
In Part 1 of this three-part series, we began to examine the potential data loss issue on system crash when running the ext4 filesystem. In Part 2, we’ll examine benchmarks and the price of data consistency.
As Theodore Ts’o blog advocates using fsync(2) to get around the rename issue on ext4, one would imagine that it performs much better on ext4 than ext3. And that leads us to the second part of the article: benchmarks! What price is there to be paid for fsync(2) in different scenarios on different filesystems.
I’ll test not only ext3 and ext4 but also XFS, JFS and Reiserfs. You will notice two benchmarks for XFS, one with the default options and one with the nobarrier mount option. By default XFS uses block layer write barriers which can make some operations much slower. There is also a barrier mount option for ext3 which is off by default. For ext4 barriers are on by default. Unfortunately I’m unsure if this barrier option is comparing apples with apples across these two filesystems though. As btrfs is still so young I decided to omit it from the benchmarks.
The benchmarks were run on a P35 motherboard equipped with 8GB of 800MHz DDR2 and an Intel Q6600 2.4 GHz quad core CPU. The disk was a Samsung HD642JJ, 640Gb SATA drive. The system was running an up to date Fedora 9 with the 2.6.27.19-78.2.30.fc9.x86_64 kernel. A single extended partition was used, ranging from block 35058 to 77824. As a more human digestible size indication, when formatted with the default ext3 parameters this gave a 323G blank filesystem with 195M used. I used this same disk and block range reformatted to a different filesystem for all testing.
Because I’m using this 300 odd gigabyte filesystem just for benchmarking the only write activity would be that which I generate. So calling fsync should be too quick relative to real world performance where you might be generating a bunch of file writes from other tasks. So I also needed a way to introduce write activity that was reproducible. The IO load was generated by compiling the Linux kernel 2.6.29 on the same filesystem that the testing was being done on.
The below commands were used to prepare a kernel tree and kick off a kernel compile just before the benchmark was executed. The below script prepares an extracted kernel for compilation. I made separate prepare and compile scripts so that the preparation could be done after each filesystem was created and mounted and before the compile and benchmark were started. Using XFS with barriers enabled gives fairly slow filesystem metadata operations like file creation, so performing the kernel tarball extraction and configuration before the benchmark means that all tests started on an even footing.
# cat ../prepare-a-kernel.sh
#!/bin/bash
cd /mnt/benchmark
mkdir -p kernel
cd ./kernel
echo "extracting..."
tar xf /tmp/linux-2.6.29.tar
cd ./linux-2.6*
cp ./arch/x86/configs/x86_64_defconfig .config
make oldconfig /dev/null 2>&1
ccache -Cc
The below command was used to kick off a kernel compile just before the benchmark was executed. The script compiles the kernel many times to ensure there is always something happening in rare cases when the compilation would end before the benchmark. I first spotted this problem when using XFS with the nobarrier mount option set. The make is always run with nice so that other tasks might be more responsive during the test.
# cat ../compile-a-kernel.sh
#!/bin/bash
cd /mnt/benchmark
mkdir -p kernel
cd ./kernel
cd ./linux-2.6*
echo "compiling..."
for i in `seq 1 20`;
do
nice make -j 5 bzImage modules >|/tmp/compile-log.txt 2>&1
nice make clean
ccache -Cc
done
echo "done compiling..."
Benchmarks were run through a driver program that created a filesystem and mounted it at /mnt/benchmark. If a kernel compile was to be performed during the test, a new kernel expand and compile was then started before the benchmark task itself. This means that each benchmark would be on a fresh filesystem — no fragmentation issues.
As a baseline, the system could get about 96MB/sec, 92MB/src and 3500MB/sec for hdparm -t, hdparm -t –direct, and hdparm -T respectively on the 640Gb drive.
The first benchmark I choose was using bonnie++. Many folks will already be familiar with bonnie++, it gives you benchmarks for per char and per block read/write as well as rewrite, seek and file metadata operations like creation and deletion. Delving deeper into bonnie++ you can specify that fsync() is performed using the -b option. The seek benchmark is performed in CFileOp::doseek which will, every now and then also write a block after a seek. Because you can get seek to call fsync after each write, the seek benchmark will reflect what impact the fsync has when bonnie++ is run both with and without the -b option.
