The Kubernetes 1.11 release became generally available on June 27, providing users of the container orchestration with multiple new features and continued performance improvements.
While Kubernetes releases were originally all led by Google staffers, that has changed in the last two years, with a rigous release management Special Interest Group (SIG) that has mandated that there be a new leader for each release. For the 1.11 release, the role of release lead was held by Red Hat’s Josh Berkus, who is well known in the open-source community for his work helping to lead PostgreSQL database releases.
“What’s similar is the role of the release lead: marshaling all of the independent teams and contributors required to put out a release, including developers of each feature, documentation, release notes, PR, builds, and bug fixing,” Berkus said. “Being a release lead is like playing pinball with 8 balls, and you’re the flipper; it’s not your job to actually fix anything, it’s your job to keep everything in motion and progressing. There’s a lot of nagging involved.”
As an open-source and mobile developer, I’ve had the opportunity to work on some unique projects in places where both man-made and natural disasters have severely affected people and communities. During my time in Haiti working with organizations helping those impacted by the devastating 2010 earthquake, for example, I learned how to take on challenges to assist those in need and simultaneously cope with more adversity than the average development project would require.
After the earthquake and through my experiences with other projects, I learned a lot about the deployment of mobile capabilities and devices after a natural disaster. Here are some important considerations, particularly for developers who might be considering creating solutions for the Call for Code.
Blockchain technology is transforming industries and bringing new levels of trust to contracts, payment processing, asset protection, and supply chain management. Blockchain-related jobs are the second-fastest growing in today’s labor market, according to TechCrunch. But, as in the rapidly expanding field of artificial intelligence, there is a pronounced blockchain skills gap and a need for expert training resources.
Blockchain for Business
A new training option was recently announced from The Linux Foundation. Enrollment is now open for a free training course called Blockchain: Understanding Its Uses and Implications, as well as a Blockchain for Businessprofessional certificate program. Delivered through the edX training platform, the new course and program provide a way to learn about the impact of blockchain technologies and a means to demonstrate that knowledge. Certification, in particular, can make a difference for anyone looking to work in the blockchain arena.
“In the span of only a year or two, blockchain has gone from something seen only as related to cryptocurrencies to a necessity for businesses across a wide variety of industries,” said Linux Foundation General Manager, Training & Certification Clyde Seepersad. “Providing a free introductory course designed not only for technical staff but business professionals will help improve understanding of this important technology, while offering a certificate program through edX will enable professionals from all over the world to clearly demonstrate their expertise.”
TechCrunch also reports that venture capital is rapidly flowing toward blockchain-focused startups. And, this new program is designed for business professionals who need to understand the potential – or threat – of blockchain to their company and industry.
“Professional Certificate programs on edX deliver career-relevant education in a flexible, affordable way, by focusing on the critical skills industry leaders and successful professionals are seeking today,” said Anant Agarwal, edX CEO and MIT Professor.
Hyperledger Fabric
The Linux Foundation is steward to many valuable blockchain resources and includes some notable community members. In fact, a recent New York Times article — “The People Leading the Blockchain Revolution” — named Brian Behlendorf, Executive Director of The Linux Foundation’s Hyperledger Project, one of the top influential voices in the blockchain world.
Hyperledger offers proven paths for gaining credibility and skills in the blockchain space. For example, the project offers a free course titled Introduction to Hyperledger Fabric for Developers. Fabric has emerged as a key open source toolset in the blockchain world. Through the Hyperledger project, you can also take the B9-lab Certified Hyperledger Fabric Developer course. More information on both courses is available here.
“As you can imagine, someone needs to do the actual coding when companies move to experiment and replace their legacy systems with blockchain implementations,” states the Hyperledger website. “With training, you could gain serious first-mover advantage.”
Developers and operators are using a combination of PaaS, containers, and serverless to build new cloud-native applications as well as refactor existing applications. They are also focused on integrating these new technologies with existing environments, while also looking for flexibility to adapt to new technologies. The Cloud Foundry community, in particular, continues to work hard to pull in new technologies — like Kubernetes, Istio, Envoy, and many others — to ensure the Cloud Foundry platform continues to evolve to meet the needs of our growing user base.
