

What happens when you take Ubuntu 17.10, a new desktop interface (one that overlays on top of KDE), snap packages, and roll them all up into a pseudo rolling release? You get Nitrux. At first blush, this particular Linux distribution seems more of an experiment than anything else — to show how much the KDE desktop can be tweaked to resemble the likes of the Elementary OS or MacOS desktops. At its heart, however, it’s much more than that.
First and foremost, Nitrux makes use of snap packages; so installing software is handled a bit differently than the norm. Even though Nitrux is based on Ubuntu, apt install isn’t what you want to use (although it is available).
I’m getting ahead of myself. This distro focuses very much on the GUI — so the GUI should be the route you take. Good thing Nitrux includes a GUI software installer tool for that purpose. That Nitrux uses snaps is good and bad, and it’s the bad that will put users off faster than the good.
Again, I’m getting ahead of myself.
Let’s first talk about what Nitrux is. This particular take on the Linux desktop is focused on the portable, universal nature of snap packages and makes use of a unique desktop, called Nomad, which sits atop KDE Plasma 5. It’s minimum requirements are:
-
2.66 GHz quad-core CPU or better.
-
4 GB system memory.
-
256 MB video memory and OpenGL 2.0 support.
-
4.29 GB of free hard drive space.
On that 4.29GB of free hard drive space, I installed Nitrux as a VirtualBox VM with 10GB of space. Upon installation, I installed the LibreOffice snap package, only to find out I was then out of space. I don’t know about you, but no LibreOffice installation I’ve ever done takes 5GB of space. I say this, only so you’ll be aware, should you opt to text Nitrux via VirtualBox—give that virtual disk about 20GB of space.
The Nomad desktop (Figure 1), will feel instantly familiar.
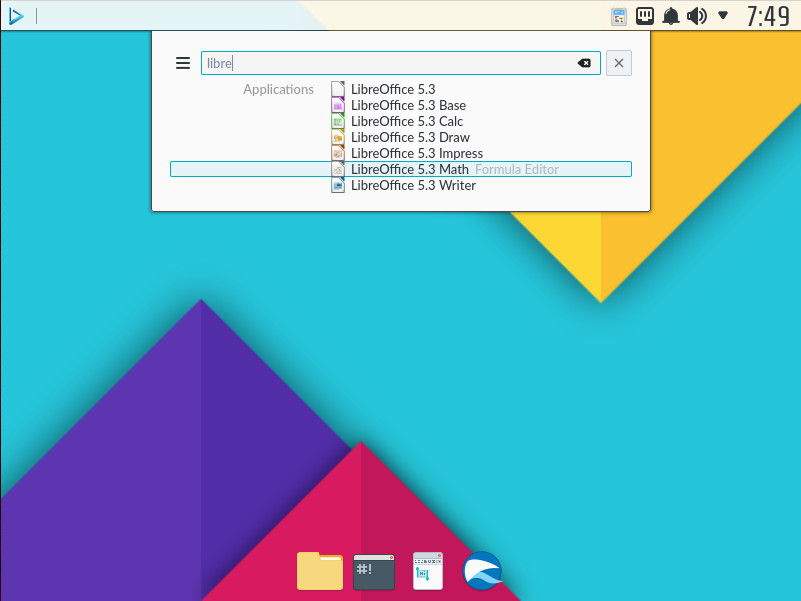
The desktop includes a dock, a system/notification tray, a quick search tool (Plasma Search), and an app menu. Of all the elements on the desktop, it’s the Plasma Search tool that will appeal to anyone looking for an efficient means to interact with their desktops. With this tool, you can just start typing on a blank desktop to see a list of results. Say, for example, you want to open LibreOffice writer; on the blank desktop, just start typing “libre” and related entries will appear (Figure 2).
The search feature is also capable of enabling/disabling various plugins, to add extra functionality. For example, you can include Bookmarks, web shortcuts, terminal applications, power management, and more to the desktop search (this is done through System Settings > Search > Plasma Search).
