I’m four months into the curriculum at Holberton School and we’ve solved multiple problems using the malloc, realloc, calloc and free functions in the C programming language. What better way to build a solid foundation of how memory gets allocated then to write a technical post on the stack versus the heap?
This article explains in depth:
What are the five segments of memory?
What is the stack?
What is the heap?
How does understanding the two make you a better software engineer?
What are the five segments of memory?
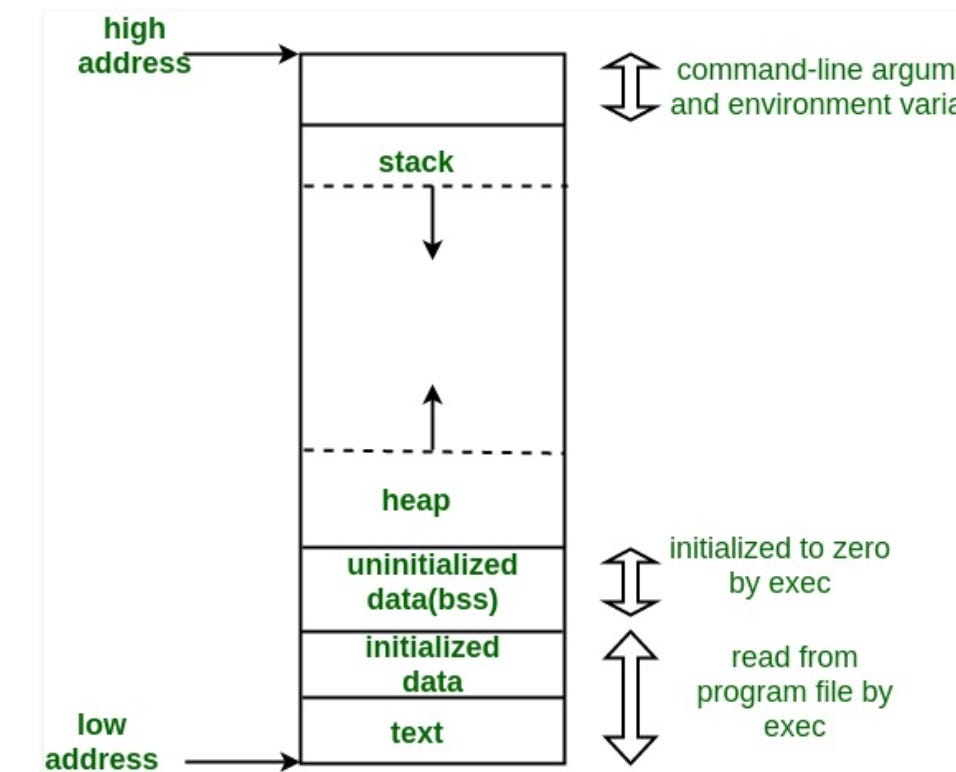
When we write applications, files, or any logic that is typed in an editor and executed on the computer, the computer has to allocate memory for the program to run. The memory that is assigned to a program or application in a computer can be divided into five parts. The amount of memory that get’s assigned to an application depends on the computer’s architecture and will vary across most devices, but the variable that remains constant is the five parts of an application’s memory which are the heap, stack, initialized data segment, uninitialized data segment, and the text segment.
The initialized data segmentconsists of all the global and static variables that are initialized when a file gets compiled. The uninitialized data segment consists of all global and static variables that are initialized to zero or do not have explicit initialization in source code.
At Holberton, most of the time we are not concerned about the uninitialized data segment because when we compile our programs with gcc, we use the flags, -Wall -Wextra -pedantic -Werror and we use an internal stylistic checker called betty which treats warning as errors when uninitialized variables are present. Having unused variables in our programs gets flagged and is not a best practice. The text segment, also known as the code segment, contains the machine instructions which make up your program. The text segment is often read-only and prevents a program from accidentally modifying its instructions.
What is the stack?
The stack is a segment of memory where data like your local variables and function calls get added and/or removed in a last-in-first-out (LIFO) manner. When you compile a program, the compiler enters through the main function and a stack frame is created on the stack. A frame, also known as an activation record is the collection of all data on the stack associated with one subprogram call. The main function and all the local variables are stored in an initial frame.
Program vs Stack usage
In the picture above, we have one stack frame on the stack that holds the main function, along with the local a, b and sum variables. After using the printf() function the frame we created along with the local variables are only accessible in memory for the duration of the frame are no longer accessible after returning the 0 value from the function.
What happens with the stack when we call multiple functions? To illustrate the stack in it’s LIFO manner, let’s solve a problem using recursion. When we call multiple functions in our application, we use multiple stack frames in a last-in-first-out approach meaning that the last stack frame we’ve created on the stack is the first stack that will be released after the function is done executing its logic. Let’s go over an example of printing out the name “Holberton” recursively and show how our code affects the stack memory segment.