The crossover among these technologies is fascinating. While 77 percent of respondents report using a PaaS alone, a full 64 percent report using a combination of PaaS and containers while 43 percent report using a combination of PaaS and serverless. You can see how IT decision makers have adopted a “choose your own adventure” approach as they make use of a wide array of cloud-native technologies.
Last month, a critical vulnerability in the basic Linux network infrastructure was discovered by Felix Wilhelm from Google’s Security Team and disclosed by Red Hat product security.
The attack exploits a problem in the processing of Dynamic Host Configuration Protocol (DHCP) messages, which is the way machines automatically set up their network connectivity. A command injection vulnerability was found in a script included in the DHCP client (dhclient) packages, allowing an attacker to pose as a legitimate DHCP server, sending specially crafted packets containing malicious commands that a DHCP client may unsuspectingly execute. This vulnerability affects Red Hat commercial Enterprise Linux 6 and 7 and the various Linux derivative distros such as Fedora & CentOS.
Taking this vulnerability as an example, we can see how a traditional “shared responsibility” model of security between cloud providers and their customers becomes less effective for containerized workloads. As network plugins have become the standard way of providing networking between containers, cloud providers have not stepped up their own responsibility for securing containers, leaving security and operations teams struggling when patching becomes insufficient to secure their containerized applications.
Since the release of Helm 2 in 2016, Kubernetes has seen explosive growth and major feature additions. Role-Based Access Control (RBAC) was added. Many new resource types have been introduced. Custom Resource Definitions (CRDs) were invented. And most importantly, a set of best practices emerged. Throughout all of these changes, Helm continued to serve the needs of Kubernetes users. But it became evident to us that now was the time to introduce some major changes so that Helm can continue to meet the needs of this evolving ecosystem.
This brings us to Helm 3. In what follows, I’ll preview some of the new things on the roadmap. …
Work on Objects, not YAML Chunks
We repeatedly hear our users asking for the ability to inspect and modify Kubernetes resources as objects, not as strings. But they are equally adamant that however we would choose to provide this, it must be easy to learn and well supported in the ecosystem.
After months of investigating, we decided to provide an embedded scripting language that could be sandboxed and customized. In the top 20 languages, there is only one candidate that fits that bill: Lua.
Hello! I was using Wireshark to debug a networking problem today, and I realized I’ve never written a blog post about Wireshark! Wireshark is one of my very favourite networking tools, so let’s fix that 🙂
Wireshark is a really powerful and complicated tool, but in practice I only know how to do a very small number of things with it, and those things are really useful! So in this blog post, I’ll explain the 5 main things I use Wireshark for, and hopefully you’ll have a slightly clearer idea of why it’s useful.
what’s Wireshark?
Wireshark is a graphical network packet analysis tool.
On Mac, you can download & install it from their homepage, and on Debian-based distros you can install it with sudo apt install wireshark. There’s also an official wireshark-dev PPA you can use to get more up-to-date Wireshark versions.
Wireshark looks like this, and it can be a little overwhelming at first. There’s a slightly mysterious search box, and a lot of packets, and how do you even use this thing?
Last August when The Linux Foundation’s Automotive Grade Linux (AGL) project released version 4.0 of its Linux-based Unified Code Base (UCB) reference distribution for automotive in-vehicle infotainment, it also launched a Virtualization Expert Group (EG-VIRT). The workgroup has now released a white paper outlining a “virtualized software defined vehicle architecture” for AGL’s UCB codebase.
The paper explains how virtualization is the key to expanding AGL from IVI into instrument clusters, HUDs, and telematics. Virtualization technology can protect these more safety-critical functions from less secure infotainment applications, as well as reduce costs by replacing electronic hardware components with virtual instances. Virtualization can also enable runtime configurability for sophisticated autonomous and semi-autonomous ADAS applications, as well as ease software updates and streamline compliance with safety critical standards.
The paper also follows several recent AGL announcements including the addition of seven new members: Abalta Technologies, Airbiquity, Bose, EPAM Systems, HERE, Integrated Computer Solutions, and its first Chinese car manufacturer — Sitech Electric Automotive. These new members bring the AGL membership to more than 120.