I performed bonnie++ with and without the fsync option on a filesystem that had no other activity and one that had a kernel compilation loop running in the background. The results of bonnie++ on many filesystems without fsync and without background filesystem load are shown below:
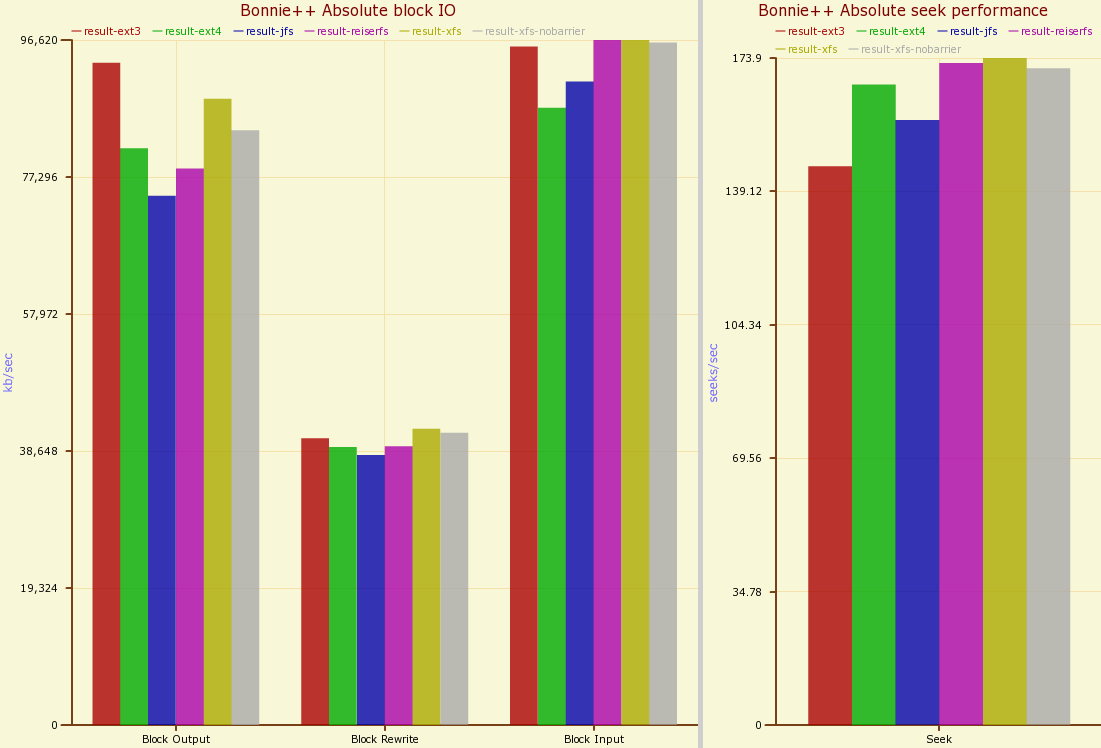
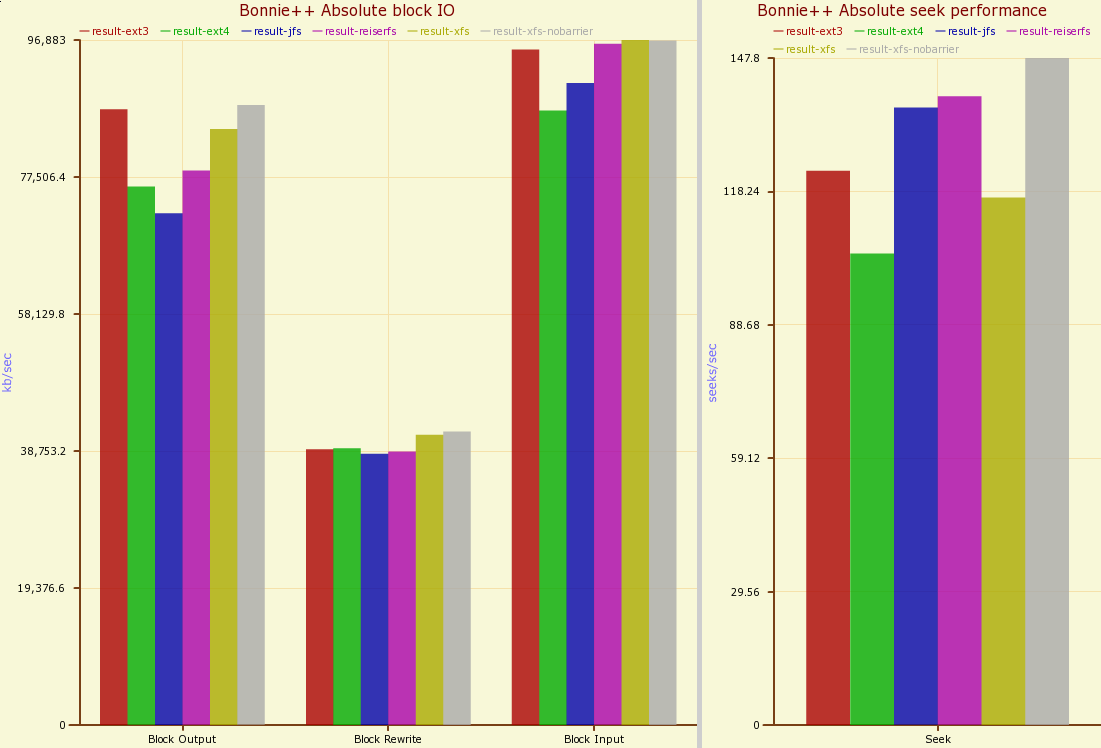
Keeping the disk otherwise idle and turning on the fsync option gives the results below. Notice that the seeks per second drops a little