While the concept of distributed ledgers has been around for a long while, it wasn’t until in recent years that it became a reality. The most popular implementation of distributed ledgers is blockchain, the technology that supports cryptocurrencies such as bitcoin and ethereum.
Blockchain uses computing power and cryptography to maintain its distributed ledger. Every node that participates in the network stores a copy of the blockchain. Blockchain records are grouped into blocks and are sequentially linked together through cryptographic hashes. Hashes are mathematical representations tied to the data structure of each block. The slightest change in any transaction changes the hash of its block and all blocks that come after it, making it invalid. This mechanism further protects the blockchain against tampering and makes it easier for the nodes to validate new transactions.
Blockchains have a consensus mechanism that enables the participants in the network to agree on transactions that can be added to the ledger. Every few minutes, a network of computers called “miners” runs mathematical operations to create new blocks from recently submitted transactions. Once a new block is confirmed, all the nodes append it to their copy of the blockchain (learn more at Blockchain explained and How does bitcoin mining work?).
A recent devel list discussion for popular Linux distro Fedora mentioned Clear Linux optimizations, which may be relevant to Fedora developers in the future. It was mentioned that Intel’s Clear Linux show noticeable performance gains over Xubuntu, as based on graphs by Phoronix.
A Fedora user then decided to release a Clear Linux optimized Fedora kernel for Fedora 28 and Fedora Rawhide, with the following notes:
“Intels clear linux kernel packaged for fedora. The aim of this kernel is to mimic similar performance to intels clear linux os on Intel based machines running fedora. Kernel only supports accelerated performance on Intel Cpu’s,similar performance on Amd based machines is not guarenteed.“
Everyone from developer teams, to operations, to managers of virtual machines needs to know Linux, said Red Hat’s Brian Gracely.
TechRepublic’s Dan Patterson spoke with with Brian Gracely, director of cloud strategy at Red Hat OpenShift, about Linux and the cloud.
Gracely: …the really big trend lately with Linux has been Linux containers and technologies like [Google] Kubernetes. So, we’re seeing enterprises want to build new applications. We’re seeing the infrastructure be more software defined. Linux ends up becoming the foundation for a lot of the things going on in enterprise IT these days.
Patterson: And how can employers find the employees that have the right skill sets, and what are the best skill sets for deploying Red Hat in the cloud?
Gracely: Yeah. So I think there’s a couple of core skill sets. One, obviously, we’re seeing more and more Linux system admin, system administrators, who are developing those skills, because those skills are applicable in their own data centers. They’re applicable in the public cloud. That’s a great foundation.
People might not think about the Linux kernel all that much when talking about containers, serverless, and other hot technologies, but none of them would be possible without Linux as a solid base to build on, says Greg Kroah-Hartman. He should know. Kroah-Hartman maintains the stable branch of the Linux kernel along with several subsystems. He is also co-author of the Linux Kernel Development Report, a Fellow at The Linux Foundation, and he serves on the program committee for Open Source Summit.
In this article, we talk with Kroah-Hartman about his long involvement with Linux, the importance of community interaction, and the upcoming Open Source Summit.
Greg Kroah-Hartman (right) talks about Linux and Open Source Summit.
The Linux Foundation: New technologies (cloud, containers, machine learning, serverless) are popping up on weekly basis, what’s the importance of Linux in the changing landscape?
Greg K-H: There’s the old joke, “What’s a cloud made of? Linux servers.” That is truer than most people realize. All of those things you mention rely on Linux as a base technology to build on top of. So while people might not think about “Linux the kernel” all that much when talking about containers, serverless and the other “buzzwords of the day,” none of them would be possible without Linux being there to ensure that there is a rock-solid base for everyone to build on top of.
The goal of an operating system is to provide a computing platform to userspace that looks the same no matter what hardware it runs on top of. Because of this, people can build these other applications and not care if they are running it locally on a Raspberry Pi or in a cloud on a shared giant PowerPC cluster as everywhere the application API is the same.
So, Linux is essential for all of these new technologies to work properly and scale and move to different places as needed. Without it, getting any of those things working would be a much more difficult task.
