
 QEMU is the backbone of virtualization on Linux, providing control plane and emulation services for guest VMs. One of the most common complaints about QEMU stems from its monolithic nature — one process that does both control and emulation exposes more “surface area” that we, in turn, have to protect from security vulnerabilities. Well perhaps no longer, as multi-process QEMU has now been accepted…
QEMU is the backbone of virtualization on Linux, providing control plane and emulation services for guest VMs. One of the most common complaints about QEMU stems from its monolithic nature — one process that does both control and emulation exposes more “surface area” that we, in turn, have to protect from security vulnerabilities. Well perhaps no longer, as multi-process QEMU has now been accepted…
Click to Read More at Oracle Linux Kernel Development
Multiprocess QEMU: Breaking up is hard to do

Centaurus Infrastructure Project Joins Linux Foundation to Advance Cloud Infrastructure for 5G, AI and Edge
Centaurus today is becoming a Linux Foundation Project. The Centaurus Infrastructure Project is a cloud infrastructure platform for building distributed cloud as well as a platform for modern cloud native computing. It supports applications and workloads for 5G, Edge and AI and unifies the orchestration, network provisioning and management of cloud compute and network resources at a regional scale.
Founding members include Click2cloud, Distributed Systems, Futurewei, GridGain Systems, Reinvent Labs, SODA Foundation and Tu Wien Informatics. Centaurus is an umbrella project for modern distributed computing and hosts both Arktos and Mizar. Arktos is a compute cluster management system designed for large scale clouds, while Mizar is the high-performance cloud-network powered by eXpress Data Path (XDP) and Geneve protocol for high scale cloud. More members and projects are expected to be accepted in the coming months.
“The market is changing and customers require a new kind of cloud infrastructure that will cater to modern applications and workloads for 5G, AI and Edge,” said Mike Dolan, senior vice president and general manager for Linux Foundation Projects. “Centaurus is a technical project with strategic vision, and we’re looking forward to a deep collaboration that advances cloud native computing for generations to come.”
Current cloud infrastructure technology needs are evolving, requiring companies to manage a larger scale of compute and network resources across data centers and more quickly provision those resources. Centaurus unifies management across bare metal, VMs, containers and serverless, while reducing operational costs and delivering on the low latency and data privacy requirements of edge networks. Centaurus offers a consistent API experience to provision and manage virtual machines, containers, serverless and other types of cloud resources by combining traditional (Infrastructure as a Service) IaaS and Platform as a Service (PaaS) layers into one common infrastructure platform that can simplify cloud management.
“The Linux Foundation’s support in expanding the Centaurus community will accelerate cloud native infrastructure for the most pressing compute and networking demands,” said Dr. Xiong Ying, the current acting TSC chair, Centaurus Infrastructure Project. “It’s large network of open source developers and projects already supporting this future will enable mass collaboration and important integrations for 5G, AI and Edge workloads.”
To contribute to Centaurus, please visit: https://www.centauruscloud.io/
Supporting Member Quotes
Click2cloud
“Click2cloud has been part of the development of Centaurus, which is world class software that will lead organizations to have a clear transition from IaaS to Cloud Native Infrastructure. Click2cloud has already started a development program to enable the journey from IaaS (Openstack) to Cloud Native migration, 5G cloud based on Centaurus reference architecture to support the partner ecosystem. We are very excited for Centaurus to be a part of Linux Foundation,” said Prashant Mishra, CEO, Click2cloud.
Futurewei
“Distributed cloud architecture is a natural evolution for cloud computing infrastructure. Centaurus is a cloud native infrastructure platform aiming to unify management and orchestration of virtual machines, containers, and other forms of cloud resources natively at scale and at the edge. We have seen many enterprise users and partners wanting a unified solution to build their distributed cloud to manage virtual machines, containers or bare metal-based applications running at cloud as well as at edge sites. We are very pleased to see, today, the Centaurus Infrastructure project becomes a Linux Foundation open-source project, providing an option for community and enterprise users to build their cloud infrastructure to run and manage next generation applications such as AI, 5G and IoT. We look forward to working with the open-source community to realize the vision of Centaurus,” said Dr. Xiong Ying, Sr. Technical VP, Head of Cloud Lab, Futurewei.
GridGain Systems
“Creating and managing a unified and scalable distributed cloud infrastructure that extends from cloud to edge is increasingly a challenge for organizations worldwide. GridGain Systems has been a proud sponsor and active participant in the development of in-memory computing solutions to support the Centaurus project. We look forward to helping organizations realize the benefits of Centaurus and continuing to help extend its scalability and adoption,” said Nikita Ivanov, Co-Founder and CTO, GridGain Systems.
