

Share your insights to help improve cloud native security and receive 25% off your CloudNativeSecurityCon registration.


Maintainer Confidential: Challenges and Opportunities One Year On
A year ago I wrote an article to give some insight into how an open source project looks behind the scenes from a maintainer’s perspective. One year on, I thought it might be interesting to share an update on that.
Who I am and what the project is and does was covered previously and hasn’t really changed. In short, I’m the Yocto Project’s primary technical lead. The project allows people/companies to build and maintain customized Linux and open source software in general in a scalable and maintainable way.
Who is using it? We often don’t know!
As the project continues to grow in usage, we keep finding out about new and interesting places it is being used. This is really exciting and what the project was designed for, so it is wonderful to see. The sad thing is that we can’t really talk about a lot of the usage. In some cases we find out by looking at the license compliance “bill of materials” that companies share. It is usually clear looking at the versions/names of the components that it is likely OpenEmbedded/Yocto Project derived but there is nothing we can quote to show that definitively. It is hard to demonstrate project usage or importance when you don’t know or can’t say who is using it. If you are using it, please let us say that you are! Please drop us an email or you can add to the list on our wiki.
Since last year the project has gained several members, some of them joining after reading the previous article and realizing the challenges the project was facing. This is great to see and really appreciated. The economic situation, globally and in this industry, hasn’t passed the project by and we have lost some members or some have downgraded, too.
The increased membership and participation has meant that the project can balance its budget and not forecast a deficit, hoping things will work out ok. For me personally, that does mean my job has a bit more security too; I’m not wondering if I’ll need to find a different income source in a few months. This also makes it easier for the project to retain some of our key help for things like documentation or maintaining our LTS releases. The time taken in training those people to the roles is not something which can be easily or quickly replaced so retention is important.
Sovereign Tech Fund support
The big news in the last year for us was finding that we could get some help from the Sovereign Tech Fund (STF), a German government funded initiative that is trying to help projects and the overall open software ecosystem. They read the article and wanted to see if there was a way to work together and help. The project had already been working on a five year plan, basically an open-ended discussion of where we’d like to see the project in five years’ time and what kinds of things might we like to see happen in that time frame. We found that we could take some of the themes from that plan and have financial help to bring them to reality.
Funding comes with constraints and it has been a challenge to do things in the time frame needed, but by contracting the work through many of the consultancies working within our ecosystem, we’ve been able to quickly pull together some amazing changes.
The projects we targeted were a mix across a spectrum of topics. Some are future looking with things like IDE integration into newer IDEs like VSCode. Some add automated testing to older code like Toaster, meaning we can stop it bit-rotting and degrading and start planning ways to better use it in the future. There was work to improve the developer experience both within our tools such as better understanding why cache objects (“sstate”) weren’t being reused, through to re-enabling patch submission/review processes automated CI-style helpers. There was also work done on properly documenting our security processes and preparing the project for the next generation of SPDX which is key to our Software Bill of Materials (SBoM) support.
Other projects include tool improvements to demonstrate and roll them out to other layers in the wider project ecosystem. Taking processes, techniques, and tools we have in the core and showing other layer maintainers how they can take advantage of them leads to wider ecosystem improvements in quality and productivity. We also have projects underway to explore the topic of binary packages in a source-based distro world and to look at ways we could improve our initial setup and user experience. Separate from the STF work, the project was also able to fund some improvements to the layer index but that wouldn’t have happened without the STF funding for other areas. The layer index works like a search engine for the project so it is of key importance to most of our users.
There were multiple good things to come out of all this work besides just the work itself. It meant that multiple members of the community were able to work on things that they have wanted to for a long time, knowing the benefit to everyone yet being unable to find a sponsor to allow them to spend that time. It also helped raise developer experience in a number of key areas, something we were conscious we were lacking.
I’d also note that the work was carefully planned to include and prioritize test automation so that as well as fixing fundamental issues, we’re better placed to avoid some of these issues in the future, too.
Maintainer/developer resourcing issues remain
All this sounds really positive, and it most definitely is, but there was a bit of a darker side too. The core of the project was stretched thin and I remain the only full time developer at the core. Much of the writing and technical execution of the contracts therefore fell to me. I did realize this was likely to happen but the opportunity to fix so many of these long-term issues meant that I opted to push through it and make it happen. While I don’t regret it, I doubt I could sustain doing anything like this again.