Yes, I have a whiteboard on the back of my door at my house.
When we compile our code using gcc _putchar.c 0-puts_recursion.c 0-main.c , the compiler enters our program through int main(void) and creates a frame with the function int main(void) and _puts_recursion("Holberton") living on that frame as illustrated on the image above. When the compiler runs into the _puts_recursion() function, it calls that function and creates another stack frame on top of the previous stack frame where int main(void) lives. We are now in our second stack frame in our program and have entered in the _puts_recursion(char *s)function where *s is equal to 'H' and is only accessible in that stack frame. Because 'H' does not equal '�' , we will continue with our function calls and execute the _putchar('H') function and enter into the same function _puts_recursion(++s). The argument ++s moves the memory address of the *s one byte because the size of a char is 1 byte on our machine, and now _puts_recursion is calling the function as _puts_recrusion('o') . Each time the _puts_recursion function is called, a new stack frame is put on the stack until we hit the terminating condition which is if (*s == '�').
Every time a new stack frame is created, the stack pointer moves with it until it reaches the terminating condition. A stack pointer is a small register that stores the address of the last program request in a frame. When we hit the terminating condition, we execute our logic, then start to unwind the stack or pop off stack frames in the last-in-first-out manner until we reach out return(0) logic in the int main(void) function in our first stack frame.
If you don’t have a terminating case for the recursive example above, the stack will continue to grow in size adding additional stack frames on-top of each other, moving the stack pointer upward on each call, against the heap, which will be explained in the next section. In a recursive function , if there is no valid terminating condition, the stack will grow until you’ve completed consumed all the memory that’s been allocated for your program by the operating system. When the stack pointer exceeds the stack bound, you have a condition called stack overflow. Bad things happen when you have a stack overflow.
Let’s first refer back to the other four segments of your application’s memory which were the uninitialized and initialized data segments, text segment and stack segment. These four segments have a constant memory size during compilation. The memory size for these four segments is predetermined by your operating system before compiling your programs. When software engineers write programs that consume large amounts of memory from a machine, they have to consider where and how much memory is being consumed in their application.
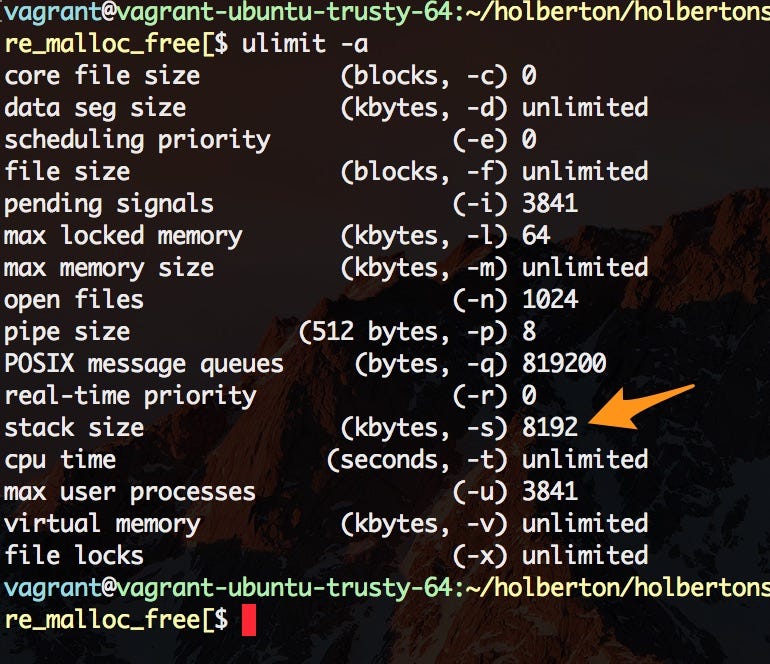
The max stack size is constant and predetermined before a program is compiled. At Holberton, we use a Linux Ubuntu/Trusty64 distributions. To find information about the stack size and other neat limits, type the command below into your terminal.
ulimit -a
Where ulimit is a function that gets and sets user limits and the -a flag lists all the current limits.
Stack size is 8.192MB of memory.
If the stack is limited in size and a program needs more memory for it to execute, where can a software engineer pull memory from for his/her application? This is where the heap comes into play.
What is the heap?
The heap is the segment of memory that is not set to a constant size before compilation and can be controlled dynamically by the programmer. Think of the heap as a “free pool” of memory you can use when running your application. The size of the heap for an application is determined by the physical constraints of your RAM (Random access memory) and is generally much larger in size than the stack.