Reinvent Labs
“We are a young company, which specializes in cloud computing and delivering cloud-native solutions to our customers across various industries. As such, we are ever stronger witnessing the need to manage cloud services and applications that span across complex and heterogeneous infrastructures, which combine containers, VMs and serverless functions. What is more, such infrastructures are also starting to grow beyond traditional cloud platforms towards the edge on the network. Being part of the Centaurus project will not only allow us to innovate in this space and deliver a platform for unified management of infrastructure resources across both large Cloud platforms and the Edge, but it will also enable us to connect and collaborate with like-minded members for thought leadership and industry best practices,” said Dr. Stefan Nastic, founder and CEO of Reinvent Labs GmbH.
The SODA Foundation
“The SODA Open Data Framework is an open source data and storage management framework that goes from the edge to the core to the cloud. Centaurus offers the opportunity for SODA to be deployed in the next generation cloud infrastructure for 5G, AI and Edge, and allows both communities to innovate together,” said Steven Tan, SODA Foundation Chairman and VP & CTO Cloud Solution, Storage at Futurewei.
TU Wien
“We are very excited to be part of the Centaurus ecosystem and honored to be part of this open source movement and contributing in the fields of IoT, Edge intelligence, and Edge and Cloud Computing, including networking and communication aspects, as well as orchestration, resource allocation, and task scheduling,” said Prof. Schahram Dustdar, IEEE Fellow, Member Academia Europaea Professor of Distributed Systems, TU Wien, Austria.
The post Centaurus Infrastructure Project Joins Linux Foundation to Advance Cloud Infrastructure for 5G, AI and Edge appeared first on Linux Foundation.
Open Source Jobs Remain Secure During COVID-19 Pandemic and More Findings From Linux Foundation and Laboratory for Innovation Science at Harvard Report
A new report from The Linux Foundation and Laboratory for Innovation Science at Harvard (LISH) has found that 56% of survey respondents reported involvement in open source projects was important in getting their current job, and 55% feel that participating in open source projects has increased their salary or otherwise improved their job prospects. The “Report on the 2020 FOSS Contributor Survey” compiled the answers of 1,196 contributors to free and open source software (FOSS), and also found that 81% stated the skills and knowledge gained by working on open source were valuable to their employer.
One highlight of the report was the finding that, “[d]espite the survey being administered during the economic downturn resulting from the COVID-19 pandemic, very few respondents were out of the workforce.” This aligns with our 2020 Open Source Jobs Report from earlier this year, in which only 4% of hiring managers reported they have laid off open source professionals due to the pandemic, and a further 2% furloughed open source staff.
In terms of why these individuals contribute to open source projects, respondents were unsurprisingly most likely to say because they use open source software and need certain features added, so they build and add said features. The next top answers provided some more insight into what motivates these open source professionals though. Those were “I enjoy learning” and “Contributing allows me to fulfill a need for creative, challenging, and/or enjoyable work”. This also aligns with the recent jobs report, where open source pros reported they decided to work in the open source community because “Open source runs everything” and “I am passionate about open source”. Both reports suggested that compensation, while important, is not a dominant source of motivation.
Focusing more on what open source projects can do to be successful, the new report goes on to suggest that, “FOSS projects could also provide some educational materials (such as tutorials or getting started guides) about their projects to help those motivated by a desire to learn.” This gets to the heart of our mission at LF Training & Certification – to make quality training materials about open source technologies accessible to everyone.
One area of opportunity for projects, employers and open source pros according to the report is around secure development practices. The survey respondents overwhelmingly reported that they spend little time focusing on security issues, despite both the quantity and sophistication of attacks increasing year in and year out, and goes on to suggest that “a free online course on how to develop secure software as a desirable contribution from an external source” may help. LF Training & Certification released just such a training program recently in the form of our Secure Software Development Fundamentals Professional Certificate program created in partnership with the Open Source Security Foundation and hosted by non-profit learning platform edX. The program consists of three courses which can all be audited for free, or those who wish to obtain the Professional Certificate may receive such by paying a fee and passing a series of tests aligned to each course. Employers concerned about software development security issues should consider mandating that staff take training like this, and projects should consider requiring it of maintainers as well.
This is just the tip of the iceberg in terms of the findings of the FOSS Contributor Survey; we encourage you to download and review the full document for ever more insight and recommendations.
The post Open Source Jobs Remain Secure During COVID-19 Pandemic and More Findings From Linux Foundation and Laboratory for Innovation Science at Harvard Report appeared first on Linux Foundation – Training.
The Maple Tree, a new data structure for Linux

Last week, Liam Howlett posted the first version of the Maple Tree to the linux-kernel mailing list. The Maple Tree, a collaboration between Liam Howlett and Matthew Wilcox, introduces a B-tree based range-locked tree which could significantly reduce unnecessary contention on the memory management subsystem — with the eventual goal of perhaps removing mmap_sem entirely. They have been working on this for a year…
Click to Read More at Oracle Linux Kernel Development
The Maple Tree, a new data structure for Linux

Last week, Liam Howlett posted the first version of the Maple Tree to the linux-kernel mailing list. The Maple Tree, a collaboration between Liam Howlett and Matthew Wilcox, introduces a B-tree based range-locked tree which could significantly reduce unnecessary contention on the memory management subsystem — with the eventual goal of perhaps removing mmap_sem entirely. They have been working on this for a year…
Click to Read More at Oracle Linux Kernel Development
How long does your IO take ?