The project has talked about “the bus factor” problem it has for a long time, and I’ve grown quite used to being hit by metaphorical buses in meeting discussions. In some ways I’m not as worried about this as I once was. Both Yocto Project and OpenEmbedded both have structures in place allowing a clear path to making decisions and those would work to allow the roles I fill to be replaced. It is ironic that when things are running relatively smoothly, people actually question the need for those structures, often not realizing that the time they really come into their own are in times of crisis.
The real concern now is one of scaling and overload and this is probably the key problem the project now needs to find solutions for. Funding is one challenge to improving this, it becomes an easier problem to solve if that is less constrained. The second challenge is the project has tried several times to write a job description for someone to shadow/assist/help me in various ways and we’ve struggled every time as my role within the project has so many hats and the skill sets overlap into what are traditionally different roles. When you add together the project and programme management pieces, the technical architecture oversight and vision, the bug fixing, general development skills, community relations and business relations pieces, good QA engineering skills and general operational execution, it gets complicated. The closest we’ve come was realizing that we needed both deeply technical programme management/execution and general but highly skilled development engineering help for me. This is still an ongoing discussion, so let us know if you have ideas!
Relevance in the wider open source ecosystem
There is a significant lack of understanding and recognition of what the project can actually do for the wider ecosystem and also for specific enablement. An interesting example is RISC-V support within the project. There has been community-driven support added over the last few years and it does basically work but the architecture has not been tested on our CI systems. The main reason for that is that those systems are high cost and maintenance, funded by the project membership and RISC-V does not have enough representation there. We’ve actively sought out platinum or multiple gold member participation from RISC-V interested parties but sadly there hasn’t been any commitment. The RISC-V story is particularly unfortunate since the project is about to release its next LTS which only happens every two years and it won’t be on the test matrix.
Besides the LTS, the project is extremely efficient at bringing in new versions of FOSS components as they become available when those upstream projects make releases. There is particular value in testing those on more unusual architectures such as RISC-V as early as you can, at the point of entry into the project and the wider ecosystem. By doing that it doesn’t just help Yocto Project support but also that support in other distributions too. We’re clearly struggling to showcase the huge benefit this has!
I’d also like to highlight another key feature of the project, which is the ability for users to own and control their entire build process. This means users don’t have dependencies on other companies or public services and that years from now, they have the ability to rebuild the software shipping in your products. Several recent examples of changes in availability of software or services, such as the structural changes around Fedora/CentOS, have made some users ask very valid questions about their reliance on other companies and their ability to “control their own destiny”. Yocto Project and OpenEmbedded were built to be able to solve that problem and there is no lock-in or reliance on others necessary.
Two other related areas the project has been able to help make step change improvements in is reproducibility and software manifests. For reproducibility we’ve worked with various upstreams to ensure the tooling is able to support it well (through compiler options for example) and that upstream software stops encoding things like build paths into binary output. For software manifest support, the project was proud to help test elements of the upcoming SPDX 3.0 standard to ensure some of the usage issues of the previous versions are addressed and that it fits well in a software build environment. With recent developments like the European Cyber Resilience Act and with similar changes already present or coming in other jurisdictions, being able to comply easily with these through good tooling and processes will be key.
Availability of developers
The huge demand for Yocto Project/OpenEmbedded skilled engineers does have one other rather unfortunate impact on the project core. That demand is great for ensuring people in the project have employment, however because the skills are scarce, they often aren’t allowed time to contribute to “upstream” or back to the project core. Understandably, they may also be asked to prioritize work on product specific layers in preference to core code and overall project architecture. The “layer” approach the project takes in some ways makes this much easier to do, too.
While understandable, the loss of access to people’s knowledge, and their ability to help work on bugs or improvements, is another significant challenge for us which I’m not sure how to address at this time.
Summary
All in all, the last year has been really positive. The STF involvement was a very welcome surprise and we’ve achieved great things. Reading the article from a year ago, it is nice to be able to say that we’ve moved forward or even resolved some of those topic areas. Challenges remain though, particularly around participation in the project (both financial/membership and developer) if we’re to improve the overload problem.
Some of these issues are not unique to the Yocto Project and are faced by many open source projects. Regardless, I feel that we do need to be open about the issues even if we don’t have good solutions yet. While we don’t want to alienate our current developer community and maintainers, we’re trying to be open to new approaches and ideas, so please do get in touch if you think there is a way forward that we’re missing!
About the author: Richard Purdie is the Yocto Project architect and a Linux Foundation Fellow.
