
While there’s many exciting features to Linux 3.13, there’s still some features that you won’t find in this next major Linux kernel update…
Read more at Phoronix

Following my recent post on the initiatives now in place to rebalance the demographics of the Linux Kernel community, I would like to share a set of specific training activities to get beginners, specifically college students, involved in the kernel.
These were created by an enthusiastic group at Red Hat, including Matthew Whitehead and Priti Kumar, and unfolded on campus at Rensselaer Polytechnic Institute, Rensselaer Center for Open Source (RCOS), and State University of New York at Albany.
I made a joke recently on social media — not a good joke, I’ll be the first to admit — that I had used Korora way back when it had two A’s at the end.
In an indirect way, Korora — minus the second A of the past, but inheriting the long-vowel line over the last A — crossed the proverbial radar again recently and, as it would happen, it got another one-week test drive from yours truly, this time in the driver’s seat of Korora 19.1 KDE “Bruce.”
In a word, “Wow.”
For those of you keeping score at home, Korora is a Fedora remix that “aims to make Linux easier for new users, while still being useful for experts.” It’s a noble effort, to say the least: Fedora, which as I’ve said on a million occasions, does everything right, especially building and maintaining the distro’s software, as well as building or maintaining the community supporting it. The principles driving Fedora are excellent ones to emulate, and to provide an option of a Fedora respin in which everything works right out of the box (*cough* Flash *cough*) is indeed a noble task.
So in taking that route, it bears mentioning that the Korora lead developer, Chris Smart, is a man who lives up to his name.
As many of you know, I’m not stranger to Fedora, yet I threw caution to the wind and opted for KDE, given Korora’s choice of KDE, GNOME, Cinnamon and MATE. Here’s why: First, I haven’t used KDE in quite awhile and I wanted to see what’s new, and secondly, my friend Ken Starks at REGLUE is using it in the OpenSUSE machines he’s building for kids down in Austin, Texas.
On a Dell Latitude D610 with the touchpad turned off in the BIOS (due to the wandering cursor thing that Dell refuses to fix — which is why someone gave this hardware to me, I think), the install went flawlessly and any worry that the 1.5GB of RAM would labor under the weight of KDE was put to rest early. For the week I used the D610 on a daily basis, the only hiccup was in updating which, eventually, was traced back to the flaky wireless where I was rather than to the distro and/or desktop environment.
Other hurdles aside — “Why doesn’t apt-get work on this . . . oh wait.” — getting used to KDE was not as hard as I thought. Much of the habits in using a window-manager based distro like CrunchBang took some unlearning. KDE and I have always had a love-hate relationship, but casting aside any prejudices I had about the desktop environment, I found that the same things that bothered me still do (KDE Wallet – seriously?), but the other facets of KDE Plasma were very workable and spending an entire week tweaking it was both educational and fun. Plus, I think there have been many improvements to much of the KDE software lineup: Using Kmail and Konversation much of the time, they performed flawlessly during the course of the week.
On the whole, I like this distro a lot and I think Korora has a bright future. There is a clear comparison that can be made between Korora and Fedora that mirrors the relationship between Linux Mint and Ubuntu. Just as Linux Mint improves the user experience on that particular Ubuntu-based distro, so then can Korora enhance the user experience on this Fedora-based distro.
Trivial, I know: The naming convention is based on characters in “Finding Nemo” in the same way that Debian’s project names are based on “Toy Story” (or CrunchBang’s is based on “The Muppet Show”). It’s always a source of interest to me how projects are named, and you just have to bear with me on that. But a tip of the hat to Nemo!
So a word of warning, Kororans: I’ve signed up on your site and I’m going to keep Korora on the Dell for the forseeable future. See you around.
I promised last week to look at VSIDO and we’ll have to take that up next week. Apologies to those who were expecting that today.
 This blog, and all other blogs by Larry the Free Software Guy, Larry the CrunchBang Guy and Larry Cafiero, are licensed under the Creative Commons Attribution-NonCommercial-NoDerivs CC BY-NC-ND license. In short, this license allows others to download this work and share it with others as long as they credit me as the author, but others can’t change it in any way or use it commercially.
This blog, and all other blogs by Larry the Free Software Guy, Larry the CrunchBang Guy and Larry Cafiero, are licensed under the Creative Commons Attribution-NonCommercial-NoDerivs CC BY-NC-ND license. In short, this license allows others to download this work and share it with others as long as they credit me as the author, but others can’t change it in any way or use it commercially.
(Larry Cafiero is one of the founders of the Lindependence Project and develops business software at Redwood Digital Research, a consultancy that provides FOSS solutions in the small business and home office environment.)
![]()
![]()





















![]()


