
With the recent advances in machine learning technology, it is only a matter of time before developers can expect to run full diagnostics and information retrieval on their own source code. This can include autocompletion, auto-generated user tests, more robust linters, automated code reviews and more. I recently reviewed a new product in this sphere — the source{d} Engine.
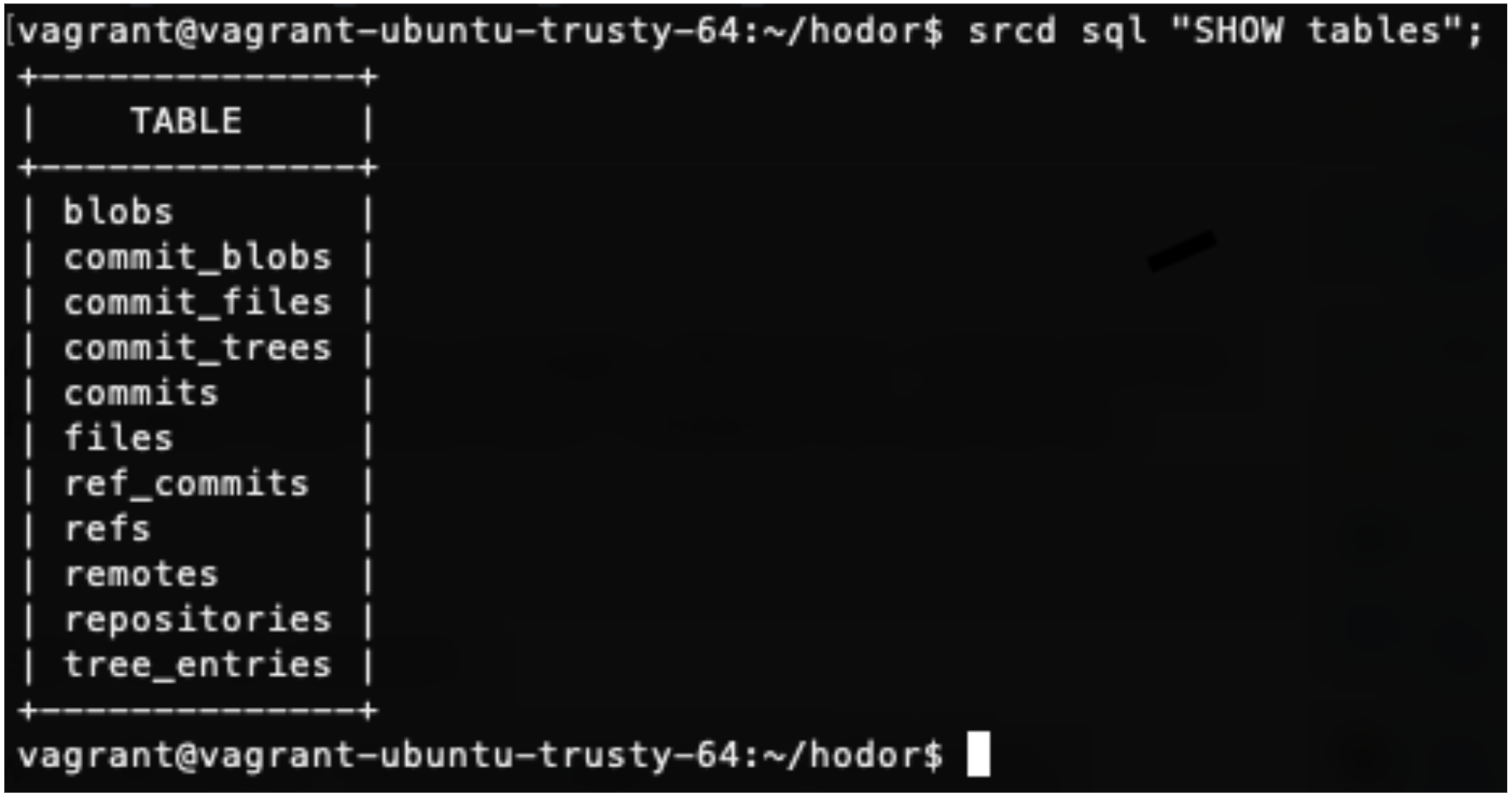
source{d} offers a suite of applications that uses machine learning on code to complete source code analysis and assisted code reviews. Chief among them is the source{d} Engine, now in public beta; it uses a suite of open source tools (such as Gitbase, Babelfish, and Enry) to enable large-scale source code analysis. Some key uses of the source{d} Engine include language identification, parsing code into abstract syntax trees, and performing SQL Queries on your source code such as:
-
What are the top repositories in a codebase based on number of commits?
