Developers earn higher salaries when their software skills are scarce and more complex, according to VisionMobile’s 12th annual report on developer economics released this week.
In 2017, that means skilled cloud and backend developers, as well as those who work in emerging technologies including Internet of Things (IoT), machine learning and augmented/virtual reality (AR/VR) can make more money — tens or sometimes hundreds of times more — than frontend web and mobile developers whose skills have become more commoditized.
“In Western Europe, for example, the median backend developer earns 12% more than the median web developer; a machine learning developer makes 28% more,” according to the report.
This is because in emerging tech markets like AR/VR and IoT, companies that are early adopters will pay top dollar for skilled developers who are scarce. The top 10 percent of salary earners in AR who live in North America earn a median salary of $219,000, compared with $169,000 for the top earning 10 percent of backend developers, according to the report.
Such high salaries are possible, however, only if you’re already a skilled developer. New, unskilled developers interested in emerging tech will have a harder time finding work, and earn less than their counterparts in more commoditized areas, due both to their lack of experience and fewer companies hiring in the early market.
Along with skill level and software sector, developer salaries also vary widely by where they live in the world. A web developer in North America earns a median income of $73,600 USD per year, compared with the same developer in Western Europe whose median income is $35,400 USD. Web developers in South Asia earn $11,700 in South Asia while those in Eastern Europe earn $20,800 per year.
“What’s a developer to do if you want to move up in the world, financially? Invest in your skills. Do difficult work. Improve your English. Look for opportunities internationally. Go for it. You deserve it!” VisionMobile says.
Based on a survey of more than 21,000 developers worldwide, VisionMobile’s “State of the Developer Nation” report includes a wealth of information on developer trends, from tools and programming languages, to career opportunities in AR/VR, web, IoT, data science, and cloud. This year for the first time the report also included developer salary information.
Krzysztof Czurylo presents a new tool built on Valgrind – Pmemcheck – yet another memory error detector designed specifically to detect problems with Persistent Memory programming.
Kubernetes is open source software for automating deployment, scaling, and management of containerized applications. The project is governed by the Cloud Native Computing Foundation, which is hosted by The Linux Foundation. And it’s quickly becoming the Linux of the cloud, says Jim Zemlin, executive director of The Linux Foundation.
Running a container on a laptop is relatively simple. But connecting containers across multiple hosts, scaling them when needed, deploying applications without downtime, and service discovery among several aspects, are really hard challenges. Kubernetes addresses those challenges with a set of primitives and a powerful API.
A key aspect of Kubernetes is that it builds on 15 years of experience at Google, which donated the technology to CNCF in 2015. Google infrastructure started reaching high scale before virtual machines became pervasive in the datacenter, and containers provided a fine-grained solution to pack clusters efficiently.
In this blog series, we introduce you to LFS258: Kubernetes Fundamentals, the Linux Foundation Kubernetes training course. The course is designed for Kubernetes beginners, and will teach students to deploy a containerized application, and how to manipulate resources via the API. You can download the sample chapter now.
The Meaning of Kubernetes
“Kubernetes” means the helmsman, or pilot of the ship. In keeping with the maritime theme of Docker containers, Kubernetes is the pilot of a ship of containers.
Challenges
Containers have seen a huge rejuvenation in the past three years. They provide a great way to package, ship, and run applications. The developer experience has been boosted tremendously thanks to containers. Containers, and Docker specifically, have empowered developers with ease of building container images, and simplicity of sharing images via Docker registries.
However, managing containers at scale and architecting a distributed application based on microservices’ principles is still challenging. You first need a continuous integration pipeline to build your container images, test them, and verify them. Then you need a cluster of machines acting as your base infrastructure on which to run your containers. You also need a system to launch your containers, watch over them when things fail, and self-heal. You must be able to perform rolling updates and rollbacks, and you need a network setup which permits self-discovery of services in a very ephemeral environment.