LF: You have been involved with Linux for a very long time. Has your role changed within the community? You seem to focus a lot on security these days.
Greg K-H:I originally started out as a driver writer, then helped write the security layer in the kernel many many years ago. From there I started to maintain the USB subsystem and then co-created the driver model. From there I ended up taking over more driver subsystems and when the idea for the stable kernel releases happened back in 2005, I was one of the developers who volunteered for that.
So for the past 13 years, I’ve been doing pretty much the same thing, not much has changed since then except the increased number of stable trees I maintain at the same time to try to keep devices in the wild more secure.
I’ve been part of the kernel security team I think since it was started back in the early 2000’s but that role is more of a “find who to point the bug at” type of thing. The kernel security team is there to help
take security problem reports and route them to the correct developer who maintains or knows that part of the kernel best. The team has grown over the years as we have added the people that ended up getting called on the most to reduce the latency between reporting a bug and getting it fixed.
LF: We agree that Linux is being created by people all over the map, but once in a while it’s great to meet people in person. So, what role does Open Source Summit play in bringing these people together?
Greg K-H:Because open source projects are all developed by people who work for different companies and who live in different places, it’s important to get together when ever possible to actually meet the people behind the email if at all possible. Development is an interaction that depends on trust, if I accept patches from you, then I am now responsible for those changes as well. If you disappear I am on the hook for them, so either I need to ensure they are correct, or even better, I can know that you will be around to fix the code if there is a problem. By meeting people directly, you can establish a face behind the email to help smooth over any potential disagreements that can easily happen due to the lack of “tone” in online communication.
It’s also great to meet developers of other projects to hear of ways they are abusing your project to get it to bend to their will, or learn of problems they are having that you did not know about. Or just learn about new things that are being developed in totally different development groups. The huge range of talks at a conference like this makes it easy to pick up on what is happening in a huge range of different developer communities easily.
LF: You obviously meet a lot of people during the event. Have you ever come across an incident where someone ended up becoming a contributor or maintainer because of the exposure such an event provided?
Greg K-H: At one of the OSS conferences last year, I met a college student who was attending the conference for the first time. They mentioned that they were looking of any project ideas that someone with their skill level could help out with. At a talk later that day a new idea for how to unify a specific subsystem of the kernel came up and how it was going “just take a bunch of grunt work” to accomplish. Later that night, at the evening event, I saw the student again and mentioned the project to them and pointed them at the developer who asked for the help. They went off to talk in the corner about the specifics that would be needed to be done.
A few weeks later, a lot of patches started coming from the student and after a few rounds of review, were accepted by the maintainer. More patches followed and eventually the majority of the work was done, which was great to see, the kernel really benefited from their contribution.
This year, I ran into the student again at another OSS conference and asked them what they were doing now. Turns out they had gotten a job offer and were working for a Linux kernel company doing development on new products during their summer break. Without that first interaction, meeting the developers directly that worked on the subsystem that needed the help, getting a job like that would have been much more difficult.
So, while I’m not saying that everyone who attends one of these types of conferences will instantly get a job, you will interact with developers who know what needs to be done in different areas of their open source projects. And from there it is almost an easy jump to getting solid employment with one of the hundreds of companies that rely on these projects for their business.
LF: Are you also giving any talks at Open Source Summit?
Greg K-H:I’m giving a talk about the Spectre and Meltdown problems that have happened this year. It is a very high-level overview, going into the basics of what they are, and describing when the many different variants were announced and fixed in Linux. This is a new security type of problem that is going to be with us for a very long time and I give some good tips on how to stay on top of the problem and ensure that your machines are safe.
Sign up to receive updates on Open Source Summit North America:
Linux file servers play an essential role. The ability to share files is a basic expectation with any modern operating system in the workplace. When using one of the popular Linux distributions, you have a few different file sharing options to choose from. Some of them are simple but not that secure. Others are highly secure, yet require some know-how to set up initially.
Once set up on a dedicated machine, you can utilize these file sharing technologies on a dedicated file server. This article will address these technologies and provide some guidance on choosing one option over another.