-
What is the most recent commit message in a given repository?
-
Who are the most prolific contributors in a repository?
Because source{d} Engine uses both agnostic language analysis and standard SQL queries, the information available feels infinite.
From minute one, using source{d} Engine was an easy, efficient process. I ran source{d} Engine chiefly on a virtual machine running Ubuntu 14.04 but also installed it on MacOS and Ubuntu 16.04 for comparison purposes. On all three, install was completely painless, although the Ubuntu versions seemed to run slightly faster. The source{d} Engine documentation is accurate and thorough. It correctly warned me that the first time initializing the engine would take a fair amount of time so I was prepared for the wait. I did have to debug a few errors, all relating to my having a previous SQL instance running so some more thorough troubleshooting documentation might be warranted.
It’s simple to go between codebases using the commands scrd kill and scrd init. I wanted to explore many use cases so I picked a wide variety of codebases to test on ranging from a single contributor with only 5 commits to one with 10 contributors, thousands of lines of code, and hundreds of commits. source{d} Engine worked phenomenally with all of them although it is easier to see the benefits in a larger codebase.
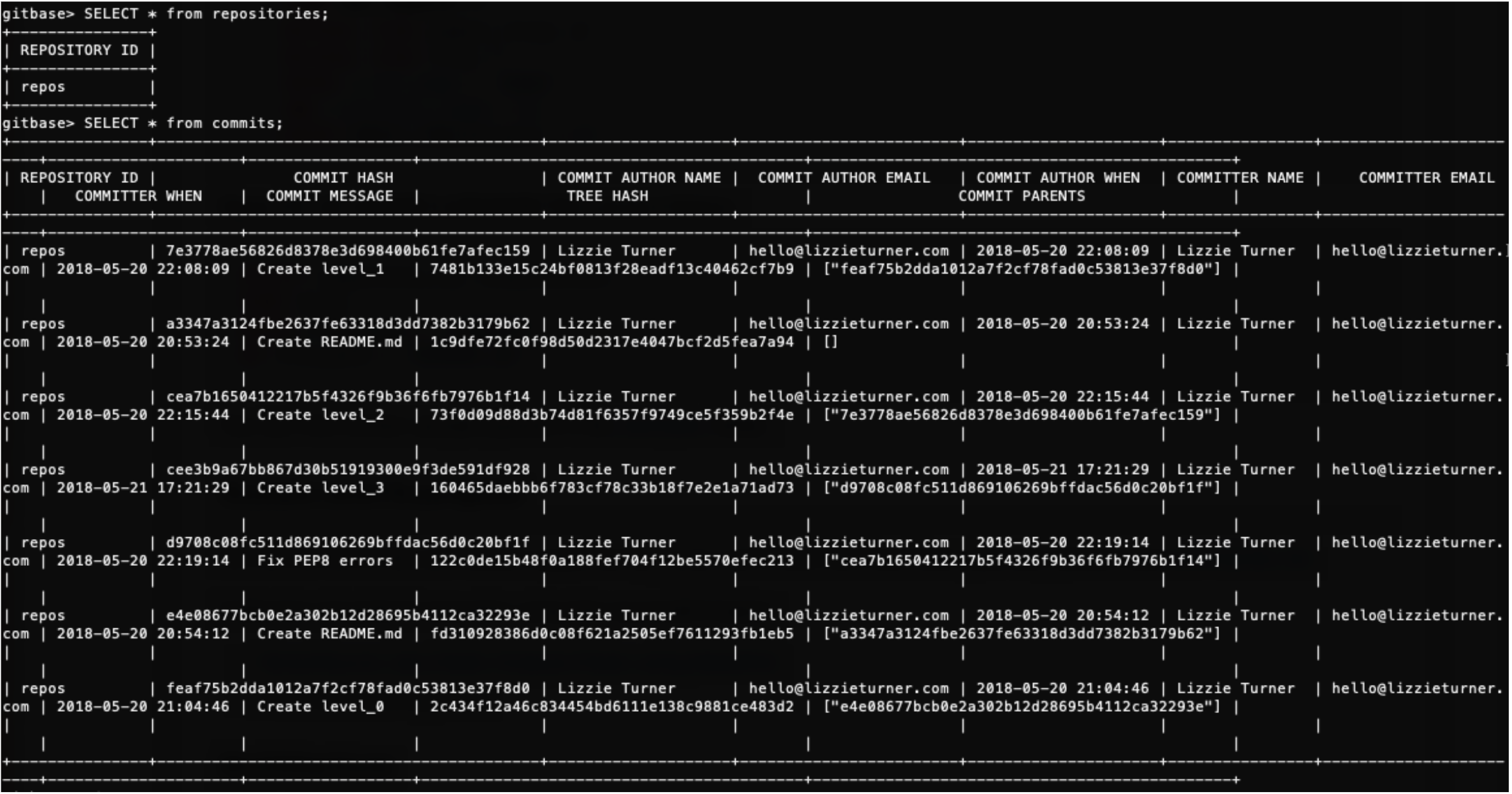
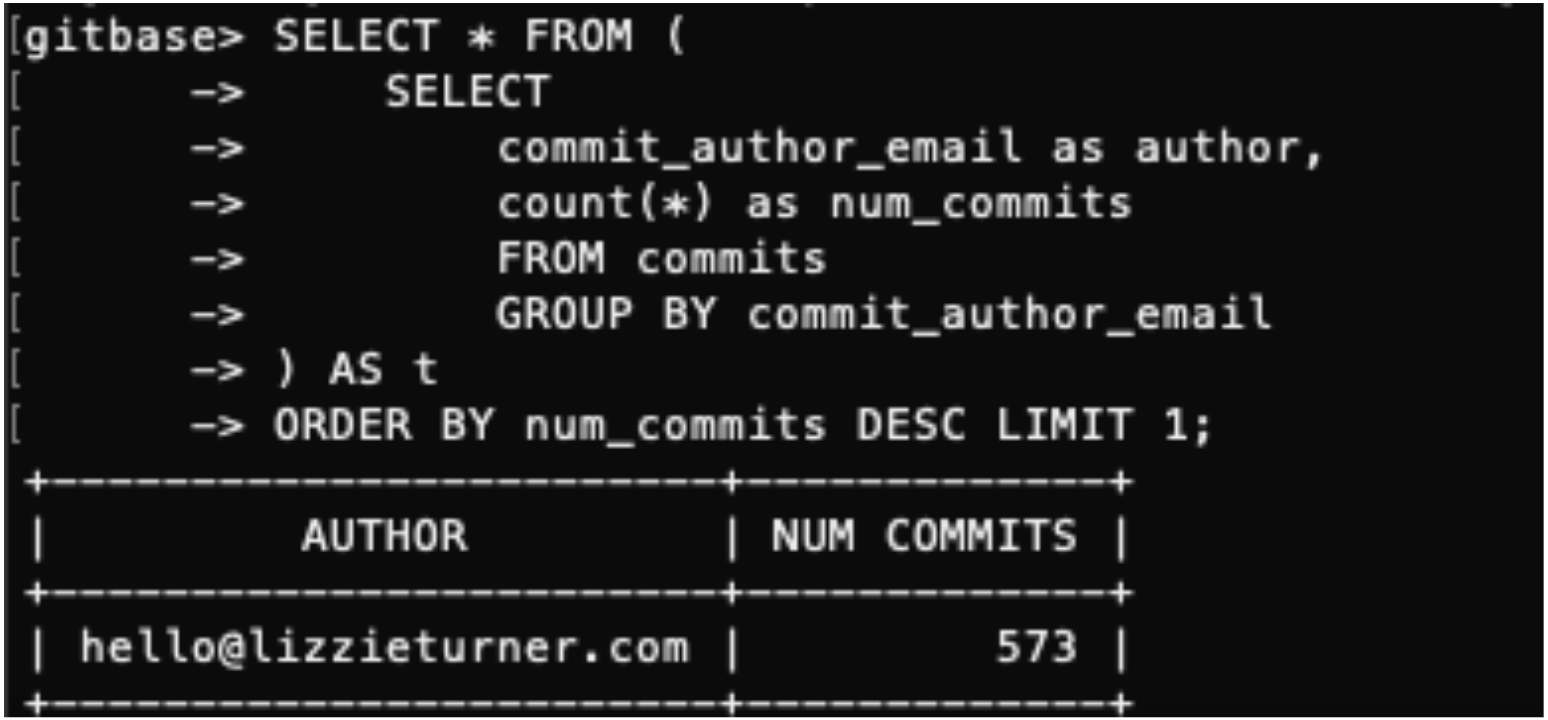
My favorite queries to run were those pertaining to commits. I am not a fan of the way GitHub organizes commit history, so I find myself coming back to source{d} Engine again and again when I want commit history-related information. I’m also very impressed with the Universal Abstract Syntax Tree (UAST) concept. A UAST is a normalized form of an abstract syntax tree (AST) — a structural representation of source code used for code analysis. Unlike ASTs, UASTs are language agnostic and do not rely on any specific programming language. The UAST format enables further analysis and can be used with any tools in a standard, open style.