Find Your Pot of Career Gold & Save Up to 40%

→ Save 40% with code LUCK24 on IT Professional Programs & Bundles
→ Save 25% with code LUCK24CC on e-Learning Courses & Certifications & SkillCreds
→ Save 25% with code LUCK24ILT on Instructor-led Courses
Learn more at Linux Foundation Training
Bridging Design and Runtime Gaps: AsyncAPI in Event-Driven Architecture
The AsyncAPI specification emerged in response to the growing need for a standardized and comprehensive framework that addresses the challenges of designing and documenting asynchronous APIs. It is a collaborative effort of leading tech companies, open source communities, and individual contributors who actively participated in the creation and evolution of the AsyncAPI specification.
Various approaches exist for implementing asynchronous interactions and APIs, each tailored to specific use cases and requirements. Despite this diversity, these approaches fundamentally share a common baseline of key concepts. Whether it’s messaging queues, event-driven architectures, or other asynchronous paradigms, the overarching principles remain consistent.
Leveraging this shared foundation, AsyncAPI taps into a spectrum of techniques, providing developers with a unified understanding of essential concepts. This strategic approach not only fosters interoperability but also enhances flexibility across various asynchronous implementations, delivering significant benefits to developers.
From planning to execution: Design and runtime phases of EDA
The design time and runtime refer to distinct phases in the lifecycle of an event-driven system, each serving distinct purposes:
Design time: This phase occurs during the design and development of the event-driven system, where architects and developers plan and structure the system engaging in activities around:
- Designing event flows
- Schema definition
- Topic or channel design
- Error handling and retry policies
- Security considerations
- Versioning strategies
- Metadata management
- Testing and validation
- Documentation
- Collaboration and communication
- Performance considerations
- Monitoring and observability
The design phase yields assets, including a well-defined and configured messaging infrastructure. This encompasses components such as brokers, queues, topics/channels, schemas, and security settings, all tailored to meet specific requirements. The nature of these assets may vary based on the choice of the messaging system.
Runtime: This phase occurs when the system is in operation, actively processing events based on the design-time configurations and settings, responding to triggers in real time.
- Dynamic event routing
- Concurrency management
- Scalability adjustments
- Load balancing
- Distributed tracing
- Alerting and notification
- Adaptive scaling
- Monitoring and troubleshooting
- Integration with external systems
The output of this phase is the ongoing operation of the messaging platform, with messages being processed, routed, and delivered to subscribers based on the configured settings.
Role of AsyncAPI
AsyncAPI plays a pivotal role in the asynchronous API design and documentation. Its significance lies in standardization, providing a common and consistent framework for describing asynchronous APIs. AsyncAPI details crucial aspects such as message formats, channels, and protocols, enabling developers and stakeholders to understand and integrate with asynchronous systems effectively.
It should also be noted that the AsyncAPI specification serves as more than documentation; it becomes a communication contract, ensuring clarity and consistency in the exchange of messages between different components or services. Furthermore, AsyncAPI facilitates code generation, expediting the development process by offering a starting point for implementing components that adhere to the specified communication patterns.
In essence, AsyncAPI helps bridge the gap between design-time decisions and the practical implementation and operation of systems that rely on asynchronous communication.
Bridging the gap
Let’s explore a scenario involving the development and consumption of an asynchronous API, coupled with a set of essential requirements:
- Designing an asynchronous API in an event-driven architecture (EDA):
- Define the events, schema, and publish/subscribe permissions of an EDA service
- Expose the service as an asynchronous API
- Generating AsyncAPI specification:
- Use the AsyncAPI standard to generate a specification of the asynchronous API
- Utilizing GitHub for storage and version control:
- Check in the AsyncAPI specification into GitHub, leveraging it as both a storage system and a version control system
- Configuring GitHub workflow for document review:
- Set up a GitHub action designed to review pull requests (PRs) related to changes in the AsyncAPI document
- If changes are detected, initiate a validation process
- Upon a successful review and PR approval, proceed to merge the changes
- Synchronize the updated API design with the design time
- Set up a GitHub action designed to review pull requests (PRs) related to changes in the AsyncAPI document
This workflow ensures that design-time and runtime components remain in sync consistently. The feasibility of this process is grounded in the use of the AsyncAPI for the API documentation. Additionally, the AsyncAPI tooling ecosystem supports validation and code generation that makes it possible to keep the design time and runtime in sync.