AGL also revealed that Mercedes-Benz Vans is using its open source platform as a foundation for a new onboard OS for commercial vehicles. AGL will play a key role in the Daimler business unit’s “adVANce” initiative for providing “holistic transport solutions.” These include technologies for integrating connectivity, IoT, innovative hardware, on-demand mobility and rental concepts, and fleet management solutions for both goods and passengers.
The Mercedes-Benz deal follows last year’s announcement that AGL would appear in 2018 Toyota Camry cars. AGL has since expanded to other Toyota cars including the 2018 Prius PHV.
An open-ended approach to virtualization
Originally, the AGL suggested that EG-VIRT would identify a single hypervisor for an upcoming AGL virtualization platform that would help consolidate infotainment, cluster, HUD, and rear-seat entertainment applications over a single multicore SoC. A single hypervisor (such as the new ACRN) may yet emerge as the preferred technology, but the paper instead outlines an architecture that can support multiple, concurrent virtualization schemes. These include hypervisors, system partitioners, and to a lesser extent, containers.
Virtualization benefits for the software defined vehicle
Virtualization will enable what the AGL calls the “software defined vehicle” — a flexible, scalable “autonomous connected automobile whose functions can be customized at run-time.” In addition to boosting security, the proposed virtualization platform offers benefits such as cost reductions, run-time flexibility for the software-defined car, and support for mixed criticality systems:
Software defined autonomous car — AGL will use virtualization to enable runtime configurability and software updates that can be automated and performed remotely. The system will orchestrate multiple applications, including sophisticated autonomous driving software, based on different licenses, security levels, and operating systems.
Cost reductions — The number of electronic control units (ECUs) — and wiring complexity — can be reduced by replacing many ECUs with virtualized instances in a single multi-core powered ECU. In addition, deployment and maintenance can be automated and performed remotely. EG-VIRT cautions, however, that there’s a limit to how many virtual instances can be deployed and how many resources can be shared between VMs without risking software integration complexity.
Security — By separating execution environments such as the CPU, memory, or interfaces, the framework will enable multilevel security, including protection of telematics components connected to the CAN bus. With isolation technology, a security flaw in one application will not affect others. In addition, security can be enhanced with remote patch updates.
Mixed criticality — One reason why real-time operating systems (RTOSes) such as QNX have held onto the lead in automotive telematics is that it’s easier to ensure high criticality levels and comply with Automotive Safety Integrity Level (ASIL) certification under ISO 26262. Yet, Linux can ably host virtualization technologies to coordinate components with different levels of criticality and heterogeneous levels of safety, including RTOS driven components. Because many virtualization techniques have a very limited footprint, they can enable easier ASIL certification, including compliance for concurrent execution of systems with different certification levels.
