It seems that every application out there is hungry for an API. Let’s look at Yelp for example. Yelp by itself won’t have the functionality you’d expect. In order to search nearby restaurants or locations, it needs to use an API for a map. It uses the Google API. With that, you can locate nearest places and get directions to the place. APIs allow you to integrate one tool to another tool to give it more functionality. Without the ability to make these types of integrations, you can say goodbye to a majority of all these softwares and apps out there that you use!
Last week, we learned about LAN (local area network) hardware. This week, we’ll learn about connecting networks to each other, and some cool hacks for mobile broadband.
Routers
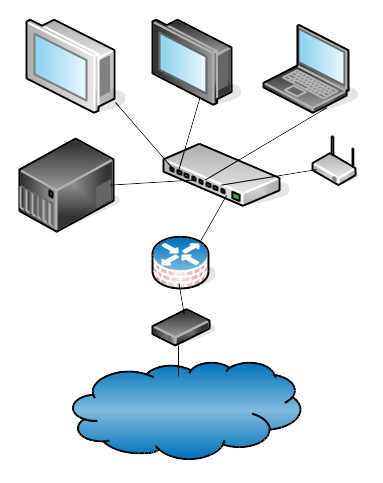
Network routers are everything in computer networking, because routers connect networks. Without routers we would be lonely little islands. Figure 1 shows a simple wired LAN (local area network) with a wireless access point, all connected to the Internet. Computers on the LAN connect to an Ethernet switch, which connects to a combination firewall/router, which connects to the big bad Internet through whatever interface your Internet service provider (ISP) provides, such as cable box, DSL modem, satellite uplink…like everything in computing, it’s likely to be a box with blinky lights. When your packets leave your LAN and venture forth into the great wide Internet, they travel from router to router until they reach their destination.
Figure 1 shows a simple wired LAN (local area network) with a wireless access point, all connected to the Internet.
A router can look like pretty much anything: a nice little specialized box that does only routing and nothing else, a bigger box that provides routing, firewall, name services, and VPN gateway, a re-purposed PC or laptop, a Raspberry Pi or Arduino, stout little single-board computers like PC Engines…for all but the most demanding uses, ordinary commodity hardware works fine. The highest-end routers use specialized hardware that is designed to move the maximum number of packets per second. They have multiple fat data buses, multiple CPUs, and super-fast memory. (Look up Juniper and Cisco routers to see what high-end routers look like, and what’s inside.)
A wireless access point connects to your LAN either as an Ethernet bridge or a router. A bridge extends the network, so hosts on both sides of the bridge are on the same network. A router connects two different networks.
Network Topology
There are multitudes of ways to set up your LAN. You can put all hosts on a single flat network. You can divide it up into different subnets. You can divide it into virtual LANs, if your switch supports this.
A flat network is the simplest; just plug everyone into the same switch. If one switch isn’t enough you can connect switches to each other. Some switches have special uplink ports, some don’t care which ports you connect, and you may need to use a crossover Ethernet cable, so check your switch documentation.
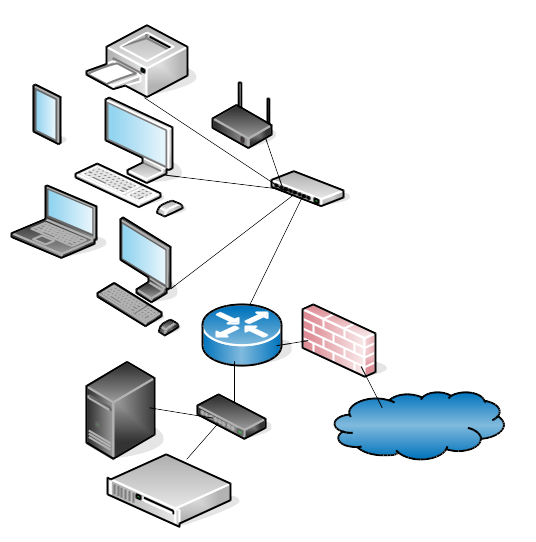
Flat networks are the easiest to administer. You don’t need routers and don’t have to calculate subnets, but there are some downsides. They don’t scale, so when they get too large they get bogged down by broadcast traffic. Segmenting your LAN provides a bit of security, and makes it easier to manage larger networks by dividing it into manageable chunks. Figure 2 shows a simplified LAN divided into two subnets: internal wired and wireless hosts, and one for servers that host public services. The subnet that contains the public-facing servers is called a DMZ, demilitarized zone (ever notice all the macho terminology for jobs that are mostly typing on a computer?) because it is blocked from all internal access.