bit, loosing perhaps 30 seeks / second. Turning on the fsync has the most effect for ext4 and XFS (with barriers).
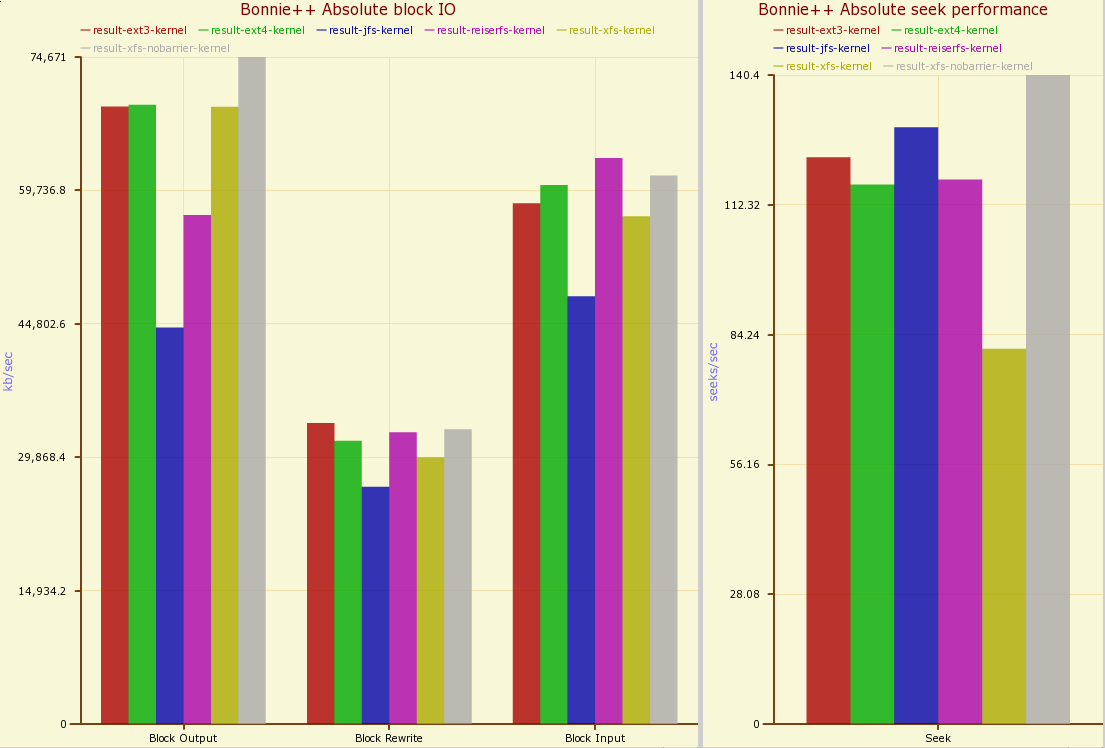
Shown below is bonnie++ without fsync but while a kernel was being compiled in the background. The figures are down across the board, and seek times are inline with the above test where fsync was used on an otherwise idle disk. There are abnormalities here though, ext4 did better here than above and XFS with barriers was much worse off.