Oracle Linux engineer Rajan Shanmugavelu illustrates how to analyse disk IO latency using Dtrace. There are times despite having a Highly Available and Fault Tolerant architected storage environment, the disk IO takes an abnormally longer time to complete, potentially causing outages at different levels in a data center. This becomes critical in a Cluster with multiple nodes that are using disk heartbeat…
Click to Read More at Oracle Linux Kernel Development
How long does your IO take ?
Oracle Linux engineer Rajan Shanmugavelu illustrates how to analyse disk IO latency using Dtrace.There are times despite having a Highly Available and Fault Tolerant architected storage environment, the disk IO takes an abnormally longer time to complete, potentially causing outages at different levels in a data center. This becomes critical in a Cluster with multiple nodes that are using disk heartbeat to do health…
Click to Read More at Oracle Linux Kernel Development
Cut your Cloud Computing Costs by Half with Unikraft
A novel modular unikernel allows for extreme tailoring of your operating system to your application’s needs. A proof of concept, built on Unikraft, a Xen Project subproject, shows up to 50% efficiency improvements than standard Linux on AWS EC2.
Cloud computing has revolutionized the way we think about IT infrastructure: Another web server? More database capacity? Resources for your artificial intelligence use case? Just spin-up another instance, and you are good to go. Virtualization and containers have allowed us to deploy services without worrying about physical hardware constraints. As a result, most companies heavily rely on micro-services, which are individual servers highly specialized to perform a specific task.
The problem is that general-purpose operating systems such as Linux struggle to keep pace with this growing trend towards specialization. The status quo is that most microservices are built on top of a complete Linux kernel and distribution. It is as if you wanted to enable individual air travel with only one passenger seat per aircraft but kept the powerful engines of a jumbo jet. The result of having a proliferation of general-purpose OSes in the cloud are bloated instances, that feast on memory and processing power while uselessly burning electrical energy as well as your infrastructure budget.
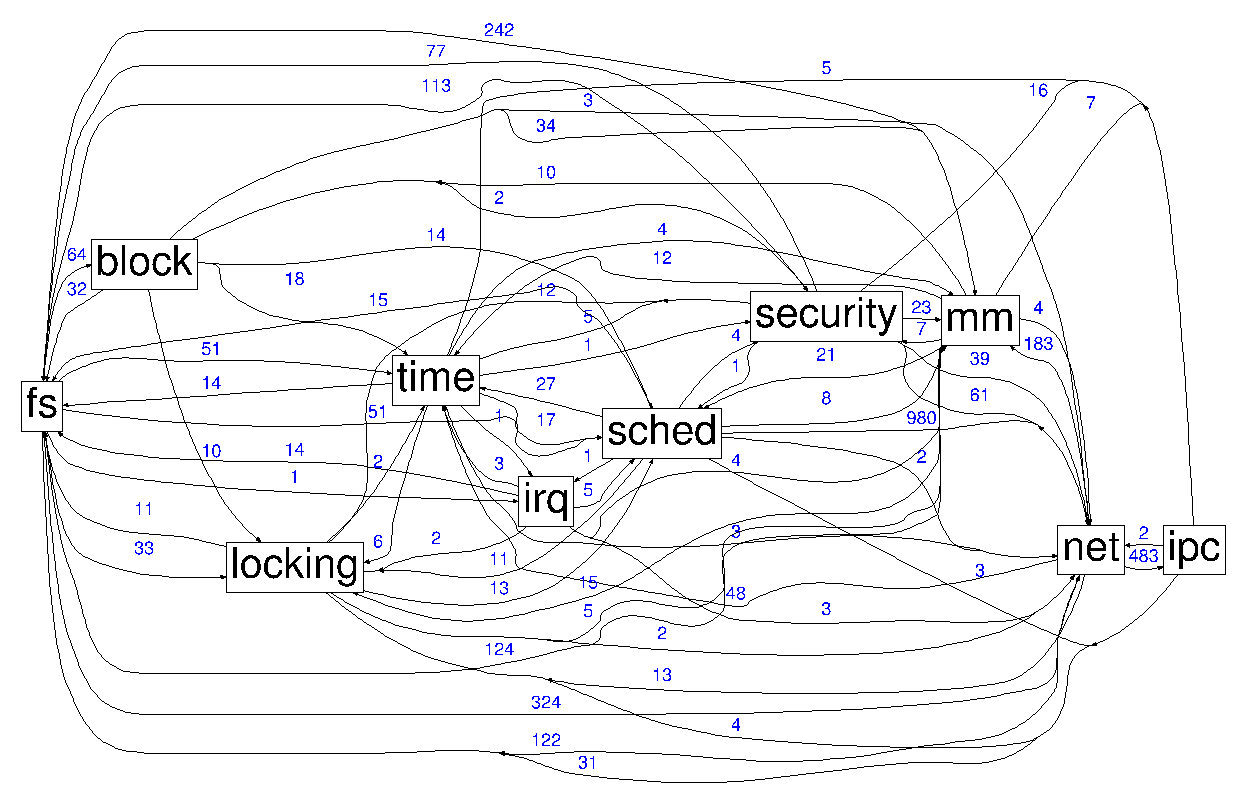
Despite this, putting Linux and other monolithic OSes on a diet is far from trivial. Removing unneeded components from the Linux kernel is a tedious endeavor due to the interdependencies among subsystems of the kernel: Figure 1 above illustrates a large number of such inter-dependencies a line denotes a dependency and a blue number the amount of such dependencies between two components.