Our openSUSE Summit 2013 has just finished here in Orlando. We were hosted in a Mexican themed hotel in the area of Disney World, with our own special area setup nicely for our presentations and workshops. The location was a nice new touch for the geeko friends to reconnect and collaborate, if only because there was a large number of lizards all around here!
Weather wasn’t very loving down here in Florida, USA but being in such a family-like get together, it didn’t really matter.
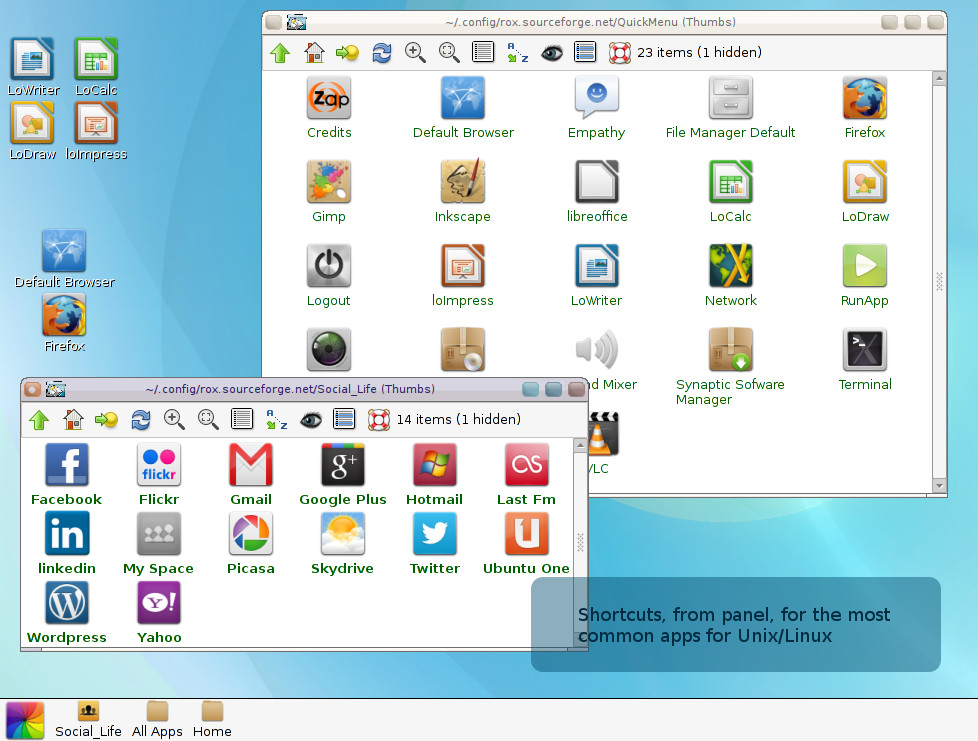
Based on ancient Rox and Window Manager fluxbox . Zappwm is a desktop that consumes only 39MB and offers an environment with drag’n drop very simple and practical .
Currently in version 4.2 , includes the addition of 10 wallpapers, screen corners rounded , links to cloud computing and three main inputs for applications that resemble the interfaces for smartphones :
Social Life – Shortcuts to social networks and cloud computing .
All Apps- shortcuts for all graphics applications .
Home- Personal Folder .
The desktop configuration is very simple , though limited to wallpaper . Just click with the right mouse button and choose Backdrop > Show. Then drag your wallpaper it will be assigned .
This is just a feature of ROX : Drag shortcuts to the panel , desktop and between windows . It is also possible to use ” composite ” application with xcompmgr , but this sacrifices the environment and lightness .
The system requirements are: rox-filer , fluxbox , pcmanfm and xdg – utils . For those who download the application on Debian format ( compatible with ubuntu 12.x, Debian, Mint etc. ) You can install via gdebi , or with the command in terminal mode, with root, “dpkg -i zappwm” followed by ” apt -get – f install” to correct dependencies.
Computer conferences are glorious and I love going to them, even though it means making eye contact with other humans and sharing air, and sometimes I even have to adjust my stride to avoid trampling people. Because they’re full of nerds and the latest tech, and what could be more fun than playing with someone else’s cool tech toys, and playing stump the chump with sales engineers? Nothing I tell you, nothing!
 It’s a bit of hyperbole to call openSUSE’s openQA the coolest tech in the show, but it is mighty ingenious and useful, and it literally stopped me in my tracks as I was cruising the vendor floor. openQA is an automated build tester that records the entire distro build process in a series of screenshots, and then it creates an ogg/theora video out of the screenshots. Don’t take my word for it– go look at example. Just click the little movie clapboard on any item on the results page.
It’s a bit of hyperbole to call openSUSE’s openQA the coolest tech in the show, but it is mighty ingenious and useful, and it literally stopped me in my tracks as I was cruising the vendor floor. openQA is an automated build tester that records the entire distro build process in a series of screenshots, and then it creates an ogg/theora video out of the screenshots. Don’t take my word for it– go look at example. Just click the little movie clapboard on any item on the results page.
openQA finds and reports errors, and it’s not just an OpenSUSE tool because it also works for RHEL, CentOS, and Fedora. OpenQA is the pretty front-end to OS-autoinst which was created and is maintained by Bernhard M. Wiedemann. OS-autoinst is distro-independent and should work with any Linux distribution. openQA and OS-autoinst can test everything from the bootloader and kernel to applications.
openQA and OS-autoinst still need work, so if you’re looking to make your mark as a FOSS contributor consider lending a hand to these excellent projects. Learn more about openQA at openQA in openSUSE
openSUSE 13.1 is officially released next week on Nov. 18. Fun fact: openSUSE has a new release every eight months, and there are only three per version: .1, .2 and .3. So a .1 release comes out every other November. openSUSE 13.1 promises greater stability (not that it’s ever been unstable), Amazon S3 integration, Samba 4.1, 32-bit ARM support, a a special Raspberry Pi build, and lots more.