Kubernetes Architecture
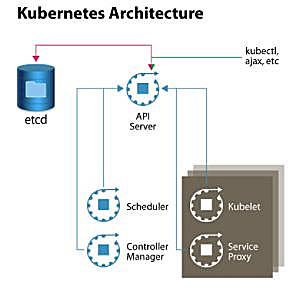
To quickly de-mystify Kubernetes, let’s have a look at Figure 1, which shows a high-level architecture diagram of the system components. In its simplest form, Kubernetes is made of a central manager (aka master) and some worker nodes. (You will learn in the course how to run everything on a single node for testing purposes).
The manager runs an API server, a scheduler, a controller, and a storage system to keep the state of the cluster. Kubernetes exposes an API via the API server so you can communicate with the API using a local client called kubectl, or you can write your own client. The scheduler sees the requests for running containers coming to the API and finds a suitable node to run that container in.
Each node in the cluster runs two processes: a kubelet and a service proxy. The kubelet receives requests to run the containers and watches over them on the local node. The proxy creates and manages networking rules to expose the container on the network.
Figure 1: Kubernetes system components.
In a nutshell, Kubernetes has the following characteristics:
It is made of a manager and a set of nodes
It has a scheduler to place containers in a cluster
It has an API server and a persistence layer with etcd
It has a controller to reconcile states
It is deployed on VMs or bare-metal machines, in public clouds, or on-premise
It is written in Go
How Is Kubernetes Doing?
Since its inception, Kubernetes has seen a terrific pace of innovation and adoption. The community of developers, users, testers, and advocates is continuously growing every day. The software is also moving at an extremely fast pace, which is even putting GitHub to the test. Here are a few numbers:
It was open sourced in June 2014
It has 1,000+ contributors
There are 37k+ commits
There have been meetups in over 100 cities worldwide, with over 30,000 participants in 25 countries
There are over 8,000 people on Slack
There is one major release approximately every three months
Kubernetes is being adopted at a rapid pace. To learn more, you should check out the case studies presented on Kubernetes.io. eBay, box, Pearson, and Wikimedia have all shared their stories. Pokemon Go, the fastest growing mobile game, runs on Google Container Engine (GKE), the Kubernetes service from Google Cloud Platform (GCP).
In this article, we talked about what Kubernetes is, what it does, and took a look at its architecture. Next week in this series, we’ll compare Kubernetes to competing container managers.
This blog series is adapted from materials prepared by course instructor Sebastien Goasguen, a 15-year open source veteran. He wrote the O’Reilly Docker Cookbook and, while investigating the Docker ecosystem, he started focusing on Kubernetes. He is the founder of Skippbox, a Kubernetes startup that provides solutions, services, and training for this key cloud-native technology, and Senior Director of Cloud Technologies for Bitnami. He is also a member of the Apache Software Foundation and a member/contributor to the Kubernetes Incubator.
Czurylo started with an overview of persistent memory and the SNIA NVM Programming Model, which was covered in more detail in the blog posts for the other two talks in this series. He quickly moved on to talk about some of the issues and the tools they needed to build to solve them. Specifically, they needed a persistent memory error detection tool that could:
Differentiate between volatile and persistent memory regions.
Detect stores that were not flushed to persistence.
Detect stores that were overwritten before being made persistent.
Detect superfluous flushes.
Support persistent memory transactions.
Simulate failure / flush reordering.
They were thinking about writing some tools from scratch, but Czurylo said that eventually they decided to use Valgrind, which is a popular tool that supports multiple platforms and is already widely used by the community. Valgrind is also feature-rich with low-level instrumentation and good multi-threading support. More specifically, Valgrind already performs a lot of what they needed in a persistent memory error detection tool, since it already tracks changes to memory, so they only needed to write tools that allowed Valgrind to detect whether the order of operations is correct. One nice feature of Valgrind is that it already has a client request mechanism, which allows them to inject specific persistent memory requests or queries into the code. However, there are a couple of downsides. The API isn’t well documented and can be difficult to use, and there are also performance issues where the execution is a couple of times slower when you run your program using this tool.