An alternative is to build so-called unikernels, images tailored to specific applications and often built on much smaller kernels. Unikernels have shown great promise and performance numbers (e.g., boot times of a few milliseconds, memory consumption when running off-the-shelf applications such as nginx of only a few MBs, and high throughput). However, their Achilles heel has been that they often require substantial expert work to create them and that at least part of the work has to be redone for each additional application. These issues, coupled with the fact that most unikernel projects don’t have a rich set of tools and ecosystem (e.g., Kubernetes integration, debugging and monitoring tools, etc.), resulting in 1GB Linux instances for jobs that might be as easy as delivering static web pages.
Unikraft: A Revolutionary Way Forward
Unikraft is on a mission to change that. In stark contrast to other unikernel projects, Unikraft, a Xen Project subproject, has developed a truly modular unikernel common code base from which building tailored made (uni)kernels is orders of magnitude faster than in the past.
“Without Unikraft, you have to choose between unikernel projects that only work for a specific language or application, or projects that aim to support POSIX but do so while sacrificing performance and thus defeating the purpose of using unikernels in the first place”, says Felipe Huici, one of the Unikraft team’s core contributors. “
Unikraft aims to run a large set of off-the-shelf application and languages (C/C++, Python, Go, Ruby, Lua, and WASM are supported, with Rust and Java on the way), but still allows for easy customization and even removal of unneeded kernel parts; also, it provides a set of rich, performance-oriented APIs that allows further customization by plugging the application at different levels of the stack for even higher performance.”
A sample of such APIs are shown in Figure 2 below.
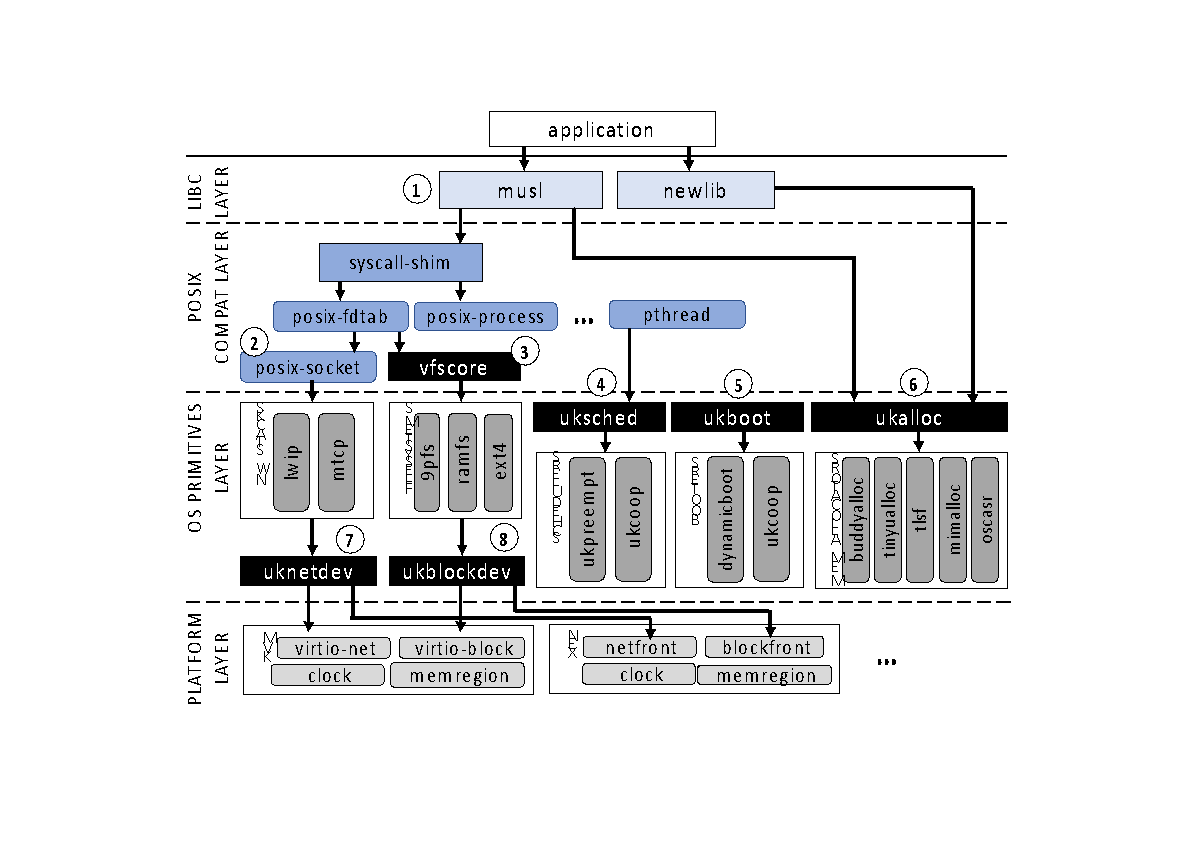
Unikraft already supports more than 130 syscalls in terms of POSIX compatibility, and the number is continuously increasing. While this is certainly short of the 300+ that Linux supports, it turns out that only a subset of these are needed for running most of the major server applications. This, and ongoing efforts to support standard frameworks such as Kubernetes and Prometheus make Unikraft an enticing proposition and mark the coming of age of unikernels into the mainstream.
