
This is the first article in our Introducton to OpenStack series. If you’d like to learn more about how to use OpenStack, The Linux Foundation offers OpenStack training courses.
OpenStack is a cloud software stack designed to run on commodity hardware, such as x86 and ARM. It has no proprietary hardware or software requirements, and it integrates legacy systems and third-party products. In other words you can adopt it into your existing tech infrastructure without disruption.
It was originally developed by NASA and Rackspace, and the first release was in 2010. Their intention from the beginning was to make it an open source project that anyone could use or contribute to. OpenStack is under the Apache License 2.0, and since that first release it has grown into a large community supported by over 9,000 contributors in nearly 90 countries, and more than 150 companies including Red Hat, Canonical, IBM, AT&T, Cisco, Intel, PayPal, Comcast, and a host of other names that should be familiar to most of us.
What is Cloud?
Let’s quickly review just what a computing cloud is. Cloud technologies are built on existing technologies such as virtualization and clustering to virtualize hardware, software, storage, and networking resources into flexible units that are quickly allocated to meet demand. So rather than the old static model of dedicated hardware servers for various tasks, and static network and storage configurations, all of those formerly specialized devices are assimilated into a common resource pool. It’s a more efficient use of hardware, and very fast to scale up or down according to demand. You can even configure self-service for users so they can grab whatever they need when they need it.
Private clouds are hosted on your own premises, and there are public clouds like Amazon’s EC2 and the Rackspace Cloud. You can combine private and public clouds in many useful ways. For example, keep your sensitive data locked away in your private cloud, and use a public cloud for sharing, testing, and extra non-sensitive storage.
All computing resources are shareable in a cloud, and there are three basic service models:
- SaaS, software as a service
- PaaS, platform as a service
- IaaS, infrastructure as a service
SaaS is centrally-hosted application software accessed by client software, with data typically kept on the server for access from any networked computer. Yes, just like in the olden client-server days, but the modern twist is to stuff everything through a Web browser. Using a Web browser as the client has its down sides, starting with HTTP, which was never designed for complex computing tasks, but by gosh we’re making it haul water, chop wood, and dig ditches, and it’s doing it cross-platform. SaaS is popular with software vendors because it reduces their support costs, gives them more control, and at long last supports that coveted grail of the monthly subscription model. It’s nice for customers as well, because they don’t have to hassle with installation and maintenance.
PaaS is a nice option for customers who want more control of their datacenter, but not all the headaches of system and network administration. An example of this is managed cloud Web hosting where the host takes care of hardware, operating systems, networking, load balancing, backups, and updates and patches. The customer manages the development and configuration of whatever software they want to use. It’s like sitting down to a fully-configured datacenter and getting right to work.
IaaS can be thought of as virtual bare hardware that the customer managers like a physical server, with control of all the software and configuration. You could also call it HaaS, hardware as a service.
Allrighty then, that’s enough about that. Let’s see what’s inside OpenStack.
Inside OpenStack
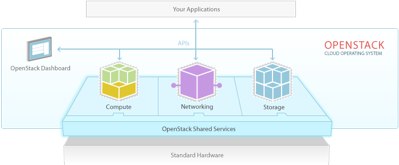
OpenStack is a complex beast containing multiple components. The core components are OpenStack Compute, OpenStack Glance, OpenStack Identity Service, and OpenStack Object Store.
OpenStack Compute is the virtual machine provisioning and management module. Its development name is Nova, so when you read about Nova it’s the same thing. It supports multiple hypervisors including KVM, QEMU, LXC, and XenServer. Compute is the mighty tool that controls the whole works: networking, CPU, storage, memory, creating, controlling, and removing virtual machine instances, security, and access control. You control all this from the command-line or from a graphical Web-based dashboard.
OpenStack Glance, the OpenStack Image Service, manages virtual disk images. Glance supports Raw, Hyper-V (VHD), VirtualBox (VDI), Qemu/KVM (qcow2), and VMWare (VMDK, OVF) virtual machine images, and it also supports Amazon Machine Images (AMI). You can do all kinds of cool things with Glance: stream virtual disk images, configure public and private images and control access to them, and of course create and destroy them.
OpenStack Object Store, as the name suggests, manages storage. It is a distributed storage system for managing all types of storage: archives, user data, virtual machine images, and the hardware they’re stored on. There are multiple layers of redundancy and automatic replication, so a failure in a node doesn’t result in data loss, and recovery is automatic.
The Identity Service manages users and projects.
Getting Your Hands on OpenStack
Naturally we don’t want to just look at OpenStack, but want to install and play with it. It’s designed to manage very large datacenters and handle petabytes of data, but you can install it on a PC to learn your way around it. It’s included in most Linux distributions so you can install it just like any other software, from your favorite package manager. Feel free to jump ahead and start testing it, and in our next installment we’ll run through a quick-start and basic concepts.