The Valgrind pmemcheck tool is still evolving with several new features and other improvements being planned. Future work includes store reordering, ADR support / detection, performance tuning, upstreaming to the Valgrind repositories, and more.
Watch the video of Czurylo’s talk to get all of the details about using the Valgrind pmemcheck tools.
Interested in speaking at Open Source Summit North America on September 11-13? Submit your proposal by May 6, 2017. Submit now>>
Not interested in speaking but want to attend? Linux.com readers can register now with the discount code, LINUXRD5, for 5% off the all-access attendee registration price. Register now to save over $300!
Yunong Xiao, Principal Software Engineer at Netflix, describes scaling challenges the company has encountered and explains how the company delivers content to a global audience on an ever-growing number of platforms.
Much has been said about moving from monoliths to microservices. Besides rolling off the tongue nicely, it also seems like a no-brainer to chop up a monolith into microservices. But is this approach really the best choice for your organization? It’s true that there are many drawbacks to maintaining a messy monolithic application. But there is a compelling alternative which is often overlooked: modular application development. In this article, we’ll explore what this alternative entails and show how it relates to building microservices.
Microservices for modularity
“With microservices we can finally have teams work independently”, or “our monolith is too complex, which slows us down.” These expressions are just a few of the many reasons that lead development teams down the path of microservices. Another one is the need for scalability and resilience. What developers collectively seem to be yearning for is a modular approach to system design and development. Modularity in software development can be boiled down into three guiding principles:
IEEE is taking a lead role in building a comprehensive, end-to-end view of the computing ecosystem, including devices, components, systems, architecture, and software. In May 2016, IEEE announced the formation of the IRDS under the sponsorship of IEEE RC. The historical integration of IEEE RC and the International Technology Roadmap for Semiconductors (ITRS) 2.0 addresses mapping the ecosystem of the new reborn electronics industry. The new beginning of the evolved roadmap—with the migration from ITRS to IRDS—is proceeding seamlessly as all the reports produced by the ITRS 2.0 represent the starting point of IRDS.
While engaging other segments of IEEE in complementary activities to assure alignment and consensus across a range of stakeholders, the IRDS team is developing a 15-year roadmap with a vision to identify key trends related to devices, systems, and other related technologies.
… a lot of open source software is developed on (and with the help of) proprietary services running closed-source code. Countless open source projects are developed on GitHub, or with the help of JIRA for bug tracking, Slack for communications, Google Docs for document authoring and sharing, Trello for status boards. That sounds a bit paradoxical and hypocritical—a bit too much “do what I say, not what I do.” Why is that? If we agree that open source has so many tangible benefits, why are we so willing to forfeit them with the very tooling we use to produce it?
But it’s free!
The argument usually goes like this: Those platforms may be proprietary, they offer great features, and they are provided free of charge to my open source project.
Function as a Service (FaaS) uses Docker and Swarm to create a simple system for running functions in the container, language, and runtime of your choice.
Serverless computing has fast become a staple presence on major clouds, from Amazon to Azure. It’s also inspiring open source projects designed to make the concept of functions as a service useful to individual developers.
FaaS is designed to be more elementary than similar projects, mainly because it emphasizes Unix mechanisms and metaphors as much as the tools of the Docker stack.
The growing number of Netflix subscribers — nearing 85 million at the time of this Node.js Interactive talk — has generated a number of scaling challenges for the company. In his talk, Yunong Xiao, Principal Software Engineer at Netflix, describes these challenges and explains how the company went from delivering content to a global audience on an ever-growing number of platforms, to supporting all modern browsers, gaming consoles, smart TVs, and beyond. He also looks at how this led to radically modifying their delivery framework to make it more flexible and resilient.