Unikraft Goes to the Cloud
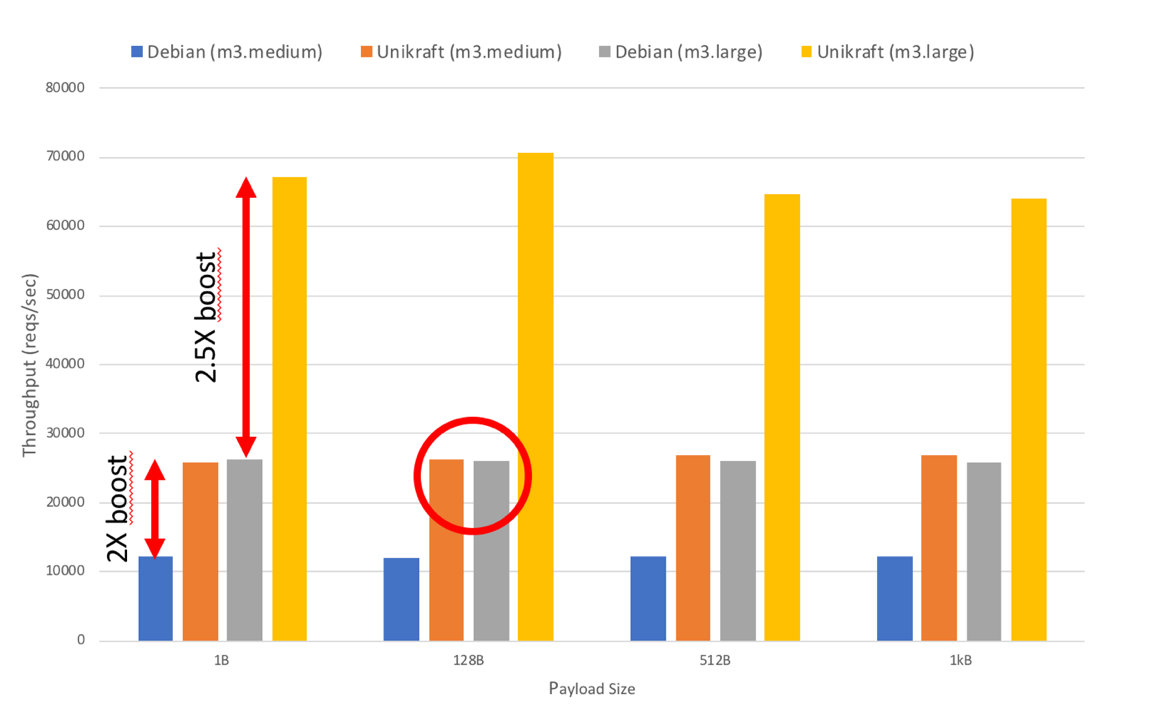
But what’s really in it for end-users? To demonstrate the power and efficiency of Unikraft, the team created an experimental Unikraft AWS EC2 image running nginx, currently the world’s most popular web server. “We’ve built a Unikraft nginx image and compared it to a ngnix running on an off-the-shelf Debian image to compare the performance of the two when serving static web pages. We’ve been more than pleased with the results” says Huici. “On Unikraft, nginx could handle twice the number of requests per second compared to the Debian instance. Or you could take a less performant AWS EC2 instance at half the price and get the same job done. Further, Unikraft needed about a sixth the amount of memory to run”. The throughput results can be seen in Figure 3 below.
So far, this is only a proof of concept, but Huici and the Unikraft team are moving quickly. “We are currently working on a system to make the process of creating a Unikraft image as easy as online-shopping” – this includes analyzing the applications which are meant to run on top of it and providing a ready-to-use operating system that has everything the specific use case needs, and nothing more. “Why should we waste money, resources, and pollute the environment running software in the background that is not needed for a specific service?”