Samba Linux File Server
Samba is essentially a collection of tools to access networked SMB (Server Message Block) shares. The single biggest advantage to Samba as a file sharing technology is that it’s compatible with all popular operating systems, especially Windows. Setup correctly, Samba works flawlessly between Windows and Linux servers and clients.
An important thing to note about Samba is that it’s using the SMB protocol to make file sharing possible. SMB is a protocol native to Windows whereas Samba merely provides SMB support to Linux. So when considering a file sharing technology for your needs, keep this in mind.
Learn how to easily check Linux logs in this article from our archives.
At some point in your career as a Linux administrator, you are going to have to view log files. After all, they are there for one very important reason…to help you troubleshoot an issue. In fact, every seasoned administrator will immediately tell you that the first thing to be done, when a problem arises, is to view the logs.
And there are plenty of logs to be found: logs for the system, logs for the kernel, for package managers, for Xorg, for the boot process, for Apache, for MySQL… For nearly anything you can think of, there is a log file.
Most log files can be found in one convenient location:/var/log. These are all system and service logs, those which you will lean on heavily when there is an issue with your operating system or one of the major services. For desktop app-specific issues, log files will be written to different locations (e.g., Thunderbird writes crash reports to ‘~/.thunderbird/Crash Reports’). Where a desktop application will write logs will depend upon the developer and if the app allows for custom log configuration.
We are going to be focus on system logs, as that is where the heart of Linux troubleshooting lies. And the key issue here is, how do you view those log files?
Fortunately there are numerous ways in which you can view your system logs, all quite simply executed from the command line.
/var/log
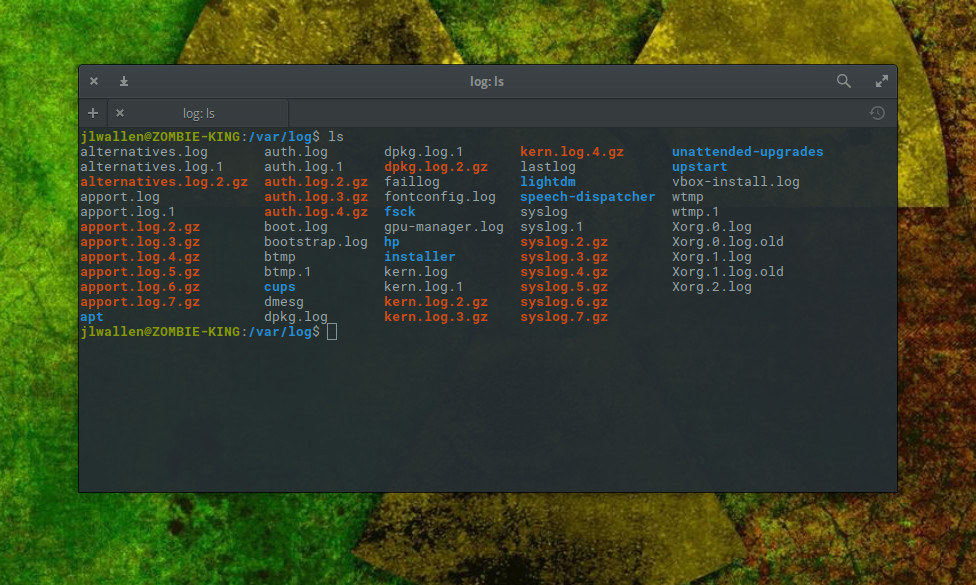
This is such a crucial folder on your Linux systems. Open up a terminal window and issue the command cd /var/log. Now issue the command ls and you will see the logs housed within this directory (Figure 1).
Figure 1: A listing of log files found in /var/log/.
Now, let’s take a peek into one of those logs.
Viewing logs with less
One of the most important logs contained within /var/log is syslog. This particular log file logs everything except auth-related messages. Say you want to view the contents of that particular log file. To do that, you could quickly issue the command less /var/log/syslog. This command will open the syslog log file to the top. You can then use the arrow keys to scroll down one line at a time, the spacebar to scroll down one page at a time, or the mouse wheel to easily scroll through the file.
