

I remember, long, long ago, when installing apps in Linux required downloading and compiling source packages. If you were really lucky, some developer might have packaged the source code into a form that was more easily installable. Without those developers, installing packages could become a dependency nightmare.
But then, package managers like rpm and dpkg began to rise in popularity, followed quickly by the likes of yum and apt. This was an absolute boon to anyone looking to make Linux their operating system of choice. Although dependencies could still be an issue, they weren’t nearly as bad as they once were. In fact, many of these package managers made short shrift of picking up all the dependencies required for installation.
And the Linux world rejoiced! Hooray!
But, with those package managers came a continued requirement of the command line. That, of course, is all fine and good for old hat Linux users. However, there’s a new breed of Linux users who don’t necessarily want to work with the command line. For that user-base, the Linux “app store” was created.
This all started with the Synaptic Package Manager. This graphical front end for apt was first released in 2001 and was a breath of fresh air. Synaptic enabled user to easily search for a piece of software and install it with a few quick clicks. Dependencies would be picked up and everything worked. Even when something didn’t work, Synaptic included the means to fix broken packages—all from a drop-down menu.
Since then, a number of similar tools have arrived on the market, all of which improve on the usability of Synaptic. Although Synaptic is still around (and works quite well), new users demand more modern tools that are even easier to use. And Linux delivered.
I want to highlight three of the more popular “app stores” to be found on various Linux distributions. In the end, you’ll see that installing applications on Linux, regardless of your distribution, doesn’t have to be a nightmare.