Putting the scenario into action
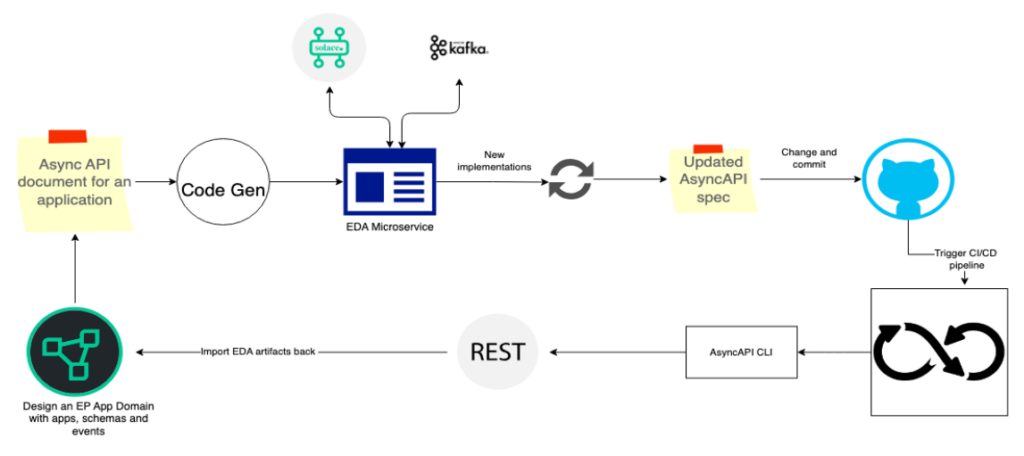
Let us consider Solace Event Portal as the tool for building an asynchronous API and Solace PubSub+ Broker as the messaging system.
An event portal is a cloud-based event management tool that helps in designing EDAs. In the design phase, the portal facilitates the creation and definition of messaging structures, channels, and event-driven contracts. Leveraging the capabilities of Solace Event Portal, we model the asynchronous API and share the crucial details, such as message formats, topics, and communication patterns, as an AsyncAPI document.
We can further enhance this process by providing REST APIs that allow for the dynamic updating of design-time assets, including events, schemas, and permissions. GitHub actions are employed to import AsyncAPI documents and trigger updates to the design-time assets.
The synchronization between design-time and runtime components is made possible by adopting AsyncAPI as the standard for documenting asynchronous APIs. The AsyncAPI tooling ecosystem, encompassing validation and code generation, plays a pivotal role in ensuring the seamless integration of changes. This workflow guarantees that any modifications to the AsyncAPI document efficiently translate into synchronized adjustments in both design-time and runtime aspects.
Conclusion
Keeping the design time and runtime in sync is essential for a seamless and effective development lifecycle. When the design specifications closely align with the implemented runtime components, it promotes consistency, reliability, and predictability in the functioning of the system.
The adoption of the AsyncAPI standard is instrumental in achieving a seamless integration between the design-time and runtime components of asynchronous APIs in EDAs. The use of AsyncAPI as the standard for documenting asynchronous APIs, along with its robust tooling ecosystem, ensures a cohesive development lifecycle.
The effectiveness of this approach extends beyond specific tools, offering a versatile and scalable solution for building and maintaining asynchronous APIs in diverse architectural environments.
Author
Post contributed by Giri Venkatesan, Solace
Leap into Learning and SAVE up to 50% off!


Save up to 50% on IT Professional Programs, Bundles, and more!
Learn more at training.linuxfoundation.org
Implementing OpenTelemetry Natively in an Event Broker
Introduction
In basic terms, an event-driven architecture (EDA) is a distributed system that involves moving data and events between microservices in an asynchronous manner with an event broker acting as the central nervous system in the overall architecture. It is a software design pattern in which decoupled applications can asynchronously publish and subscribe to events via an event broker.
In an increasingly event-driven world, enterprises are deploying more messaging middleware solutions comprising networks’ message broker nodes. These networks route event-related messages between applications in disparate physical locations, clouds, or even geographies. As the enterprises grow in size and maturity in their EDA deployment, it gets more and more challenging to diagnose problems simply by troubleshooting an error message or looking at a log. This is where distributed tracing comes to the rescue by providing system administrators with observability and the ability to trace the lifecycle of an event as it travels between microservices and different API calls and hops within event brokers through the entire event mesh—composed of a network of connected brokers located close to the publishers and subscribers.
Problem Statement
To achieve full observability in any system, there is one very important assumption that needs to be satisfied: every component in the system MUST be able to generate information about what’s happening with it and its interaction with other components. So, a transactional event that is composed of multiple hops between different systems and / or interfaces would require the release of trace information on every hop from every interface. A missing step in trace generation results in an incomplete picture in the lifecycle of the transactional event. Pretty straightforward. However, complexity knocks on the door when dealing with event brokers in an EDA system.