Take a step back
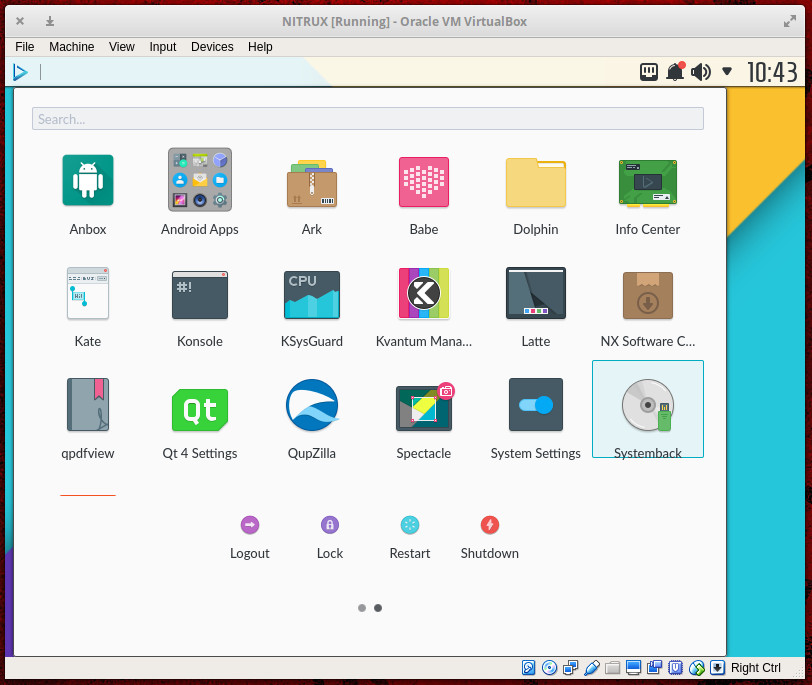
Although the Nitrux desktop might well be something every new user (even to Linux) could get up to speed with quickly, getting to the point of usage can be a bit confusing. Why? First off, when booting up the live instance, you are asked for a password, but never told what it is. Said password, for the Live user nitrux, is nitrux. Beyond that, the operating system installer is not what you might be used to. Instead of including an “Install Nitrux” button on the Live desktop, there’s absolutely no indication as to what one should do to install the platform. Turns out, Nitrux uses Systemback for installation. Once you have the live instance up and running, click on the desktop menu and locate the Systemback entry (Figure 3).
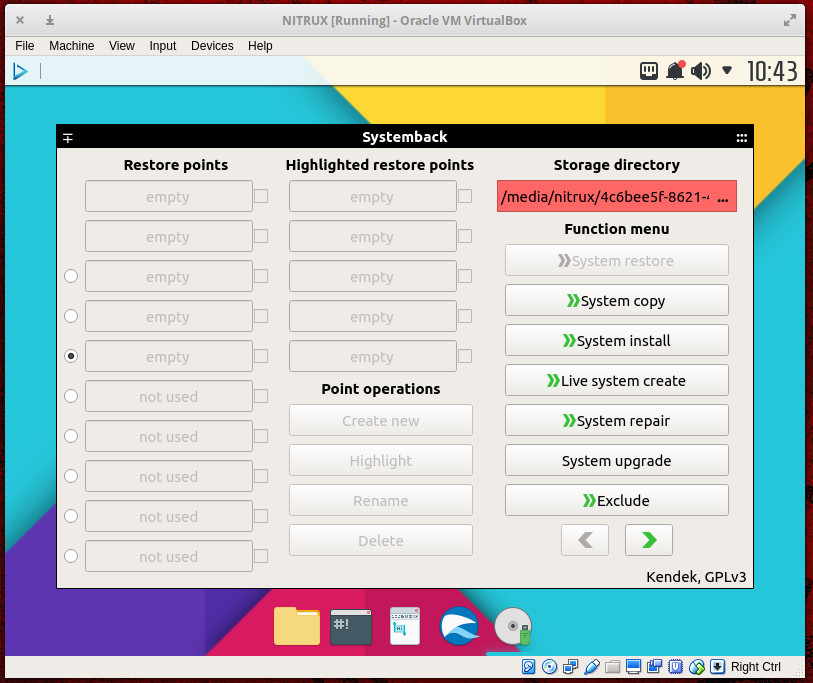
The one downfall of using Systemback is it is not nearly as intuitive as many other live distro installers. Once you start the tool up, you must click System install (Figure 4).
The first interactive section of the Systemback System installer is simple: you enter your user information. It’s the the next screen — for disk partitioning — that will trip up most users. Although Systemback will autodetect a partition, you have to delete it and create a new one, because the Mount point drop-down is greyed out. It isn’t until you delete the autodetected partition and create a new partition that you can select the mount point and file system type (Figure 5).