GNOME Software
GNOME’s take on the graphical package manager, Software, hit the scene just in time for the Ubuntu Software Center to finally fade into the sunset (which was fortuitous, considering Canonical’s shift from Unity to GNOME). Any distribution that uses GNOME will include GNOME Software. Unlike the now-defunct Ubuntu Software Center, GNOME Software allows users to both install and update apps from within the same interface (Figure 1).
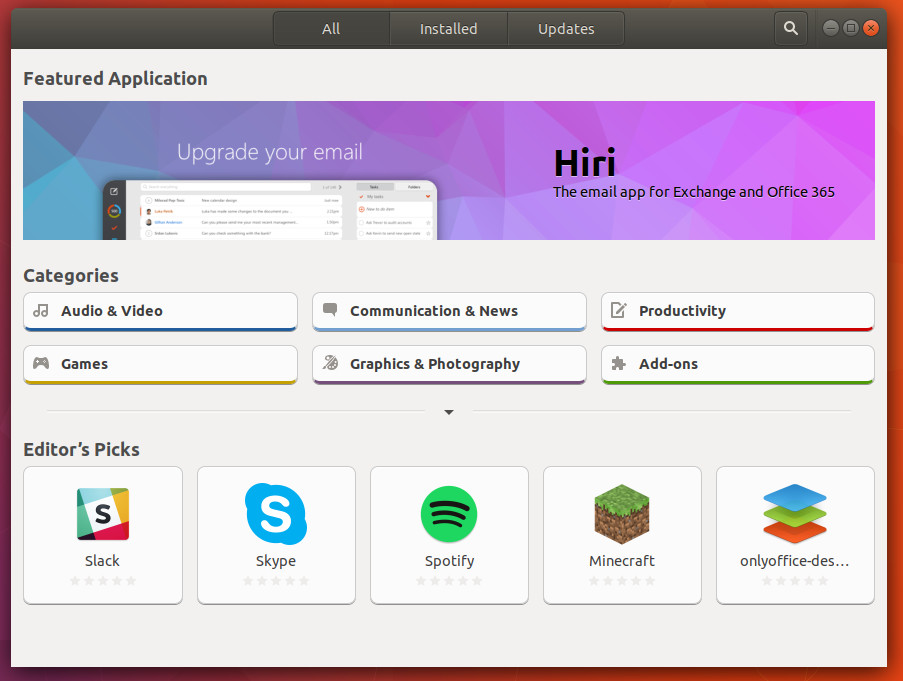
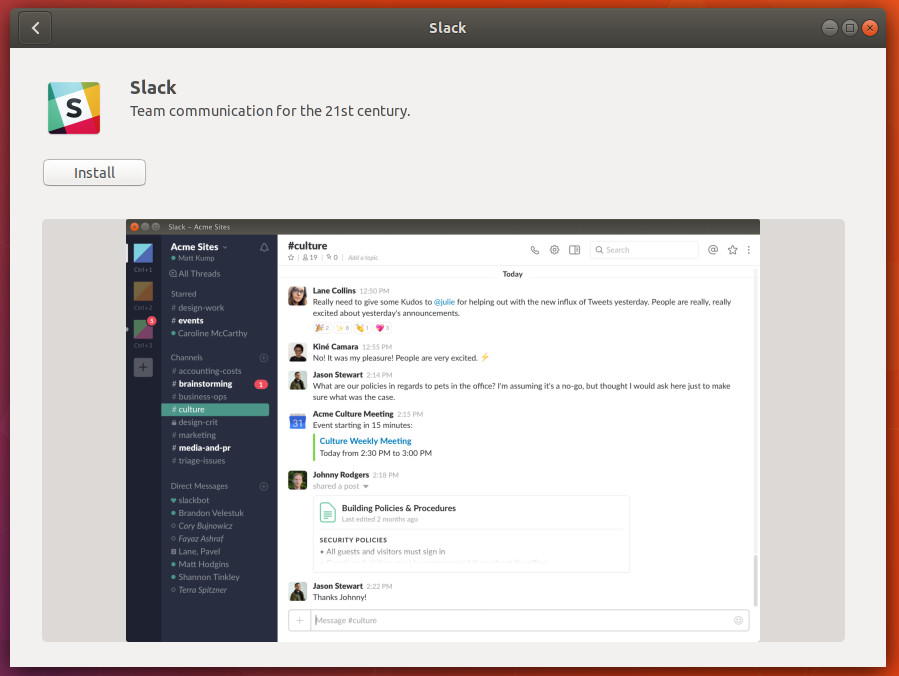
To find a piece of software to install, click the Search button (top left, looking glass icon), type the name of the software you want to install, and wait for the results. When you find a title you want to install, click the Install button (Figure 2) and, when prompted, type your user (sudo) password.
GNOME Software also includes easy to navigate categories, Editor’s Picks, and GNOME add-ons. As a bonus feature, GNOME Software also supports both snaps and flatpak software. Out of the box, GNOME Software on Ubuntu (and derivatives) support snaps. If you’re adventurous, you can add support for flatpak by opening a terminal window and issuing the command sudo apt install gnome-software-plugin-flatpak.
GNOME Software makes it so easy to install software on Linux, any user (regardless of experience level) can install and update apps with zero learning curve.
KDE Discover
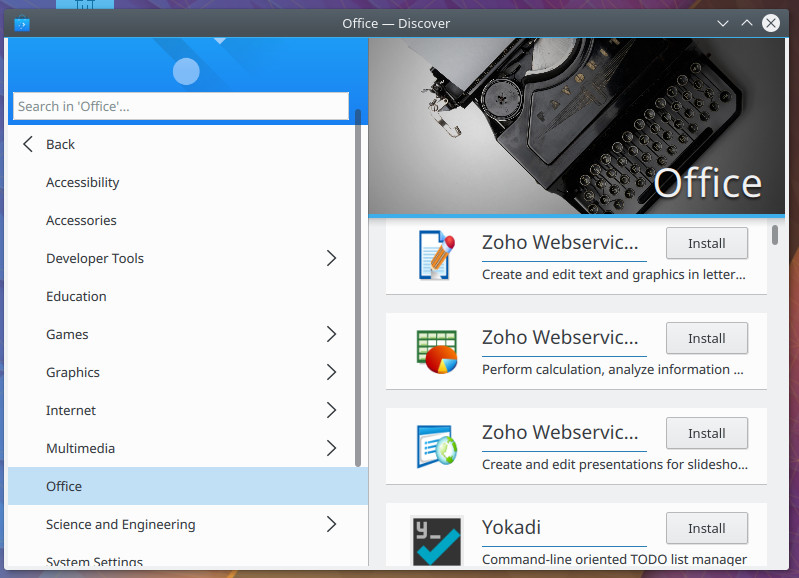
Discover is KDE’s answer to GNOME Software. Although the layout (Figure 3) is slightly different, Discover should feel immediately familiar.
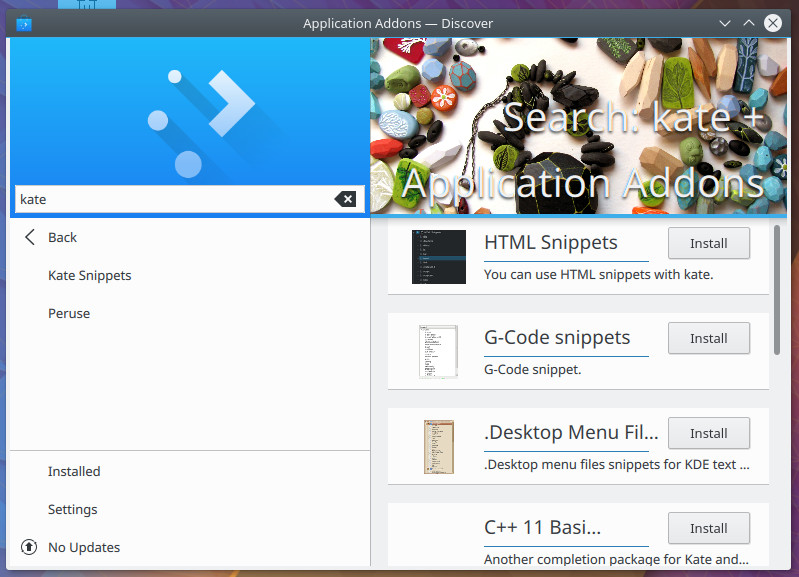
One of the primary differences between Discover and Software is that Discover differentiates between Plasma (the KDE desktop) and application add-ons. Say, for example, you want to find an “extension” for the Kate text editor; click on Application Addons and search “kate” to see all available addons for the application.