To understand why it’s complex to instrument event broker, let us take a look at the three levels at which traces can be collected in a distributed event-driven system:
- Application level: During business logic execution within the context of the microservice
- API level: During communication between other components and services, whether it is synchronous REST or an asynchronous event call
- Event broker level: At every hop inside the event mesh and inside the event broker
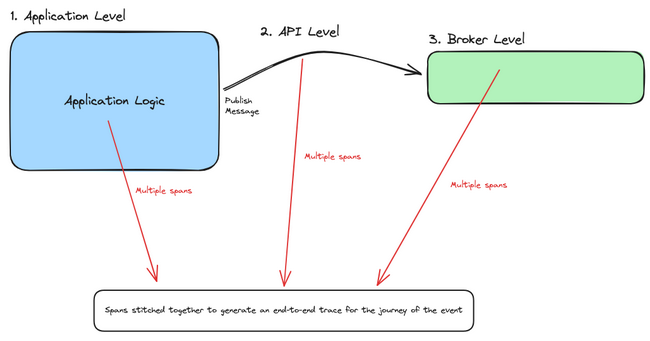
As the business evolves in both scale and routing sophistication, it becomes more critical to have visibility into exactly how messages are being processed by the underlying message brokering topology. Without observability at the broker / routing tier, here are some questions an enterprise cannot answer:
- Where are messages routed—point to point, across geographies and regions, or from on premises to cloud?
- Are messages processed successfully?
- How does message processing track against key metrics and performance indicators?
- Are messages delayed by insufficient resources?
- What type of messages end up in an error state due to misrouting, permissions, content, or lack of storage?
- How do messages get tracked against other business or regulatory requirements, e.g., geographical data sovereignty, data residency requirements, sensitive data exposure, and time to process?
Where Does OpenTelemetry Fit Within EDA Systems?
As the industry standard and vendor- and tool-agnostic framework for managing telemetry data, OpenTelemetry (OTel) is the de facto go-to for answering all observability-related questions in the overall architecture. And in the spirit of adding more observability to the system, EDA needs OTel to solve mysteries to answer the previous questions and get a better idea of where things went wrong or what needs to be improved within the path of the transactional event.
The OTel ecosystem has reached a high level of maturity for tools and processes that generate and collect trace information at the application and API levels. With that being said, there are still some gaps in the industry when it comes to collecting metrics from event brokers in event-driven systems on the event-broker level. As stated in the semantic conventions for messaging spans in the OTel documentation, messaging systems are not standardized, meaning there are vendor-specific customizations on how to deal with trace generation from within the system. The design of event broker technologies has not historically supported OTel natively within the broker, hence leaving the broker component in the EDA system as a “Black Box,” where the limits of instrumentation with a message broker are reached along the boundaries of the broker: message in and message out.
As mentioned previously, to achieve complete visibility in a distributed EDA system, every component needs to generate trace information to the OTel collector, including the message broker. To support tracing within the OTel collector and the broker, a dedicated receiver in the collector needs to translate messaging-specific activities to telemetry data. To demonstrate how the messaging component in an EDA system could be instrumented, I will use the Solace PubSub+ Event Broker as an example for the rest of the article.
Enabling Tracing on the Broker Level
The Solace PubSub+ Event Broker is an advanced event broker that enables real-time, high-performance messaging in an EDA system running in cloud, on-premises, and hybrid environments. In an effort to bridge the observability gap within the event broker in an EDA system, Solace has native support in the OTel Collector through a Solace receiver. As applications start publishing and consuming guaranteed messages to and from the event broker, spans are generated from the application and API level using OTel SDK libraries and from the broker reflecting every hop inside the broker and within the event mesh. Activities such as enqueuing from publishing, dequeuing from consuming, and acknowledgment will generate spans that the OTel collector consumes and processes.
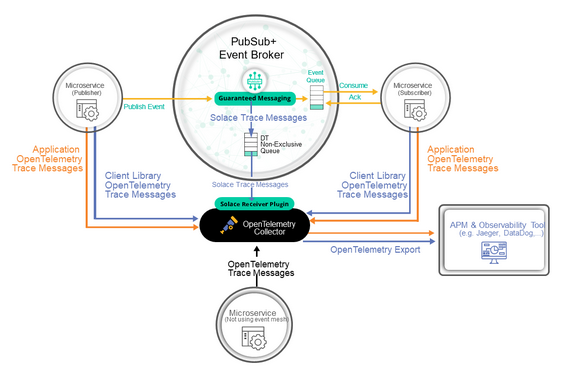
The above diagram shows the basic components of distributed tracing for a single event broker:
- Application client program
This is any piece of software that communicates with the Solace PubSub+ Event Broker via either the native element management protocol or via any of the standard messaging protocols within the supported languages and messaging protocols.