About the author: Simon Kuenzer is the Project Lead and Maintainer of Unikraft, which is part of the Xen Project at the Linux Foundation.
Prepr Partners with the Linux Foundation to Provide Digital Work-Integrated Learning through the F.U.N.™ Program
December 14th, 2020 – Toronto, Canada – Prepr is excited to announce a new partnership with The Linux Foundation, the nonprofit organization enabling mass innovation through open source, that will give work-integrated learning experiences to youth facing employment barriers. The new initiative, the Flexible Upskilling Network (F.U.N. ) program, launches in collaboration with the Magnet Network and the Network for the Advancement of Black Communities (NABC). The F.U.N. program is a blended learning program, where participants receive opportunities to combine valuable work experience with digital skill development over a 16-week journey. The objective of the F.U.N. program is to support youth, with a focus on women and visible minority groups who are involuntarily not in employment, education, or training (NEET) in Ontario, by helping them gain employability skills, including soft skills like communication, collaboration, and problem-solving.
) program, launches in collaboration with the Magnet Network and the Network for the Advancement of Black Communities (NABC). The F.U.N. program is a blended learning program, where participants receive opportunities to combine valuable work experience with digital skill development over a 16-week journey. The objective of the F.U.N. program is to support youth, with a focus on women and visible minority groups who are involuntarily not in employment, education, or training (NEET) in Ontario, by helping them gain employability skills, including soft skills like communication, collaboration, and problem-solving.
Caitlin McDonough, Chief Education Officer at Prepr, says about the F.U.N. program, “Digital skills are essential for the workforce of the future. We at Prepr, are looking forward to the opportunity to support youth capacity development for the future of work.”
With The Linux Foundation, Prepr is committed to supporting over 180 youth participants enrolling and completing the F.U.N program between July 2020 and March 2021. Prepr will be using its signature PIE ® method to train the participants in Project Leadership, Innovation, and Entrepreneurship to expose them to real-world business challenges. The work-integrated learning experience Prepr provides will support participants in developing both soft and hard skills, with a focus on digital skills to help them secure gainful employment for the uncertain future of work.
“In this day and age, it is essential to have a good educational foundation in technology to maximize your chances of career success,” said Clyde Seepersad, SVP and GM, Training & Certification at The Linux Foundation. “We are thrilled to partner with Prepr to bring The Linux Foundation’s vendor-neutral, expert training in the open source technologies that serve as the backbone of modern technologies to communities that will truly benefit from it. I look forward to seeing how these promising students perform and hope to partner with Prepr on future initiatives to train even more in the future.”
The program will explore digital career pathways through multiple work-related challenges. These work challenges will bring creative approaches to gaining innovative skills that are invaluable in today’s new normal of remote work and learn while allowing individuals to become more competitive in today’s digital workforce.
Stephen Crawford, MPP for Oakville, speaking about the government’s commitment to supporting youth facing employment barriers: “This government is committed to supporting our youth, notably visible minorities, as they prepare to enter the workforce. The youth of today will be the leaders of tomorrow.” The Ontario government funding for the F.U.N. program is part of a $37 million investment in training initiatives across the province.
Through the program’s blended learning approach, participants will learn how to use Prepr’s signature PIE ® tool, which addresses three essential skills gaps facing the business services sector today: expertise in innovation, project management, and business development (entrepreneurship, sales, and commercialization). At the end of the program, participants will gain a certification, along with 12 weeks of hands-on work experience, which will foster valuable, future-proof skills to secure gainful employment.
The Linux Foundation will also support participants through an introductory course to Linux and related tools: LFS101x: Introduction to Linux. The program will help to develop the digital skills essential for our new normal of work, with beginner-level challenges to fill obvious skills gaps and foster a mentality of problem-solving. With the support of open Linux Foundation resources, these challenges will be an opportunity for participants to ideate and create project solutions ready for real-world implementation.
About Prepr
Prepr provides the tools, resources, and technology to empower individuals to become lifelong problem solvers. Through triangular cooperation between the public and private sectors as well as government, Prepr aims to strengthen the collaboration on challenges that affect individuals, communities, businesses, and infrastructure to create a more sustainable future for everyone.
About The Linux Foundation
Founded in 2000, the Linux Foundation is supported by more than 1,000 members and is the world’s leading home for collaboration on open source software, open standards, open data, and open hardware. Linux Foundation’s projects are critical to the world’s infrastructure including Linux, Kubernetes, Node.js, and more. The Linux Foundation’s methodology focuses on leveraging best practices and addressing the needs of contributors, users, and solution providers to create sustainable models for open collaboration. For more information, please visit us at linuxfoundation.org.
The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see its trademark usage page: www.linuxfoundation.org/trademark-usage. Linux is a registered trademark of Linus Torvalds.
The post Prepr Partners with the Linux Foundation to Provide Digital Work-Integrated Learning through the F.U.N.™ Program appeared first on Linux Foundation – Training.