The Plasma Addons feature makes it easy for users to search through the available desktop widgets and easily install them.
The one downfall of KDE Discover is that applications are listed in a reverse alphabetical order. Click on one of the given categories, from the main page, and you’ll be given a listing of available apps to scroll through, from Z to A (Figure 4).
You will also notice no apparent app rating system. With GNOME Software, it’s not only easy to rate a software title, it’s easy to decide if you want to pass on an app or not (based on a given rating). With KDE Discover, there is no rating system to be found.
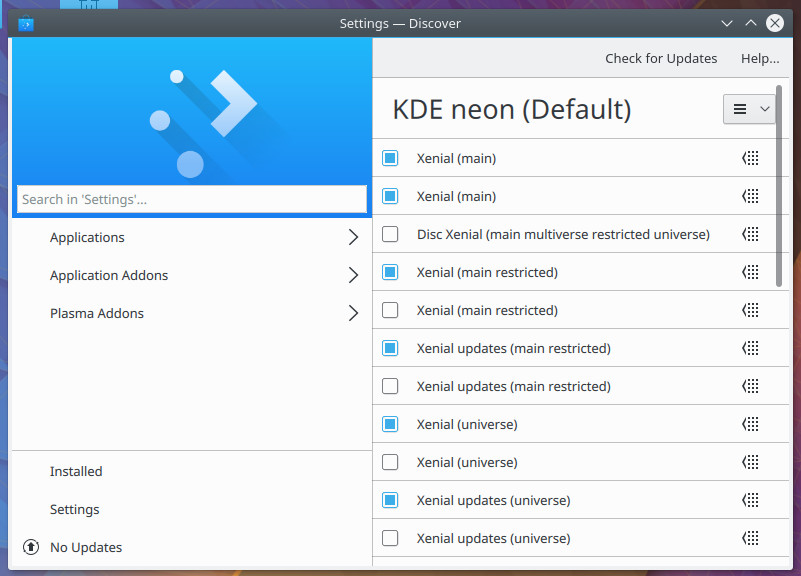
One bonus that Discover adds, is the ability to quickly configure repositories. From the main window, click on Settings, and you can enable/disable any of the included sources (Figure 5). Click the drop-down in the upper right corner, and you can even add new sources.
Pamac
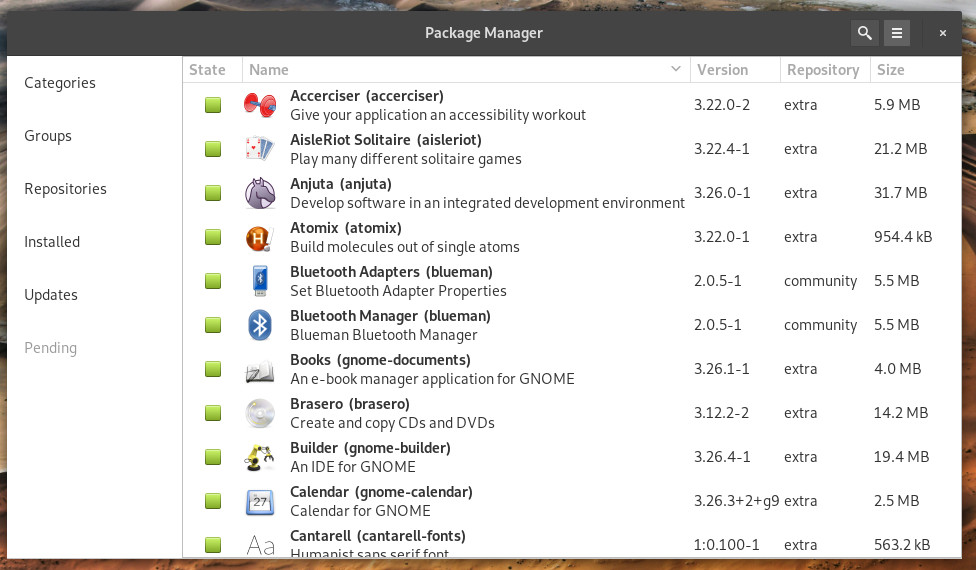
If you’re hoping to soon count yourself among the growing list of Arch Linux users, you’ll be glad to know that the Linux distribution often considered for the more “elite”, also includes a graphical package manager. Pamac does an outstanding job of making installing applications on Arch easy. Although Pamac isn’t quite on the design level of either GNOME Software or KDE Discover, it still does a great job of simplifying the installing and updating of applications. From the Pamac main window (Figure 6), you can either click on the search button, or click a Category or Group to find the software you’re looking to install.