- Distributed tracing-enabled Solace PubSub+ Event Broker
The core event broker with an activated distributed tracing functionality.
- The Contrib distribution of the OpenTelemetry Collector
A version of the OTel Collector that contains the Solace receiver.
- OpenTelemetry-compliant observability backend
An observability tool / product that consumes OTel traces (e.g., Jaeger, DataDog, Dynatrace, etc.).
Thanks to the standardization of trace messages using the OTel Protocol (OTLP), after the spans are received by the Solace receiver on the OTel collector, they are processed to standardized OTel trace messages and passed to exporters. The exporter is a component in the collector that supports sending data to the backend observability system of choice. We can now get more visibility into the lifecycle of a transactional event in an EDA system as it propagates through the event broker(s) and the different queues within.
Note that once a single Solace PubSub+ Event Broker is configured for distributed tracing, this same configuration can be utilized for every event broker you connect within an event mesh.
Instrumenting Using an Agent: Auto-Instrumentation
For Java-based applications, it is common practice to dynamically inject telemetry information for any call an application does without the need to manually change business logic by simply running an agent alongside the application. This approach is known as automatic instrumentation and is used to capture telemetry information at the “edges” of a microservice. More details on how to download the Java agent can be found here.
After installing the Java agent, run the Solace producing application as follows:
java -javaagent:<absolute_path_to_the_jar_file>/opentelemetry-javaagent.jar \
-Dotel.javaagent.extensions=<absolute_path_to_the_jar_file>/solace-opentelemetry-jms-integration-1.1.0.jar \
-Dotel.propagators=solace_jms_tracecontext \
-Dotel.exporter.otlp.endpoint=http://localhost:4317 \
-Dotel.traces.exporter=otlp \
-Dotel.metrics.exporter=none \
-Dotel.instrumentation.jms.enabled=true \
-Dotel.resource.attributes=“service.name=SolaceJMSPublisher” \
-Dsolace.host=localhost:55557 \
-Dsolace.vpn=default \
-Dsolace.user=default \
-Dsolace.password=default \
-Dsolace.topic=solace/tracing \
-jar solace-publisher.jar
Similarly, run the consuming application as follows:
java -javaagent:<absolute_path_to_the_jar_file>/opentelemetry-javaagent.jar \
-Dotel.javaagent.extensions=<absolute_path_to_the_jar_file>/solace-opentelemetry-jms-integration-1.1.0.jar \
-Dotel.propagators=solace_jms_tracecontext \
-Dotel.traces.exporter=otlp \
-Dotel.metrics.exporter=none \
-Dotel.instrumentation.jms.enabled=true \
-Dotel.resource.attributes=“service.name=SolaceJMSQueueSubscriber” \
-Dsolace.host=localhost:55557 \
-Dsolace.vpn=default \
-Dsolace.user=default \
-Dsolace.password=default \
-Dsolace.queue=q \
-Dsolace.topic=solace/tracing \
-jar solace-queue-receiver.jar
What happens behind the scenes when an application uses the JMS Java API to publish or subscribe on the event broker is that the OTel Java Agent intercepts the call with the help of the Solace OTel JMS integration extension and generates spans to the OTLP receiver in the OTel collector. This generates spans on the API level. Broker-level spans are generated from the Solace PubSub+ Event Broker upon arrival of the message on the broker after it’s enqueued. The collector generates and receives further broker-specific spans in the collector and processes them into the OTel-specific format. All the generated spans from the different steps are then exported and stitched for further processing.
The following figure illustrates the details of the inner workings of the Java auto-instrumentation agent:
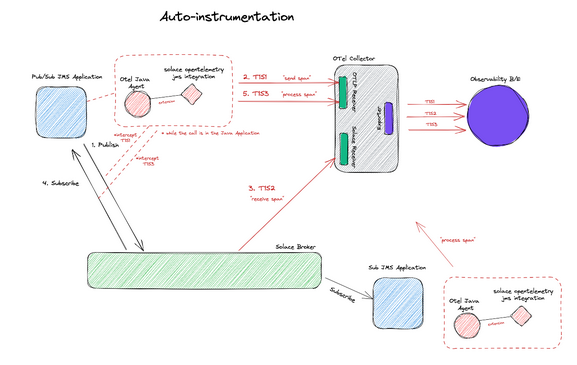
The advantage of such an approach is that the Java auto-instrumentation agent takes care of span generation on the API level without the need for code changes or application business logic configuration. The drawback is that you can’t add further customization on the different spans generated to get a more detailed picture of what’s happening in the business logic of the microservice.