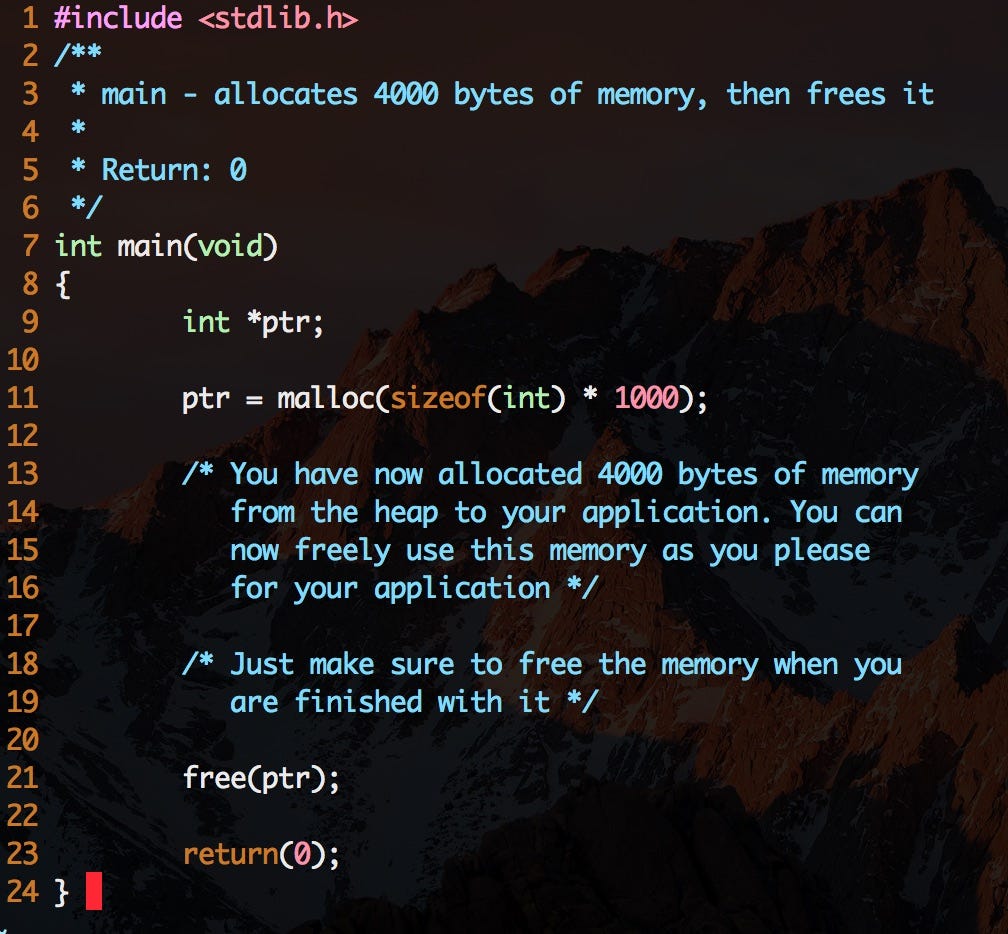
We use memory from the heap when we don’t know how much space a data structure will take up in our program, when we need to allocate more memory than what’s available on the stack, or when we need to create variables that last the duration of our application. We can do that in the C programming language by using malloc, realloc, calloc and/or free. Check out the example below.
Allocating 4000 bytes of memory to our program, then releasing it.
We allocate memory from the heap using the malloc() function. The argument we want to include in malloc is the amount of memory we want to allocate to our application, in bytes. Malloc returns a void pointer that is type casted into an integer pointer that now points to the first address in memory for our 4000 byte long memory. We can now store information in those memory addresses and do as we please to that information for the duration of our program or for the duration of our function because we have a pointer that references the first memory address from the newly allocated heap memory.