Figure 2: A simplified LAN divided into two subnets.
Even in a network as small as Figure 2 there are several ways to set it up. You can put your firewall and router on a single device. You could have a dedicated Internet link for the DMZ, divorcing it completely from your internal network. Which brings us to our next topic: it’s all software.
Think Software
You may have noticed that of the hardware we have discussed in this little series, only network interfaces, switches, and cabling are special-purpose hardware. Everything else is general-purpose commodity hardware, and it’s the software that defines its purpose. Linux is a true networking operating system, and it supports a multitude of network operations: VLANs, firewall, router, Internet gateway, VPN gateway, Ethernet bridge, Web/mail/file/etc. servers, load-balancer, proxy, quality of service, multiple authenticators, trunking, failover…you can run your entire network on commodity hardware with Linux. You can even use Linux to simulate an Ethernet switch with LISA (LInux Switching Appliance) and vde2.
There are specialized distributions for small hardware like DD-WRT, OpenWRT, and the Raspberry Pi distros, and don’t forget the BSDs and their specialized offshoots like the pfSense firewall/router, and the FreeNAS network-attached storage server.
You know how some people insist there is a difference between a hardware firewall and a software firewall? There isn’t. That’s like saying there is a hardware computer and a software computer.
Port Trunking and Ethernet Bonding
Trunking and bonding, also called link aggregation, is combining two Ethernet channels into one. Some Ethernet switches support port trunking, which is combining two switch ports to combine their bandwidth into a single link. This is a nice way to make a bigger pipe to a busy server.
You can do the same thing with Ethernet interfaces, and the bonding driver is built-in to the Linux kernel, so you don’t need any special hardware.
Bending Mobile Broadband to your Will
I expect that mobile broadband is going to grow in the place of DSL and cable Internet. I live near a city of 250,000 population, but outside the city limits good luck getting Internet, even though there is a large population to serve. My little corner of the world is 20 minutes from town, but it might as well be the moon as far as Internet service providers are concerned. My only option is mobile broadband; there is no dialup, satellite Internet is sold out (and it sucks), and haha lol DSL, cable, or fiber. That doesn’t stop ISPs from stuffing my mailbox with flyers for Xfinity and other high-speed services my area will never see.
I tried AT&T, Verizon, and T-Mobile. Verizon has the strongest coverage, but Verizon and AT&T are expensive. I’m at the edge of T-Mobile coverage, but they give the best deal by far. To make it work, I had to buy a weBoost signal booster and ZTE mobile hotspot. Yes, you can use a smartphone as a hotspot, but the little dedicated hotspots have stronger radios. If you’re thinking you might want a signal booster, I have nothing but praise for weBoost because their customer support is superb, and they will do their best to help you. Set it up with the help of a great little app that accurately measures signal strength, SignalCheck Pro. They have a free version with fewer features; spend the two bucks to get the pro version, you won’t be sorry.
The little ZTE hotspots serve up to 15 hosts and have rudimentary firewalls. But we can do better: get something like the Linksys WRT54GL, replace the stock firmware with Tomato, OpenWRT, or DD-WRT, and then you have complete control of your firewall rules, routing, and any other services you want to set up.