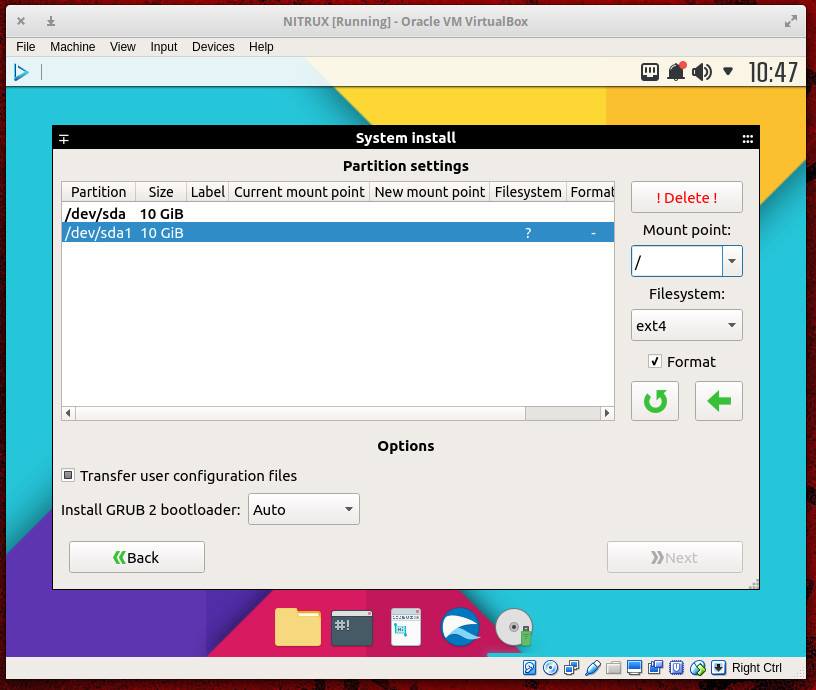
Here’s where we have to dock Systemback another point in user-friendliness. Once you’ve selected a mount point and filesystem type, you then have to click on the left-pointing green arrow to apply the settings. Why not a simple Apply Changes button? With that complete, you’ll then be able to click the Next button, so the installation can continue and complete.
I cannot imagine how many instances of Linux I have installed over the years, dating back to the late 1990s. Even with those early iterations of Linux, I must confess, this one had me dumbfounded. No, it’s not impossible—not even slightly; but with a desktop as user-friendly as Nomad, I wonder why the developers opted to make use of a platform installer that will most likely leave new users scratching their heads and, quite possibly, giving up. That is a shame, as Nitrux is certainly something to be experienced.
A step forward
The idea of making use of snap packages is intriguing, one that would allow for:
-
Developers to deliver the latest version of their app
-
App isolation and confinement, which improves the security and reliability said app
The biggest downfall (for the moment) is that not every Linux package has been rolled into a snap. For instance, my favorite audio player, Clementine, has yet to find its way to a snap package. The über-popular Audacity audio recorder doesn’t have a snap package. The list goes on and on.
The good news is, if there’s a piece of software that doesn’t yet have a snap, it can be installed by way of the usual means (i.e., sudo apt install clementine). That means anyone using Nitrux won’t be severely limited to what software they have available to them. However, that does sort of defeat the purpose of using snap packages. When possible, at least with Nitrux, always install with snap packages.
One other feature of note is the inclusion of Android apps (Figure 6).
From what it seems, users might be able to install and run Android applications. However, on two different installations, I have yet to get this feature to work. Even the pre-installed Android apps never start. What promised to be a really cool out of the box experience, fell flat.
Who is this distro for?
That’s a tough question. New users would feel right at home on the Nomad desktop — getting there, however, could be problematic. Skilled Linux users should have no problem using Nitrux and might find themselves intrigued with the snap-centric Nomad desktop. The one advantage of having a distribution centered around snap packages would be the ease with which you could quickly install and uninstall a package, without causing issues with other applications. However, that can be achieved with any distribution supporting snap packages.
In the end, Nitrux is a beautiful desktop that is incredibly efficient to use — only slightly hampered by an awkward installer and a lack of available snap packages. Give this distribution a bit of time to work out the kinks and it could become a serious contender.