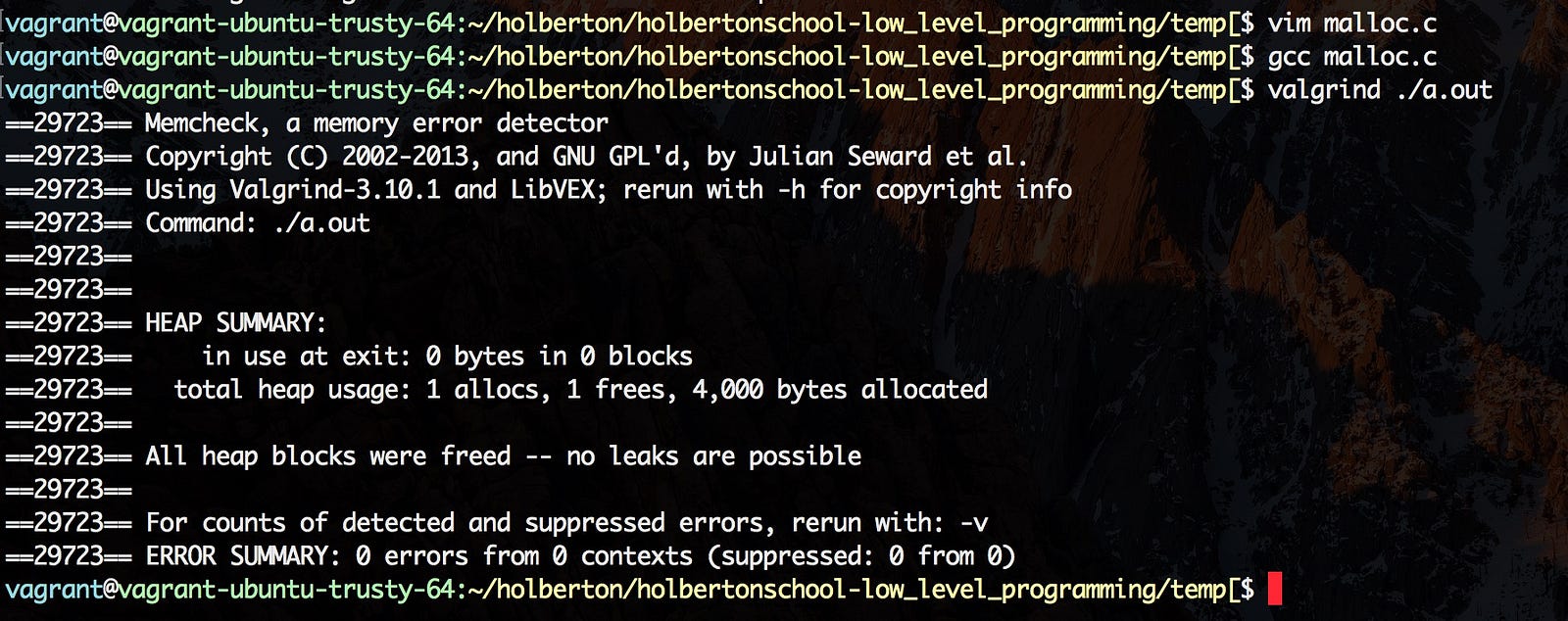
If you aren’t intentionally creating variables that last the duration of your application from the heap, you always want to release the memory back to the machine using the free() function. If you don’t release the memory using the free() function, you have memory that will persist throughout your program. If we do not release the memory from our program before terminating the application, our application has memory leaks. If your application has enough memory leaks, it can consume more memory than is physically available and can cause programs to crash. This is why we use a program called valgrind. Valgrind is easy to use and checks for memory leaks.
Valgrind being used. 4,000 bytes allocated. 0 bytes leaks
Another thing to consider while using the heap, the pointer variables created on the heap are accessible by any function, anywhere in your program, as long as the memory is still persistent and hasn’t been free.
How does understanding the stack and heap make you a better software engineer?
If you understand the advantages and disadvantages of using the stack vs the heap for your application, then it gives you a strategic advantage for creating scalable programs. You, the programmer, have to decide when to use memory from the stack vs heap based on each problem you are trying to solve.
If you have a variable like an array or struct that needs to be stored in a large block memory, needs to persist throughout the lifetime of your application and could change in size throughout the duration of your program, then you should allocate it from the heap.
If you need to create helper functions with variables that only persist within the lifetime of the function, then you should allocate memory from the stack. Memory from the stack is easier to keep track of because the memory is only locally available in the function call which does not persist after the function is completed and is managed by the CPU.
Photo credit: Gribble Lab
Questions, comments or concerns, feel free to comment below, follow me or find me on Twitter @ NTTL_LTTN.
References:
My Code School. (February 23rd, 2013). Pointers and dynamic memory — stack vs heap. . Retrieved from https://www.youtube.com/watch?v=_8-ht2AKyH4
Paul Gribble (2012). C Programming Boot Camp — 7. Memory: Stack vs Heap. [Blog post]. Retrieved from https://www.gribblelab.org/CBootCamp/7_Memory_Stack_vs_Heap.html#orgheadline1
GeeksforGeeks. Memory Layout of C Programs. [Blog post]. Retrieved from https://www.geeksforgeeks.org/memory-layout-of-c-program/
Sandra Henry-Stocker. (November 18th, 2012). NETWORK WORLD — Setting limits with ulimit. [Blog post]. Retrieved from https://www.networkworld.com/article/2693414/operating-systems/setting-limits-with-ulimit.html
Valgrind Developers (2000–2017). Valgrind. Retrieved from http://valgrind.org/
Die.net Linux Documentation. Retrieved from https://linux.die.net/
This article was produced in partnership with Holberton School and originally appeared on Medium.