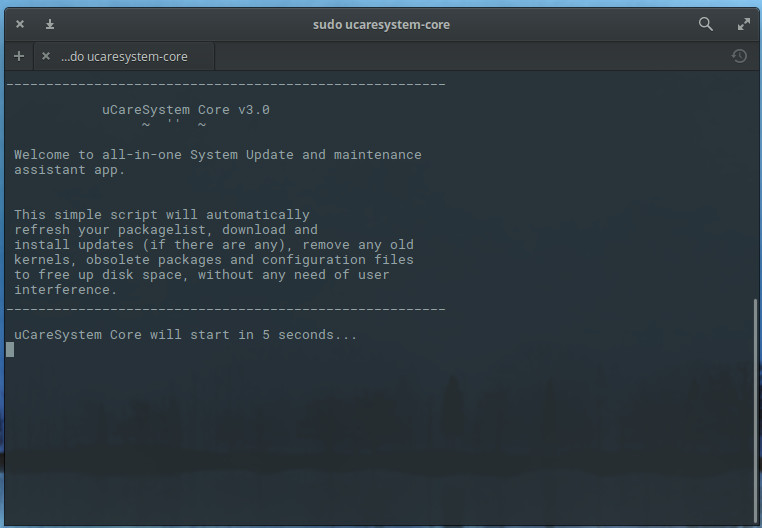
Recently, Google umbrella firm Alphabet announced a new enterprise version of the Google Glass smart eyeglasses. Over the past two years, Glass Enterprise Edition (Glass EE) has been tested at more than 50 companies including Boeing, DHL, GE, and Volkswagen, and is now more widely available via a corporate partner program.
Glass EE has been under development since April 2014 when Google announced a Glass at Work project. This followed widespread criticism of the Android-based, camera-enabled Explorer Edition for consumers, which led to bans in bars and restaurants over privacy concerns. That same year, I compiled a survey of 11 smart eyewear devices that ran on Android or Linux. Here we update that Linux.com report with 10 of the latest models, including the Glass EE. Eight of the 11 vendors from the 2014 story are represented here with updated or new models. (For a longer version of this article, see LinuxGizmos.)
Like Glass EE, some offer voice-or touch-controlled video or GUI displays on one or both sides of your field of view (FOV). Others, like Laforge’s Shima, are limited to text displays sync’d to a companion smartphone, somewhat like an eyeglass version of a smartwatch. More advanced systems, sometimes housed in bulkier headsets, offer true augmented reality (AR) displays that overlay text in the FOV or even map AR displays to real-world objects.
Most of the products here are focused on the same enterprise market as Glass EE, such as field services, manufacturing, logistics, and healthcare. Having a hands-free, voice controlled computer with an AR display is useful to workers that are increasingly asked to consult computers. Rugged handhelds can do the job for some, but many workers need both hands free. The outliers here are Laforge’s consumer-oriented Shima glasses and Everysight’s Raptor, which is designed for cyclists and triathletes, as well as the Tobii Pro eye-tracking glasses, which are designed for market research.
Our list of 10 products is limited to those with onboard Linux or Android computers, and we do not include fully immersive VR headgear or video viewers. We also omit devices that require tethering to a laptop, such as the Meta2. Several of these products, however, are tethered to pocketable control or storage units.
Here’s a brief glance at 10 intriguing Linux and Android eyewear products. We highlight one per company, but in several cases mention other specialty or emerging models. More detailed summaries follow the list below.
The enterprise-focused Atheer AiR Glasses run an Android OS on a quad-core Nvidia Tegra K1, and offers gesture control of AR components. The device includes dual 720p@60fps, 4-Mpx cameras with a wide, 50-degree field of view (FOV), as well as a 3D depth sensing camera. These inputs are combined with directional mic and a 9-axis IMU to offer precise tracking.
The AiR Glasses feature 2GB RAM, up to 128GB flash, WiFi-ac, Bluetooth 4.1, and USB Type-C and HDMI ports. There’s also a 3100mAH battery and optional 4G/LTE and GPS. The device is tethered to pocketable compute device.
The AiR Glasses can display video calls and real-time overlaid image annotations without obscuring one’s view. The SDK can adapt existing Android apps, and there’s an optional AiR Suite for Enterprise with collaboration, management, and task flow apps. A similar AiR Experience package is available to third-party eyewear manufacturers.
In 2014, we covered Daqri’s flagship, Daqri Smart Helmet, which ran Android on a Snapdragon. Earlier this year, a v2 model arrived that runs Linux on a faster 6th Gen Intel Core M7, and adds an Intel RealSense LR200 depth-sensing camera. This same basic features are available in the relatively lighter (400 grams), cheaper ($4,995), and less ruggedized Daqri Smart Glasses Developer Version, which is available for pre-order for shipment later this year. There’s a Linux SDK plus a Daqri 4D Studio augmented work instruction platform.