One of the first steps Netflix took to cope with their swelling subscriber base was to migrate all their infrastructure to the cloud. But somehow, Xiao says, that didn’t mean that once the migration complete, the developers could “just sit around and watch TV shows.” The cloud, after all, is just somebody else’s computer, and scaling for the number of users is just part of the problem. As the number of users increased, so did the number of platforms they had to deliver to. In its first iteration, Netflix only worked on the browsers, and the framework was simply a Java web server that managed everything. The server did more or less everything, both rendering the UI and accessing the data.
Netflix relies on microservices to provide a diverse range of features. For each microservice there is a team of developers that more or less owns the service and provides a client to the Java server to use. The Java server — the monolith in this story — suffered from several issues. To begin with, it was very slow to push and innovate. Every time a new show launched and they wanted to add a new roll title to the UI, they had to push the service. If one of the development teams launched a new and improved version of a client, they had to push the service. When a new microservice was added to the existing ones, they had to push the service. Furthermore, increasing the number of supported devices was nearly impossible in any practical sense.
So in the next iteration, the development team migrated to a REST API. This unlocked the ability to support more devices. The new framework also separated the rendering of the UI and the accessing of data processes. However, the REST API also came with its fair share of disadvantages. For one it was inflexible, as it was originally designed for one kind of device and adding new devices was painful. Also, as a different team owned the REST API, the microservices teams were often waiting weeks for API changes to support their own new services.
It also proved inefficient. REST is resource based and every little element on the Netflix UI is a resource. So, in order to, for example, fetch all of a customer’s favorite movies, the services had to make multiple round trips to the back end. Ultimately, it proved difficult to maintain, because the API became more complex and bloated as developers tried to retrofit it with more features.
The different developer teams needed flexibility to innovate for the platforms they were supporting, and the resulting REST API was too clunky and restrictive for this. Another evolution of the Netflix framework was required.
The API.NEXT allowed each team to upload their own custom APIs to the servers. The teams could change the scripts (written in Groovy) as much as they liked without affecting other teams. The API service itself could also be updated independently from the APIs that it was serving. The problem was the Monolith was back again, and that led to scaling problems. Netflix has literally thousands of scripts sharing the same space, serving millions of clients. It was common, says, Xiao, to “run out of headspace,” be that memory, CPU, or I/O bandwidth. This led to expensive upgrades when more resources were needed. Another thing that even led to outages were errors in the scripts themselves: If a script had a memory leak, for example, it could bring down the system for everyone.
Another problem was what Xiao calls “Developer Ergonomics.” The NEXT.API server was a very complex piece of software with multiple moving parts. Scripts could not be tested locally. To test a script, the team had to upload it to a test site, run it, test it, and, if there were any problems, go through the whole process again after troubleshooting the issues. This process was slow and inconvenient and led to the current iteration of the Netflix framework, one in which scalability and availability, and developer productivity are taken into account.
While designing the new framework, it was established that, on the scalability/availability front, one of the goals was to achieve process isolation to avoid the problems the NEXT.API suffered from. It also required that the data access scripts and API servers were kept separate to reduce infrastructure costs. The designers also wanted to reduce the startup time and have immutable deployment artifacts, which would allow to reproduce the different builds.
As for developer productivity, most developers wanted to use the same language (preferably JavaScript) on the server and the client, and not deal with two distinct technologies. They also needed to be able to run tests locally, have faster incremental builds, and an environment that as closely mirrored the production as possible.
The new framework, called New Generation Data Access API, has moved all the data accessing APIs into separate apps running Node.js. Each app is now isolated running in a Docker container. The back-end services are now contained within a Java-based server the Netflix development team calls the Remote Service Layer. The RSL integrates all back-end services under one consistent API. Whenever developers want to deploy a new APIs, they push JavaScript to the server in the form of a Node.js container.
Overall, Netflix’s current combined Java/Node-based platform allows for a quicker and easier deployment, with fewer of the issues that plagued prior monolithic approaches.
If you’re interested in speaking at or attending Node.js Interactive North America 2017 – happening October 4-6 in Vancouver, Canada – please subscribe to the Node.js community newsletter to keep abreast of dates and deadlines.