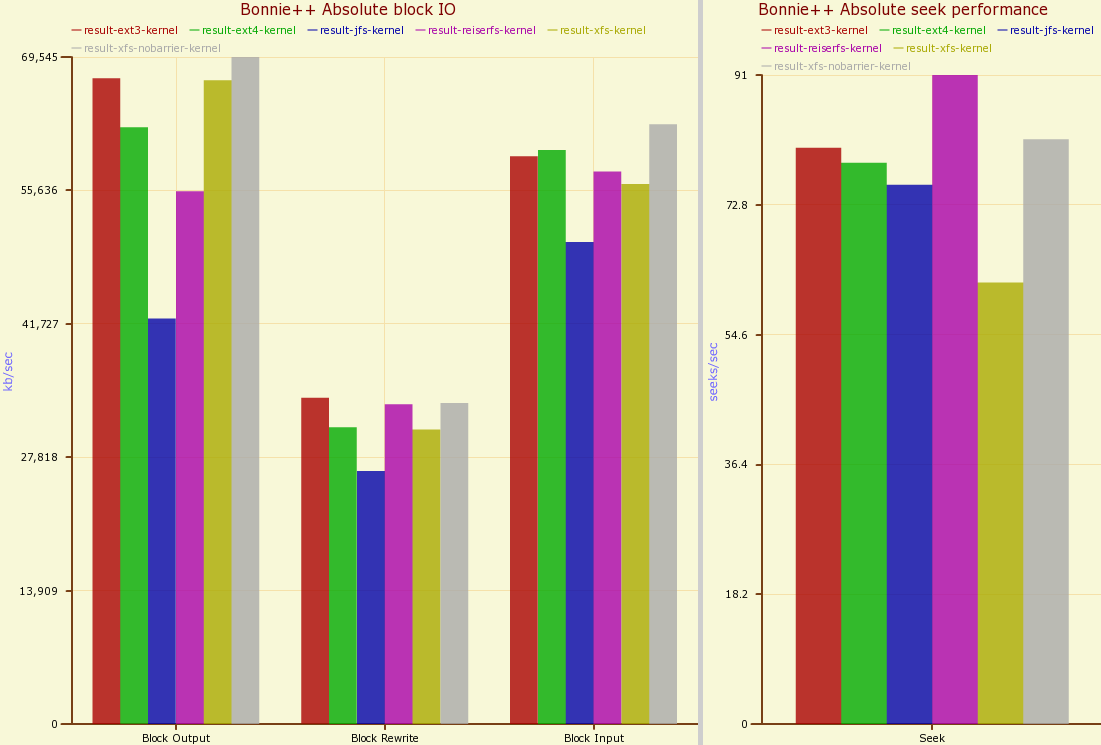
Shown below is the bonnie++ benchmark with fsync turned on on a loaded disk. Seeks are down to about 70 instead of 110 as a result of turning fsync on. Once again, XFS with barriers is well down due to fsync.
In Part 3, we’ll examine the next most obvious benchmark: how many open, write, fsync, close, rename cycles can be performed per second, as well as other benchmarks.