Instrumenting Using an SDK: Manual Instrumentation
In some cases, developers want to have more control over when spans are generated and what attributes are included in the span during the business logic of the microservice, hence they generate application-level traces. This is done using the OTel SDK and broker-specific APIs that support span generation and context propagation.
Developers can interact with the event broker through APIs in multiple languages. In the following example, I will be using the latest Java API for the Solace Messaging Platform, also known as JCSMP, which supports span generation and context propagation for distributed tracing. For a publishing application to support manual instrumentation directly from the business logic, the following needs to be done:
- Import the OpenTelemetry and Solace libraries for context propagation:
import com.solace.messaging.trace.propagation.SolaceJCSMPTextMapGetter;
import com.solace.messaging.trace.propagation.SolaceJCSMPTextMapSetter;
import com.solace.samples.util.JcsmpTracingUtil;
import com.solace.samples.util.SpanAttributes;
import com.solacesystems.jcsmp.*;
import io.opentelemetry.api.trace.Span;
import io.opentelemetry.api.trace.SpanKind;
import io.opentelemetry.api.trace.StatusCode;
import io.opentelemetry.context.Scope;
import io.opentelemetry.context.propagation.TextMapPropagator;
import io.opentelemetry.context.Context;
- Extract message context, if it exists, before injecting any new context into the message:
final SolaceJCSMPTextMapGetter getter = new SolaceJCSMPTextMapGetter();
final Context extractedContext = JcsmpTracingUtil.openTelemetry.getPropagators().getTextMapPropagator()
.extract(Context.current(), message, getter);
- Set the extracted context as the current context of a created span, and add any attributes you want to the generated span:
final Span sendSpan = JcsmpTracingUtil.tracer
.spanBuilder(SERVICE_NAME + ” ” + SpanAttributes.MessagingOperation.SEND)
.setSpanKind(SpanKind.CLIENT)
.setAttribute(SpanAttributes.MessagingAttribute.DESTINATION_KIND.toString(),
SpanAttributes.MessageDestinationKind.TOPIC.toString())
.setAttribute(SpanAttributes.MessagingAttribute.IS_TEMP_DESTINATION.toString(), “true”)
//Set more attributes as needed
.setAttribute(“myKey”, “myValue” + ThreadLocalRandom.current().nextInt(1, 3))
.setParent(extractedContext) // set extractedContext as parent
.startSpan();
- Inject the new context into the message:
final SolaceJCSMPTextMapSetter setter = new SolaceJCSMPTextMapSetter();
final TextMapPropagator propagator = JcsmpTracingUtil.openTelemetry.getPropagators().getTextMapPropagator();
propagator.inject(Context.current(), message, setter);
- Send the message to the Solace broker:
producer.send(message, topic);
That’s it! The following figure illustrates the details of how manual instrumentation is achieved from the application level:
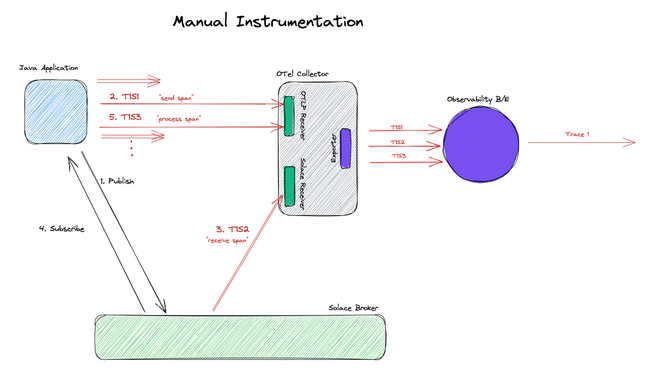
The advantage of such an approach is having full control over what attributes are included in the generated span and when the span is generated. A developer also has control over generating other custom spans that are not related to messaging. It is, however important to note that this adds further complexity in application development, and the order of span generation becomes an implementation detail.
Conclusion
In conclusion, the Solace PubSub+ Event Broker is one of the many existing message-broker technologies that could be used for communication in EDA systems. The OpenTelemetry project helps to answer observability-related questions in the system from an application and API level. Broker-level instrumentation requires vendor-specific customization to define the activities within the broker that result in span generation. There are two approaches to generating spans in an EDA system: auto-instrumentation and manual instrumentation. Using the Solace PubSub+ Event Broker within an EDA system, you can get more visibility on what happens to the message within the broker during the lifecycle of a transactional event.