How to Create and Manage Archive Files in Linux
By Matt Zand and Kevin Downs
In a nutshell, an archive is a single file that contains a collection of other files and/or directories. Archive files are typically used for a transfer (locally or over the internet) or make a backup copy of a collection of files and directories which allow you to work with only one file (if compressed, it has a lower size than the sum of all files within it) instead of many. Likewise, archives are used for software application packaging. This single file can be easily compressed for ease of transfer while the files in the archive retain the structure and permissions of the original files.
We can use the tar tool to create, list, and extract files from archives. Archives made with tar are normally called “tar files,” “tar archives,” or—since all the archived files are rolled into one—“tarballs.”
This tutorial shows how to use tar to create an archive, list the contents of an archive, and extract the files from an archive. Two common options used with all three of these operations are ‘-f’ and ‘-v’: to specify the name of the archive file, use ‘-f’ followed by the file name; use the ‘-v’ (“verbose”) option to have tar output the names of files as they are processed. While the ‘-v’ option is not necessary, it lets you observe the progress of your tar operation.
For the remainder of this tutorial, we cover 3 topics: 1- Create an archive file, 2- List contents of an archive file, and 3- Extract contents from an archive file. We conclude this tutorial by surveying 6 practical questions related to archive file management. What you take away from this tutorial is essential for performing tasks related to cybersecurity and cloud technology.
1- Creating an Archive File
To create an archive with tar, use the ‘-c’ (“create”) option, and specify the name of the archive file to create with the ‘-f’ option. It’s common practice to use a name with a ‘.tar’ extension, such as ‘my-backup.tar’. Note that unless specifically mentioned otherwise, all commands and command parameters used in the remainder of this article are used in lowercase. Keep in mind that while typing commands in this article on your terminal, you need not type the $ prompt sign that comes at the beginning of each command line.
Give as arguments the names of the files to be archived; to create an archive of a directory and all of the files and subdirectories it contains, give the directory’s name as an argument.
To create an archive called ‘project.tar’ from the contents of the ‘project’ directory, type:
$ tar -cvf project.tar project
This command creates an archive file called ‘project.tar’ containing the ‘project’ directory and all of its contents. The original ‘project’ directory remains unchanged.
Use the ‘-z’ option to compress the archive as it is being written. This yields the same output as creating an uncompressed archive and then using gzip to compress it, but it eliminates the extra step.
To create a compressed archive called ‘project.tar.gz’ from the contents of the ‘project’ directory, type:
$ tar -zcvf project.tar.gz project
This command creates a compressed archive file, ‘project.tar.gz’, containing the ‘project’ directory and all of its contents. The original ‘project’ directory remains unchanged.
NOTE: While using the ‘-z’ option, you should specify the archive name with a ‘.tar.gz’ extension and not a ‘.tar’ extension, so the file name shows that the archive is compressed. Although not required, it is a good practice to follow.
Gzip is not the only form of compression. There is also bzip2 and and xz. When we see a file with an extension of xz we know it has been compressed using xz. When we see a file with the extension of .bz2 we can infer it was compressed using bzip2. We are going to steer away from bzip2 as it is becoming unmaintained and focus on xz. When compressing using xz it is going to take longer for the files to compressed. However, it is typically worth the wait as the compression is much more effective, meaning the resulting file will usually be smaller than other compression methods used. Even better is the fact that decompression, or expanding the file, is not much different between the different methods of compression. Below we see an example of how to utilize xz when compressing a file using tar
$ tar -Jcvf project.tar.xz project
We simply switch -z for gzip to uppercase -J for xz. Here are some outputs to display the differences between the forms of compression:

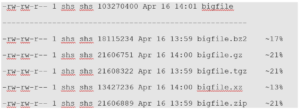
As you can see xz does take the longest to compress. However it does the best job of reducing files size, so it’s worth the wait. The larger the file is the better the compression becomes too!
2- Listing Contents of an Archive File
To list the contents of a tar archive without extracting them, use tar with the ‘-t’ option.
To list the contents of an archive called ‘project.tar’, type:
$ tar -tvf project.tar
This command lists the contents of the ‘project.tar’ archive. Using the ‘-v’ option along with the ‘-t’ option causes tar to output the permissions and modification time of each file, along with its file name—the same format used by the ls command with the ‘-l’ option.
To list the contents of a compressed archive called ‘project.tar.gz’, type:
$ tar -tvf project.tar
3- Extracting contents from an Archive File
To extract (or unpack) the contents of a tar archive, use tar with the ‘-x’ (“extract”) option.
To extract the contents of an archive called ‘project.tar’, type:
$ tar -xvf project.tar
This command extracts the contents of the ‘project.tar’ archive into the current directory.
If an archive is compressed, which usually means it will have a ‘.tar.gz’ or ‘.tgz’ extension, include the ‘-z’ option.
To extract the contents of a compressed archive called ‘project.tar.gz’, type:
$ tar -zxvf project.tar.gz
NOTE: If there are files or subdirectories in the current directory with the same name as any of those in the archive, those files will be overwritten when the archive is extracted. If you don’t know what files are included in an archive, consider listing the contents of the archive first.