The Daqri Smart Glasses offer the same multimedia and AR displays as the Smart Helmet, with semi-transparent overlays displaying work instructions, safety information, and maps. A wide-angle AR tracking camera works in conjunction with the RealSense and several sensors to provide environmental awareness. The goggle-like eyewear features an adjustable, wrap-around headband tethered to a pocketable 12-hour video storage unit.
The pricier Daqri Smart Helmet is ruggedized for heavy industrial work, and offers extras such as a thermography camera to detect hotspots. Daqri also sells a Daqri Qube mini-PC version and a Daqri Smart HUD display for cars.
Glass EE (Price unstated)
Glass Enterprise Edition (EE) looks like the original Google Glass Explorer Edition, but is claimed to be lighter, faster, and more secure, with longer battery life and better WiFi. The device is now offered separately from the glasses, letting you clip it onto standard prescription or safety glasses.
The voice- and touch-controlled eyewear runs an Android-based OS. It has a 8-Mpx camera, up from the previous 5-Mpx model, plus an external green light that shows when the camera is on.
Glass EE lacks the semi-immersive AR overlays offered by some competitors, and instead offers video feeds and zoomable GUI displays. Numerous homegrown and third-party apps for a variety of industrial, logistics, and healthcare scenarios are available. No price or detailed specs are currently available for the device, which is available only to selected corporate partners.
In April, five years after the original, Android-based GlassUp appeared on Indiegogo, Italy-based GlassUp announced that it could not complete the project and was not yet able to refund the money.
The consumer-oriented GlassUp prototype, which displays notices from your smartphone, evolved into an Uno model that also seems to have gone nowhere. However, the company claims to have interested manufacturers in a new Linux-based, AR visor style GlassUp F4 model announced in March. The industrial focused GlassUp F4 features a multicolor, 21° FOV AR display, plus a video camera, a thermographic camera, voice controls, WiFi, and an “illumination system.”
Our 2014 roundup included the $700 Moverio BT-200, which ran Android on a dual-core TI OMAP SoC, and offered a 960 x 540 display for AR. Late last year, Epson released its Moverio BT-300, which runs Android 5.1 on a quad-core Intel Atom-x5. The new model is 20 percent lighter, and features a similarly binocular, Si-OLED based display, now updated to 1280 x 720. The 23-degree FOV 2D or 3D display floats in front of your eyes without obscuring the view.
The enterprise focused BT-300 features a 5-Mpx camera, earphones, mic, 802.11ac, Bluetooth 4.1, GPS, 2GB RAM, 16GB flash, and multiple sensors. A small, tethered, handheld control offers a trackpad, controls, and microSD and micro-USB ports. An almost identical BT-300FPV model targets DJI drone control.
Epson recently launched a BT-350 model selling for $1,399 that has the same basic specs as the BT-300, but with an adjustable design made to fit multiple sizes. It’s aimed at multi-user settings such as museums. There’s also a new Moverio Pro BT-2000/2200 headset aimed more directly at industrial applications. The unpriced BT-2000/2200 adds a forehead band and a 5-Mpx stereoscopic camera. It has lower resolution than the BT-300, but offers IP54 and drop protection, plus ANSI Z87.1 safety glass compliance.
The enterprise-focused M300 is a more advanced version of Vusix’s M100 Smart Glasses. Both models are Android-based smart eyewear frames with a monocular display device that can fit over a standard pair of eyeglasses. The M300 features a dual-core Intel Atom with 2GB RAM and 64GB flash. There’s a 16.7-degree diagonal FOV equivalent to a 5-inch smartphone seen from 17 inches.
You interact with the ruggedized device via voice control, a gesture touchpad, four control buttons, proximity sensors, and a 3-DOF head tracker. Other features include a 13-Mpx HD camera, ear speaker, noise-cancelling mics, dual band WiFi-ac, Bluetooth 4.1, and GPS. The M300 supports thousands of existing Android apps, and offers an SDK to write custom apps. Pre-installed apps sync to companion Android or iOS apps.
Vusix is prepping an Atom-based M3000 model with thin waveguide optics and a custom WVGA linear DLP display engine. There’s also a similar new Blade 3000 Smart Sunglasses model. Future plans call for an AR3000 Smart Glasses device with stereoscopic cameras for full AR.
Raptor (Price unstated)
The Android-based Raptor AR glasses for bicyclists and triathletes was announced July 7, and is due to ship later this year. Everysight is a spin-off of Israeli defense contractor Elbit System. Everysight combined a stripped-down version of Elbit’s HUD technology for fighter pilots with the equivalent of an Android smartphone, and squeezed it into a sleek pair of cycling sunglasses. The impact resistant Grilamid TR-90 frame is IP55 protected against exposure, and supports swappable prescription lenses.