For more information on how to configure a distributed tracing-enabled event mesh with auto and manual instrumented applications, you can take a look at this step-by-step tutorial. For further resources on OTel and how it fits in a distributed EDA system, check out this short video series. And if you’re interested in learning more about how Solace supports open source initiatives, visit the CNCF resources page for Solace.
Happy coding!
Author

Contributed by
Tamimi Ahmad, Solace
Innovation as a Catalyst in Telecommunications
Innovation—a term often tossed around but rarely dissected for its true impact, especially in the ever-evolving world of telecommunications. At its core, innovation is about breaking new ground; it’s about moving beyond traditional methods to create novel solutions for old problems and to anticipate challenges in an ever-changing industry.
Innovation in telecommunications isn’t just about adopting the latest technology; it’s a mindset. It’s the willingness to challenge the status quo, to rethink processes, and to be open to change. True innovation lies in the ability to blend creativity with practicality to address the industry’s current and future needs.
The telecom industry, characterized by rapid technological advancements and changing consumer behaviors, demands continuous innovation. Stagnation leads to obsolescence. Companies must innovate not only to solve existing problems but also to preemptively tackle potential future challenges. This proactive approach keeps companies ahead of the curve, ensuring that they don’t just survive but thrive.
Network automation emerges as a pivotal tool for innovation in telecommunications. It’s not just about deploying isolated use cases; it’s about equipping teams with a comprehensive suite of tools that foster an environment where the majority of their energy can be focused on creative processes.
The true power of network automation lies in its ability to free up valuable resources. Automating routine and repetitive tasks allows engineers and developers to concentrate on creative problem-solving and innovative thinking. It’s not merely about having technology at one’s disposal; it’s about having the right technology that empowers teams to think beyond day-to-day operations.
Implementing network automation requires more than just technological adoption; it requires a cultural shift. This shift involves embracing a culture of experimentation, where failure is seen as a stepping stone to success and out-of-the-box thinking is encouraged.
Innovation in telecommunications, fueled by network automation, is not a one-time initiative but a continuous journey. It’s about creating an ecosystem that nurtures creativity, encourages experimentation, and continuously pushes the boundaries of what’s possible. As the industry evolves, this approach to innovation will not only solve current problems but also pave the way for future advancements, ensuring that the telecom industry remains at the forefront of technological evolution.
Another crucial aspect of driving innovation in telecommunications is learning from the DevOps movement and open source communities. These domains stand as exemplary models of innovation vehicles. DevOps, with its emphasis on continuous integration, deployment, and collaboration between development and operations teams, provides a blueprint for operational efficiency and agility. This methodology underscores the importance of rapid iteration, feedback, and improvement—principles that are essential for fostering innovation in telecom.
Similarly, open source communities offer invaluable insights into the power of collaboration and shared knowledge. These communities thrive on the principles of openness, transparency, and collective problem-solving, which can significantly accelerate the pace of innovation. By adopting these principles, telecom companies can tap into a vast pool of knowledge and expertise, breaking down silos and fostering a more collaborative and innovative environment. The open source model encourages a culture where ideas are freely exchanged and solutions are developed collaboratively, leading to more robust and creative outcomes.
Incorporating these lessons from DevOps and open source communities into the fabric of network automation and telecommunications can lead to transformative changes. It’s about building a culture that values continuous learning, collaboration, and openness—key ingredients for sustained innovation and progress in the dynamic world of telecom.
Telecommunications plays a role in every major innovation of the 21st century. From driving global connectivity to enabling new technologies, telcos are the backbone of our digital age. The integration of network automation, along with lessons learned from DevOps and open source, will not only reshape telecommunications but pave the way for technological breakthroughs unimaginable today. We are on the verge of unlocking potential that will transform the way we live, work, and connect. Telecommunications is not just an industry; it is the enabler of an unprecedented era of innovation.
Guest Post By
Iquall Networks
https://iquall.net/
Linux Foundation Newsletter: January 2024

Welcome to the Linux Foundation’s January newsletter! In this edition you’ll find new research reports, key LF Project updates, and our first Training & Certification deal of the year. Also, if you missed it, we published our 2023 Annual Report in December, “Rising Tides of Open Source.” We thank you for your continued support of the Linux Foundation and look forward with excitement as we continue our Open Source journey together in 2024.
Read More at linuxfoundation.org