Learn more about Linux through the free “Introduction to Linux” course from The Linux Foundation and edX.
NIST recently published its four-volume SP800-63-3 Digital Identity Guidelines. Among other things, it makes three important suggestions when it comes to passwords:
Stop it with the annoying password complexity rules. They make passwords harder to remember. They increase errors because artificially complex passwords are harder to type in.
As developers, we often hear that tests are important. Automated testing minimizes the number of bugs released to production, helps prevent regression, improves code quality, supplements documentation, and makes code reviews easier. In short, tests save businesses money by increasing system uptime and keeping developers working on new features instead of fighting fires. While software testing has been around for about as long as software has, I would argue that testing is especially important (and unfortunately more challenging) in modern distributed software systems.
“Distributed software” refers to any software that is not run entirely on one computer. Almost all web applications are distributed software as they rely on applications on other servers (eg: remote data stores, internal REST APIs, third-party APIs, content delivery networks, etc.), and most mobile and desktop applications are as well. Distributed software presents new challenges and requires a thoughtful approach to testing.
I’ll be presenting a strategy for testing distributed systems at this year’s API Strategy & Practice Conference. If you’re interested in learning more about the topic of testing distributed software, or you have questions, you can find me at the conference, or anytime on Twitter.
MEF and the Open Network Automation Platform (ONAP) are officially working together, the organizations announced today at the SDN and NFV World Congress. MEF has joined ONAP as an associate member. And the Linux Foundation, which hosts ONAP, has joined MEF as an auditing member.
Arpit Joshipura, general manager of networking and orchestration with the Linux Foundation, told SDxCentral this will help enterprises that offer services across more than one service provider’s network.
DevOps is defined as “unifying the operations and engineering teams,” in order to foster a culture of cross-team collaboration, codify how infrastructure is built, and become a more data-driven organization. But it seems databases and the teams that care for them are treated as an exception to this environment. In most companies, databases are still treated like walled gardens, with the database hosts tended to like delicate flowers and the database administrators (DBAs) guarding any and all access to them.
This walled-garden attitude invariably affects the rest of the organization, from tech ops, to delivery engineering, all the way to product planning, as everyone tries to work around the datastore. Ultimately this reduces the benefits of an agile approach to software development, which is a problem for companies that have been running for a few years and have reached a solid financial footing with loyal paying customers, but are having a hard time shedding that startup skin (the one that flies by the seat of its pants), and are feeling the pressure to achieve a sense of stability in existing and future offerings.
The big news this week is that Intel has been able to take a qubit design that its engineers created alongside of those working at QuTech and scale it up to 17 qubits on a single package. A year ago, the Intel-QuTech partnership had only a few qubits on their initial devices, Jim Clarke, director of quantum hardware at Intel, tells The Next Platform, and two years ago it had none. So that is a pretty impressive roadmap in a world where Google is testing a 20 qubit chip and hopes to have one running at 49 qubits before the year is out.
“We are trying to build a general purpose, universal quantum computer,” says Clarke. “This is not a quantum annealer, like the D-Wave machine. There are many different types of qubits, which are the devices for quantum computing, and one of the things that sets Intel apart from the other players is that we are focused on multiple qubit types. …”
The Linux community works, it turns out, because the Linux community isn’t too concerned about work, per se. As much as Linux has come to dominate many areas of corporate computing – from HPC to mobile to cloud – the engineers who write the Linux kernel tend to focus on the code itself, rather than their corporate interests therein.
Such is one prominent conclusion that emerges from Dawn Foster’s doctoral work, examining collaboration on the Linux kernel. Foster, a former community lead at Intel and Puppet Labs, notes, “Many people consider themselves a Linux kernel developer first, an employee second.”
As Foster writes, “Even when they enjoy their current job and like their employer, most [Linux kernel developers] tend to look at the employment relationship as something temporary, whereas their identity as a kernel developer is viewed as more permanent and more important.”