Another reason to list the contents of an archive before extracting them is to determine whether the files in the archive are contained in a directory. If not, and the current directory contains many unrelated files, you might confuse them with the files extracted from the archive.
To extract the files into a directory of their own, make a new directory, move the archive to that directory, and change to that directory, where you can then extract the files from the archive.
Now that we have learned how to create an Archive file and list/extract its contents, we can move on to discuss the following 9 practical questions that are frequently asked by Linux professionals.
- Can we add content to an archive file without unpacking it?
Unfortunately, once a file has been compressed there is no way to add content to it. You would have to “unpack” it or extract the contents, edit or add content, and then compress the file again. If it’s a small file this process will not take long. If it’s a larger file then be prepared for it to take a while.
- Can we delete content from an archive file without unpacking it?
This depends on the version of tar being used. Newer versions of tar will support a –delete.
For example, let’s say we have files file1 and file2 . They can be removed from file.tar with the following:
$ tar -vf file.tar –delete file1 file2
To remove a directory dir1:
$ tar -f file.tar –delete dir1/*
- What are the differences between compressing a folder and archiving it?
The simplest way to look at the difference between archiving and compressing is to look at the end result. When you archive files you are combining multiple files into one. So if we archive 10 100kb files you will end up with one 1000kb file. On the other hand if we compress those files we could end up with a file that is only a few kb or close to 100kb.
- How to compress archive files?
As we saw above you can create and archive files using the tar command with the cvf options. To compress the archive file we made there are two options; run the archive file through compression such as gzip. Or use a compression flag when using the tar command. The most common compression flags are- z for gzip, -j for bzip and -J for xz. We can see the first method below:
$ gzip file.tar
Or we can just use a compression flag when using the tar command, here we’ll see the gzip flag “z”:
$ tar -cvzf file.tar /some/directory
- How to create archives of multiple directories and/or files at one time?
It is not uncommon to be in situations where we want to archive multiple files or directories at once. And it’s not as difficult as you think to tar multiple files and directories at one time. You simply supply which files or directories you want to tar as arguments to the tar command:
$ tar -cvzf file.tar file1 file2 file3
or
$ tar -cvzf file.tar /some/directory1 /some/directory2
- How to skip directories and/or files when creating an archive?
You may run into a situation where you want to archive a directory or file but you don’t need certain files to be archived. To avoid archiving those files or “exclude” them you would use the –exclude option with tar:
$ tar –exclude ‘/some/directory’ -cvf file.tar /home/user
So in this example /home/user would be archived but it would exclude the /some/directory if it was under /home/user. It’s important that you put the –exclude option before the source and destination as well as to encapsulate the file or directory being excluded with single quotation marks.
Summary
The tar command is useful for creating backups or compressing files you no longer need. It’s good practice to back up files before changing them. If something doesn’t work how it’s intended to after the change you will always be able to revert back to the old file. Compressing files no longer in use helps keep systems clean and lowers the disk space usage. There are other utilities available but tar has reigned supreme for its versatility, ease of use and popularity.
Resources
If you like to learn more about Linux, reading the following articles and tutorials are highly recommended:
- Comprehensive Review of Linux File System Architecture and Management
- Comprehensive Review of How Linux File and Directory System Works
- Comprehensive list of all Linux OS distributions
- Comprehensive list of all special purpose Linux distributions
- Linux System Admin Guide- Best Practices for Making and Managing Backup Operations
- Linux System Admin Guide- Overview of Linux Virtual Memory and Disk Buffer Cache
- Linux System Admin Guide- Best Practices for Monitoring Linux Systems
- Linux System Admin Guide- Best Practices for Performing Linux Boots and Shutdowns
About the Authors
Matt Zand is a serial entrepreneur and the founder of 3 tech startups: DC Web Makers, Coding Bootcamps and High School Technology Services. He is a leading author of Hands-on Smart Contract Development with Hyperledger Fabric book by O’Reilly Media. He has written more than 100 technical articles and tutorials on blockchain development for Hyperledger, Ethereum and Corda R3 platforms. At DC Web Makers, he leads a team of blockchain experts for consulting and deploying enterprise decentralized applications. As chief architect, he has designed and developed blockchain courses and training programs for Coding Bootcamps. He has a master’s degree in business management from the University of Maryland. Prior to blockchain development and consulting, he worked as senior web and mobile App developer and consultant, angel investor, business advisor for a few startup companies. You can connect with him on LI: https://www.linkedin.com/in/matt-zand-64047871
Kevin Downs is Red Hat Certified System Administrator or RHCSA. At his current job at IBM as Sys Admin, he is in charge of administering hundreds of servers running on different Linux distributions. He is a Lead Linux Instructor at Coding Bootcamps where he has authored 5 self-paced Courses.
The post How to Create and Manage Archive Files in Linux appeared first on Linux Foundation – Training.