The system uses Elbit’s “BEAM” OLED-based projection technology, which projects color-coded dashboard readouts onto the inside of the lenses so they appear to be floating about 20 feet ahead of you. The Raptor displays information such as speed, distance, cadence, power, and turn-by-turn directions. It also shows sensor inputs including Bluetooth connected readouts from an optional heart-rate monitor wristband. Users interact via voice commands, a temple-mounted touchpad, or a handlebar-mounted controller unit.
The system runs Android on a quad-core CPU with 2GB RAM and 16GB to 32GB flash, and offers WiFi, Bluetooth, and GPS/GLONASS. The Raptor integrates a camera, 8-hour battery, speaker, mic, accelerometer, gyroscope, magnetometer, and barometer.You can sync music playback from your phone or stream video back to it, with an option to record the Raptor’s dashboard display. An SDK enables development of AR apps.
Osterhout Design Group (ODG) still sells an updated version of the R-7 AR eyewear for $2,750, and you can now order a more ruggedized R-7HL (Hazardous Locations) model due later this year. Like the R-7, the HL version is an enterprise-focused eyewear product that runs a ReticleOS version of Android 6.0 on a quad-core Snapdragon 805. Spec’d much like the R-7, the HL model adds impact eye protection, protections against drop, shock, vibration, low pressure, and temperature extremes, and ANSI Z87.1+ dustproof and splashproof certification.
Both models feature dual 720p stereoscopic displays at up to 80fps with a 30° FoV. There’s also a separate 4-Mpx camera, 3-DOF head tracking, 802.11ac, Bluetooth 4.1, GNSS, 3GB LP-DDR3, and 64GB storage. Other features include a trackpad, batteries, multiple sensors, removable earhorns, and an audio port.
Later this year, ODG plans to launch Android Nougat powered R-8 and R-9 models with octa-core Snapdragon 835 SoCs and 6-DOF tracking. The devices advance to dual 720p-60 and dual 1080p-60 stereoscopic displays with 40° and 50° FOVs, respectively. Other improvements include 4GB/64GB (R-8) and 6GB/128GB (R-9) memories, with separate dual 1080p or single 14-Mpx, 4K cameras, respectively.
Laforge’s Shima is one of the only smart eyeglasses aimed at the consumer market. You can order them with prescription lenses in different styles that look like typical glasses. This simple Bluetooth accessory beams a WQVGA display into your retina, and displays notices from your smartphone on the right side of your field of vision as transparent overlays. The glasses provide real-time updates from social networks and navigation apps linked to the GPS on your phone.
Our 2014 eyewear report included Laforge’s similar Icis smart glasses, which evolved into Shima in 2015. You can pre-order the Alpha version of Shima for $590 with shipments in a few months and a promise that you will later receive the Beta model as a free upgrade by the end of the year.
The Shima runs a new Linux-based ghOSt OS on a 180MHz Cortex-M4 STM32F439 MCU. Laforge has yet to reveal the processor for the upcoming Beta version or the future dual display Beta Bold. The Alpha is equipped with 16MB RAM and 1GB flash, which will move to 4GB on the Beta and 8GB on the Beta Bold. All three versions feature Bluetooth 4.1 with LE, a micro-USB port, a USB Type-C charger cable, and sensors including gyro, accelerometer, magnetometer, temperature, and ambient light. You also get an 18-hour battery, five buttons, and a touchpad.
The water resistant, lightweight (24 to 27 gram) Alpha and Beta will be followed by a Beta Bold model that adds a camera of at least 3 megapixels, along with a second WQVGA display. A development program and a SocialFlo app offer access to Shima mods such as fitness, meeting, and Alexa-enabled programs.
Tobii Pro Glasses 2, which updates the Tobii Glasses 2 model we covered in 2014, doesn’t display information. Instead, it uses four integrated eye-tracking cameras in conjunction with a front-facing camera to track your gaze for market and behavioral research applications. The video is stored along with tracking information on a tethered recording unit that fits in your pocket. This is later analyzed on desktop computers with algorithms including emotion detection.
The 45-gram Tobii Pro Glasses 2 eyewear offers HD video recording at 25fps with a wide 90°, 16:9 FOV, and a mic. The eye tracking cameras, which provide 50HZ or 100Hz gaze sampling frequency, use corneal reflection, binocular, and dark pupil tracking with automatic parallax compensation.
The WiFi-enabled recording unit can record up to two hours of video on an SD card, and offers HDMI, micro-USB, and audio connections. Premium live video options let researchers remotely analyze sessions in real time.
Learn more about embedded Linux at Open Source Summit North America — Sept. 11-14 in Los Angeles, CA. Register by July 30th and save $150! Linux.com readers receive a special discount. Use LINUXRD5 to save an additional $47.