The one problem with this method is that syslog can grow fairly large; and, considering what you’re looking for will most likely be at or near the bottom, you might not want to spend the time scrolling line or page at a time to reach that end. Will syslog open in the less command, you could also hit the [Shift]+[g] combination to immediately go to the end of the log file. The end will be denoted by (END). You can then scroll up with the arrow keys or the scroll wheel to find exactly what you want.
This, of course, isn’t terribly efficient.
Viewing logs with dmesg
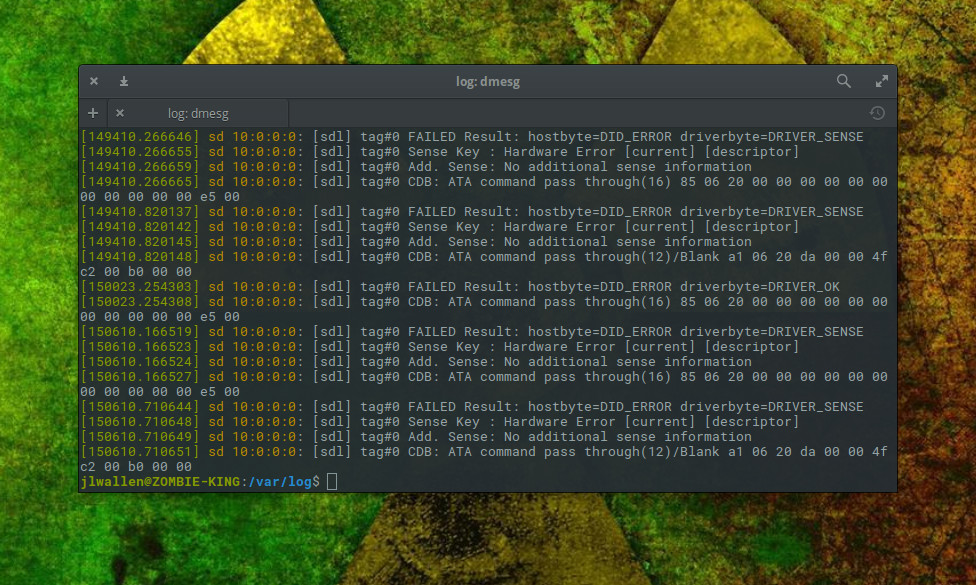
The dmesg command prints the kernel ring buffer. By default, the command will display all messages from the kernel ring buffer. From the terminal window, issue the command dmesg and the entire kernel ring buffer will print out (Figure 2).
Figure 2: A USB external drive displaying an issue that may need to be explored.
Fortunately, there is a built-in control mechanism that allows you to print out only certain facilities (such as daemon).
Say you want to view log entries for the user facility. To do this, issue the command dmesg –facility=user. If anything has been logged to that facility, it will print out.
Unlike the less command, issuing dmesgwill display the full contents of the log and send you to the end of the file. You can always use your scroll wheel to browse through the buffer of your terminal window (if applicable). Instead, you’ll want to pipe the output of dmesg to the less command like so:
dmesg | less
The above command will print out the contents of dmesgand allow you to scroll through the output just as you did viewing a standard log with theless command.
Viewing logs with tail
Thetailcommand is probably one of the single most handy tools you have at your disposal for the viewing of log files. What tail does is output the last part of files. So, if you issue the command tail /var/log/syslog, it will print out only the last few lines of the syslog file.