Because of this identity as a Linux kernel developer first, and corporate citizen second, Linux kernel developers can comfortably collaborate even with their employer’s fiercest competitors. This works because the employers ultimately have limited ability to steer their developers’ work…
We all use metadata everyday. You may have found this blog post through a search, leveraging metadata tags / keywords. Metadata allows data practitioners to use data outside the application that created it, find the right data sets, and automate governance processes. Metadata today has proven value, yet many data platforms do not have metadata support.
Furthermore, where metadata management exists it uses proprietary formats and APIs. Proprietary tools support a limited range of data sources and governance actions, and it can be an expensive efforts to combine their metadata create an enterprise data catalogue. In an ideal world, metadata should have the ability to be moved with the data and be augmented and processed through open APIs for permitted usages.
Enter Open Metadata, which enables various tools to connect to data & metadata repositories to exchange metadata.
Open Metadata has two major parts:
OMRS – Open Metadata Repository Services makes it possible for various metadata repositories to exchange metadata. Metadata repositories can be from various vendors or concern with specific subject area.
OMAS – Open Metadata Access Services provides specialized services to various types of tools/applications and thus enable out of the box connection to metadata. These tools can be, but not limited to:
BI and Visualization tools
Governance tools
Integration tools and engines such as ETL and information virtualisation
The OMAS enables subject matter experts to collaborate around the data, feeding back their knowledge about the data and the uses they have made about it to help others and support economic evaluation of data.
Open Metadata aims to provide data practitioners with an enterprise data catalog that lists all of their data, where it is located, its origin (lineage), owner, structure, meaning, classification and quality. No matter where the data resides. Furthermore, new tools from any vendor would be able to connect to your data catalog out of the box. No vendor lock-in and no expensive population of yet another proprietary, siloed metadata repository. Additionally, Metadata would be added automatically to the catalogue as new data is created.
But how do you ensure consistency, no vendor lock-in and cost effectiveness of Open Metadata? The Answer is Open Governance.
Open Governance enables automation of metadata capture and governance of data. Open governance includes 3 frameworks:
Open Connector Framework (OCF) for metadata driven access to data assets.
Open Discovery Framework (ODF) for automated analysis of data and advanced metadata capture.
Governance Action Framework (GAF) for automated governance enforcement, verification, exception management and logging.
Open Metadata and Open Governance together allows metadata to be captured when the data is created, moved with the data and be augmented and processed by any of the vendor tools.
Open Metadata and Governance consists of:
Standardized, extensible set of metadata types
Metadata exchange APIs and notifications
Frameworks for automated governance
Open Metadata and Governance will allow you to have:
An enterprise data catalogue that lists all of your data, where it is located, its origin (lineage),
owner, structure, meaning, classification and quality
New data tools (from any vendor) connect to your data catalogue out of the box
Metadata being added automatically to the catalogue as new data is created and analysed
Subject matter experts collaborating around the data
Automated governance processes protect and manage your data
Dive into this topic further on Oct. 12 for a free webinar as John Mertic, Director of ODPi at The Linux Foundation hosts Srikanth Venkat, Senior Director, Product Management at Hortonworks, Ferd Scheepers, Chief Information Architect at INGand Mandy Chessell, Distinguished Engineer and Master Inventor at IBM.
Cloud Foundry, the open-source platform as a service (PaaS) offering, has become somewhat of a de facto standard in the enterprise for building and managing applications in the cloud or in their own data centers. The project, which is supported by the Linux Foundation, is announcing a number of updates at its annual European user conference this week. Among these are support for container workloads and a new marketplace that highlights the growing Cloud Foundry ecosystem.
Cloud Foundry made an early bet on Docker containers, but with Kubo, which Pivotal and Google donated to the project last year, the project gained a new tool for allowing its users to quickly deploy and manage a Kubernetes cluster (Kubernetes being the Google-backed open-source container orchestration tool that itself is becoming the de facto standard for managing containers).