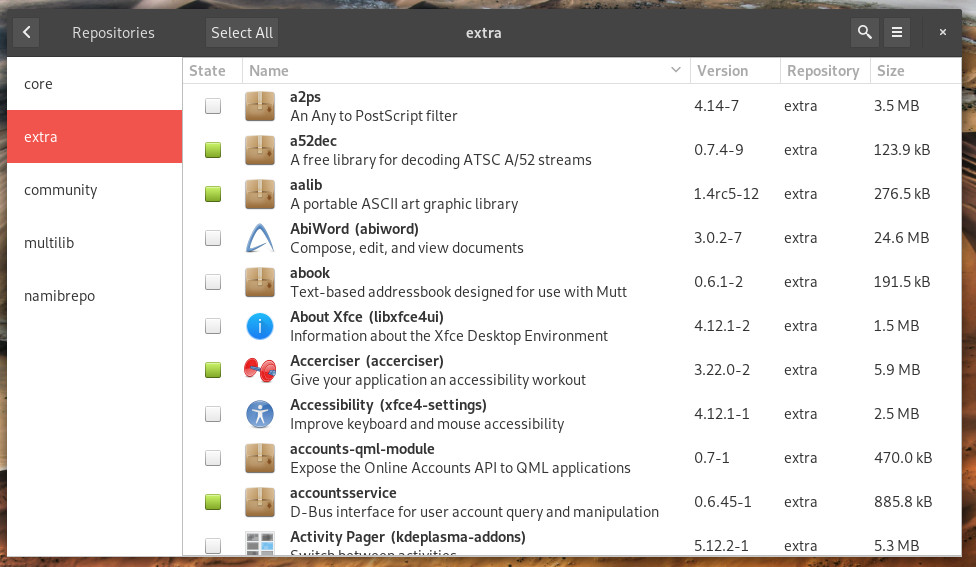
If you can’t find the software you’re looking for, you might need to enable one of the many repositories. Click on the Repository button and then search through the categories (Figure 7) to locate the repository to be added.
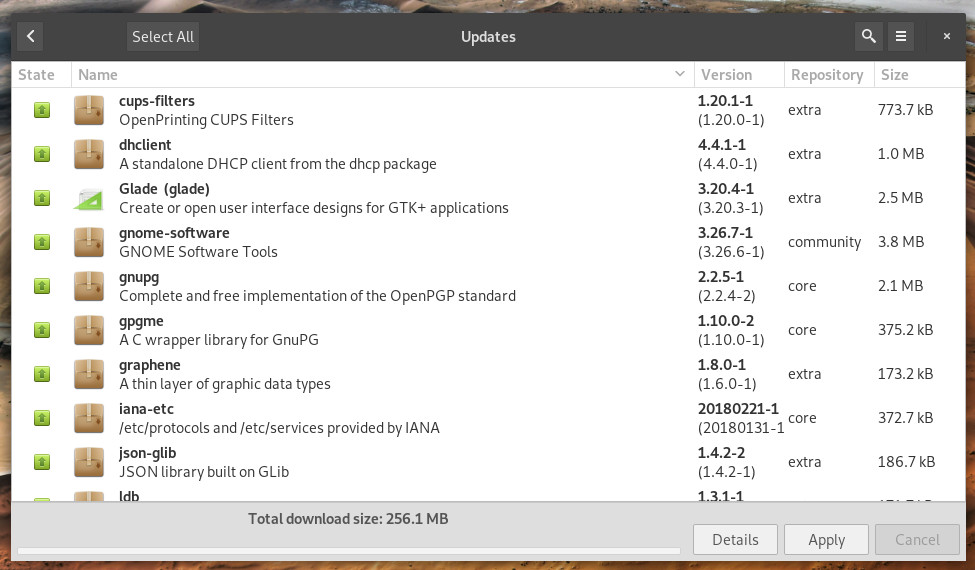
Updates are smoothly handled with Pamac. Click on the Updates button (in the left navigation) and then, in the resulting window (Figure 8), click Apply. All of your Arch updates will be installed.
More where that came from
I’ve only listed three graphical package managers. That is not to say these three are the only options to be found. Other distributions have their own takes on the package manager GUI. However, these three do an outstanding job of representing just how far installing software on Linux has come, since those early days of only being able to install via source.
Learn more about Linux through the free “Introduction to Linux” course from The Linux Foundation and edX.