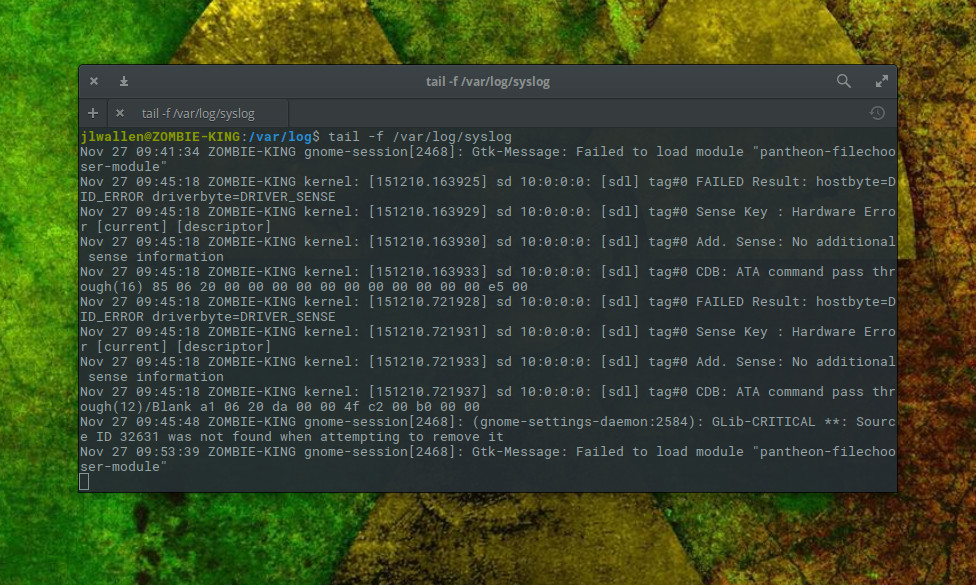
But wait, the fun doesn’t end there. The tail command has a very important trick up its sleeve, by way of the-f option. When you issue the command tail -f /var/log/syslog, tailwill continue watching the log file and print out the next line written to the file. This means you can follow what is written to syslog, as it happens, within your terminal window (Figure 3).
Figure 3: Following /var/log/syslog using the tail command.
Using tailin this manner is invaluable for troubleshooting issues.
To escape thetail command (when following a file), hit the [Ctrl]+[x] combination.
You can also instruct tail to only follow a specific amount of lines. Say you only want to view the last five lines written to syslog; for that you could issue the command:
tail -f -n 5 /var/log/syslog
The above command would follow input to syslog and only print out the most recent five lines. As soon as a new line is written to syslog, it would remove the oldest from the top. This is a great way to make the process of following a log file even easier. I strongly recommend not using this to view anything less than four or five lines, as you’ll wind up getting input cut off and won’t get the full details of the entry.
There are other tools
You’ll find plenty of other commands (and even a few decent GUI tools) to enable the viewing of log files. Look to more, grep, head, cat, multitail,andSystem Log Viewerto aid you in your quest to troubleshooting systems via log files.
“The Product Owner role no longer exists” I recently announced to an entire department in a large company. A few POs looked a bit shocked and concerned. What would they do instead?
Before I get into who or what would replace the PO role, let me offer a bit of background on this group. Three coaches, including myself, had assessed this group prior to beginning work with them. Our findings were typical:
Too much technical debt was slowing development to a crawl
There was insufficient clarity on what needed to be built
The developers spent little time with their Product Owner
The team was scattered around a building, not co-located
etc.
When you perform numerous assessments of teams or departments in many industries, you tend to see patterns. The above issues are common. We’ve worked out solutions to these problems eons ago. The challenge is whether people want to embrace change and actually solve their problems. This group apparently was hungry enough to want change….
Chartering is a vital skill I learned from a software industry legend named III. It helps teams and organizations figure out what outcome they’d like to achieve, how they would know they achieved it and who is necessary to help achieve it.
BlueK8s is a new open source Kubernetes initiative from ‘big data workloads’ company BlueData — the project’s direction leads us to learn a little about which direction containerised cloud-centric applications are growing.
The first open project in the BlueK8s initiative is Kubernetes Director (aka KubeDirector), for deploying and managing distributed ‘stateful applications’ with Kubernetes.
Apps can be stateful or stateless….
A stateful app is a program that saves client data from the activities of one session for use in the next session — the data that is saved is called the application’s state.
Typically, stateless applications are microservices or containerised applications that have no need for long-running [data] persistence and aren’t required to store data.
Serverless architecture is not, despite its name, the elimination of servers from distributed applications. Serverless architecture refers to a kind of illusion, originally made for the sake of developers whose software will be hosted in the public cloud, but which extends to the way people eventually use that software. Its main objective is to make it easier for a software developer to compose code, intended to run on a cloud platform, that performs a clearly-defined job.
