment where power is not going to be unexpectedly dropped, using nobarrier will improve performance without the risk of partial journal transitions.
I made an attempt to benchmark with barriers enabled, but I stopped the benchmark during the extended file metadata (creation, stat and delete) tests because it was taking too long. I report the XFS result as xfslcnb because of lazy-count and nobarrier. Looking at the amount of disk activity, it seemed that enabling barriers on XFS made the file metadata tests run at about 1/10 the speed.
The block throughput and file metadata operation graphs are shown below. XFS is a little bit slower at performing metadata operations than other filesystems, so it is not surprising that XFS does not match ext3 for metadata operations like file creation and deletion, but it does hold a significant advantage for block output.
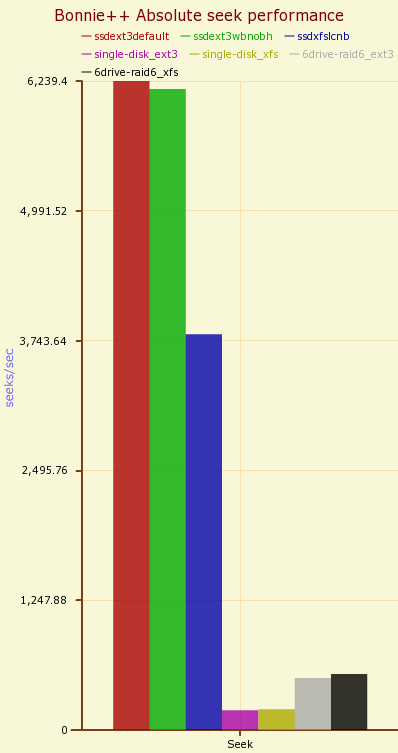
The random seeks were about 6,200/second for ext3 and 3,800/second for XFS on the SSD. To put this into perspective, the graph shown below contains the seek performance for the SSD, a single 750GB SATA drive, and six 750GB SATA drives in RAID-6. Notice that having six hard disks does improve seek performance noticeably over a single hard disk, but the single SSD still dominates the graph. This advantage in seek time explains why systems equipped with a SSD drive can boot significantly faster than those without. Booting a machine or loading a complex application normally calls for thousands of files to be read, and these are normally scattered over a disk platter, causing many seeks. Because the SSD has such an advantage in seek time, it can show with an overall improvement measured in seconds to load a very large application.
The final graph shows the block read, write and rewrite performance of the SSD against a single 750GB disk and a RAID-6 of six 750GB SATA drives. There isn’t a great deal of difference between the block transfer performance of a single 750GB SATA drive and the SSD. The RAID-6 of 750GB conventional hard drives is significantly faster across the board.
The point of the previous comparison on block transfer is to show the gap between the block IO performance you would get if you spent the same money on conventional hard drives instead of the SSD. The SSD has a dominating advantage in seek time, yet its overall capacity is a slight fraction of what you can get by buying conventional hard drives, and hard drives in RAID dominate the SSD in terms of block transfer speeds.
IOzone
Because an SSD is based on flash storage rather than a conventional spinning disk platter, the Bonnie++ benchmarks do not tell the whole story. IOzone allows you to see how the disk performs for a range of file sizes and record sizes. When this information is shown graphically you can quickly see if there are areas where the disk underperforms.
Shown below is the read performance of IOzone on a single 3.5-inch 750GB Samsung SATA hard disk using the XFS filesystem. Notice that the disk performs better when reading smaller records, with the larger read sizes forming a relatively flat plateau in the back of the graph. Once the file size gets too large (to the right of the graph) then performance across the board drops off.
Shown below is the IOzone read performance of the SSD using the XFS filesystem. The most striking feature in the graph is that the little ridge formed across the front of the graph for the higher-performing smaller record sizes is a different, steeper shape for the SSD. The SSD gives lower overall performance for larger record sizes when reading and tapers off much faster. While 128KB record sizes on the SSD run at 90% the speed that they would have on the 750GB hard disk, when you move to 256KB records the SSD only offers about 70% the read speed of the hard disk.
I also ran IOzone with the SSD formatted with the ext3 filesystem, because many Linux users use ext3 instead of XFS. Shown below is the IOzone read performance for the SSD. The sharp drop in performance when using larger record sizes is still present. Oddly, there is a clearly defined area where performance is poor for 512KB file size, forming a trough right across the higher-performing 64KB and less record read size. Because this trough degrades smoothly on either side, it is probably not caused by a burst of load placed on the system or issue other than the system just not liking this record size for ext3 on this SSD.
The differences in write performance are most accurately shown in the fwrite IOzone test, for which the two graphs are shown below. The same ridge exists across the graph from far left to far right on both graphs, but in the SSD graph the slight ridge that runs along the bottom of the graph is more compact, with steeper drops on either side of the 128KB record size. This indicates that for the SSD it would be a great idea to tune applications to issue their writes in sizes of 128KB or less for maximum performance. For example, you could set up the size of data that a database uses as its index page size to be 128KB or less.
You may have noticed from the scale that of the vertical axis that the graph for the conventional hard disk has a higher throughput reading. While this may lead you to the conclusion that a single hard disk is faster than this SSD for transfers, you should keep in mind that the hard disk is a 3.5-inch 7,200 RPM drive. If you are thinking of using this SSD in a laptop, comparisons of the SSD against most 2.5-inch hard disks should favour the SSD for transfer speeds.




{kind=link}
{kind=link}