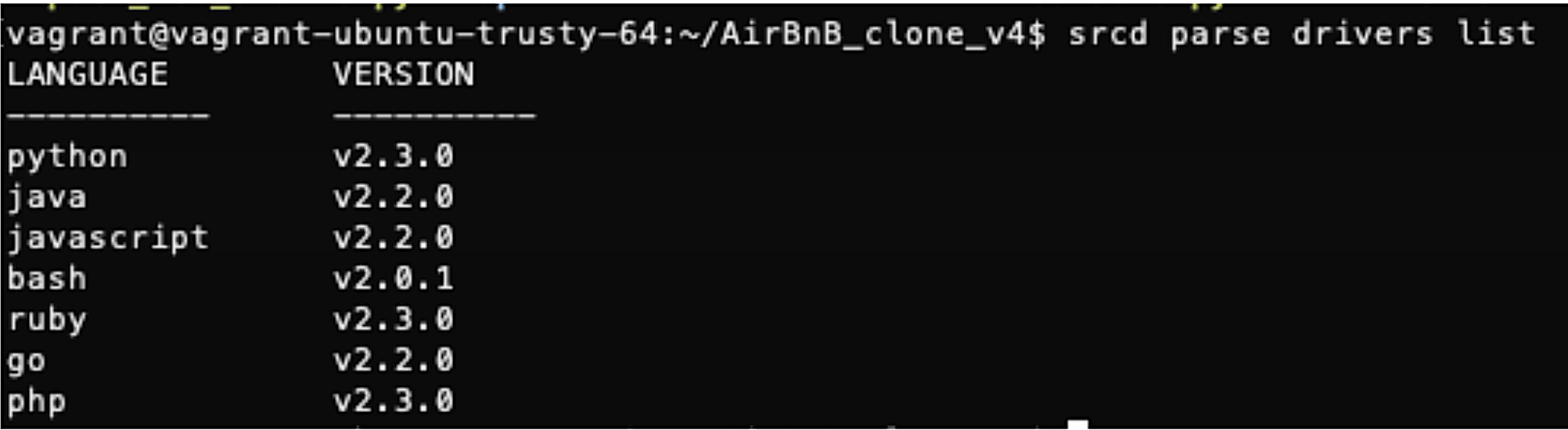
My only complaint is the (obvious and understandable) reliance on a base level of SQL knowledge. Because I was already very familiar with SQL, I was able to quickly use the source{d} Engine engine and create my own queries. However, if I had been shakier on the basics, I would’ve appreciated more example queries. Another minor complaint is that support for Python appears to only be for Python 2 right now, and not Python 3.
I’m excited to follow the future of source{d} Engine and also source{d} Lookout (now in public alpha) which is the first step to a suite of true machine learning on code applications. I would love for the documentation of this and other upcoming applications to be more comprehensive, but because they are not fully available yet, just having what’s available already is great.
In general, I’m extremely impressed with the transparency of the company — not only are the future products and applications clearly listed and described, many internal company documents are also available. This true dedication to open source software is amazing, and I hope more companies follow source{d} ’s lead.
Lizzie Turner is a former digital marketing analyst studying full stack software engineering at Holberton School. She is currently looking for her first software engineering role and is particularly passionate about data and analytics. You can find Lizzie on LinkedIn, GitHub, and Twitter.
This article was produced in partnership with Holberton School





{kind=link}