If all the jobs on the cloud were, in a sense, “aware” of one another and could leverage each other’s help when they needed it, then the whole business of whose servers are hosting them could become trivial, perhaps irrelevant. And not having to know those details might make these jobs easier for developers to program. Conceivably, much of the work involved in attaining a desired result, might already have been done.
What does serverless mean for us at [Amazon] AWS?” asked Chris Munns, senior developer advocate for serverless at AWS, during a session at the re:Invent 2017 conference. “There’s no servers to manage or provision at all. This includes nothing that would be bare metal, nothing that’s virtual, nothing that’s a container — anything that involves you managing a host, patching a host, or dealing with anything on an operating system level, is not something you should have to do in the serverless world.”
In today’s technology arena, open source is pervasive. The 2018 Open Source Jobs Reportfound that hiring open source talent is a priority for 83 percent of hiring managers, and half are looking for candidates holding certifications. And yet, 87 percent of hiring managers also cite difficulty in finding the right open source skills and expertise. This article is the second in a weekly series on the growing importance of open source certification.
In the first article, we focused on why certification matters now more than ever. Here, we’ll focus on the kinds of certifications that are making a difference, and what is involved in completing necessary training and passing the performance-based exams that lead to certification, with tips from Clyde Seepersad, General Manager of Training and Certification at The Linux Foundation.
Performance-based exams
So, what are the details on getting certified and what are the differences between major types of certification? Most types of open source credentials and certification that you can obtain are performance-based. In many cases, trainees are required to demonstrate their skills directly from the command line.
“You’re going to be asked to do something live on the system, and then at the end, we’re going to evaluate that system to see if you were successful in accomplishing the task,” said Seepersad. This approach obviously differs from multiple choice exams and other tests where candidate answers are put in front of you. Often, certification programs involve online self-paced courses, so you can learn at your own speed, but the exams can be tough and require demonstration of expertise. That’s part of why the certifications that they lead to are valuable.
Certification options
Many people are familiar with the certifications offered by The Linux Foundation, including the Linux Foundation Certified System Administrator (LFCS) and Linux Foundation Certified Engineer (LFCE) certifications. The Linux Foundation intentionally maintains separation between its training and certification programs and uses an independent proctoring solution to monitor candidates. It also requires that all certifications be renewed every two years, which gives potential employers confidence that skills are current and have been recently demonstrated.
“Note that there are no prerequisites,” Seepersad said. “What that means is that if you’re an experienced Linux engineer, and you think the LFCE, the certified engineer credential, is the right one for you…, you’re allowed to do what we call ‘challenge the exams.’ If you think you’re ready for the LFCE, you can sign up for the LFCE without having to have gone through and taken and passed the LFCS.”
Seepersad noted that the LFCS credential is great for people starting their careers, and the LFCE credential is valuable for many people who have experience with Linux such as volunteer experience, and now want to demonstrate the breadth and depth of their skills for employers. He also said that the LFCS and LFCE coursework prepares trainees to work with various Linux distributions. Other certification options, such as the Kubernetes Fundamentals and Essentials of OpenStack Administration courses and exams, have also made a difference for many people, as cloud adoption has increased around the world.
Seepersad added that certification can make a difference if you are seeking a promotion. “Being able show that you’re over the bar in terms of certification at the engineer level can be a great way to get yourself into the consideration set for that next promotion,” he said.
Tips for Success
In terms of practical advice for taking an exam, Seepersad offered a number of tips:
Set the date, and don’t procrastinate.
Look through the online exam descriptions and get any training needed to be able to show fluency with the required skill sets.
Practice on a live Linux system. This can involve downloading a free terminal emulator or other software and actually performing tasks that you will be tested on.
Seepersad also noted some common mistakes that people make when taking their exams. These include spending too long on a small set of questions, wasting too much time looking through documentation and reference tools, and applying changes without testing them in the work environment.
With open source certification playing an increasingly important role in securing a rewarding career, stay tuned for more certification details in this article series, including how to prepare for certification.