IVI typically requires the most basic ASIL A certification at most. Instrument cluster and telematics usually need ASIL B, and more advanced functions such as ADAS and digital mirrors require ASIL C or D. At this stage, it would be difficult to develop open source software that is safety-certifiable at the higher levels, says EG-VIRT. Yet, AGL’s virtualization framework will enable proprietary virtualization solutions that can meet these requirements. In the long-term, the Open Source Automation Development Lab is working on potential solutions for Safety Critical Linux that might help AGL meet the requirements using only open source Linux.</ul>
Building an open source interconnect
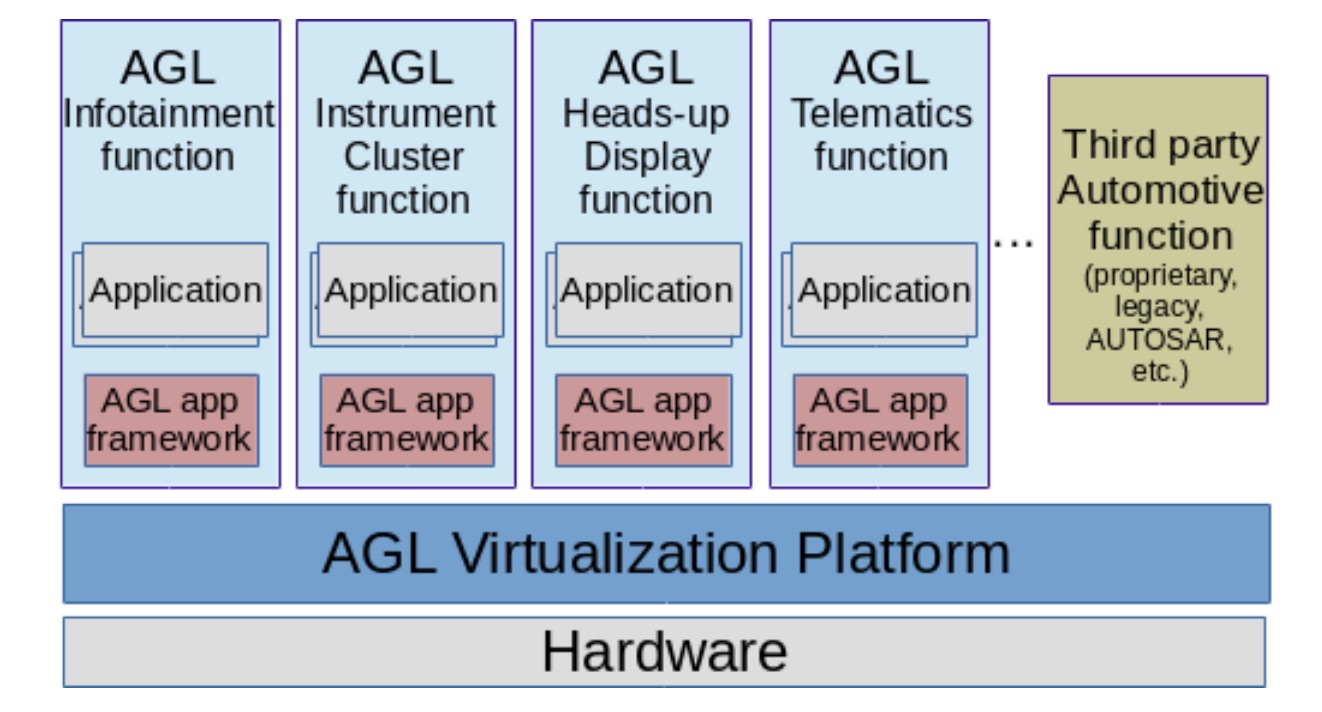
The paper includes the first architecture diagrams for AGL’s emerging virtualization framework. The framework orchestrates different hypervisors, VMs, AGL Profiles, and automotive functions as interchangeable modules that can be plugged in at compilation time, and where possible, at runtime. The framework emphasizes open source technologies, but also supports interoperability with proprietary components.
AGL virtualization approach integrated in the AGL architecture.
The AGL application framework already supports application isolation based on namespaces, cgroups, and SMACK. The framework “relies on files/processes security attributes that are checked by the Linux kernel each time an action processes and that work well combined with secure boot techniques,” says EG-VIRT. However, when multiple applications with different security and safety requirements need to be executed, “the management of these security attributes becomes complex and there is a need of an additional level of isolation to properly isolate these applications from each other…This is where the AGL virtualization platform comes into the picture.”
To meet EG-VIRT’s requirements, compliant hardware virtualization solutions must enable CPU, cache, memory, and interrupts to create execution environments (EEs) such as Arm Virtualization Extensions, Intel VT-x, AMD SVM, and IOMMU. The hardware must also support a trusted computing module to isolate safety-security critical applications and assets. These include Arm TrustZone, Intel Trusted Execution Technology, and others. I/O virtualization support for GPU and connectivity sharing is optional.
The AGL virtualization platform does not need to invent new hypervisors and EEs, but it does need a way to interconnect them. EG-VIRT is now beginning to focus on the development of an open source communication bus architecture that comprises both critical and non-critical buses. The architecture will enable communications between different virtualization technologies such as hypervisors and different virtualized EEs such as VT-x while also enabling direct communication between different types of EEs.
Potential AGL-compliant hypervisors and partitioners
The AGL white paper describes several open source and proprietary candidates for hypervisor and system partitioners. It does not list any containers, which create abstraction starting from the layers above the Linux kernel.
Containers are not ideal for most connected car functions. They lack guaranteed hardware isolation or security enforcement, and although they can run applications, they cannot run a full OS. As a result, AGL will not consider containers for safety and real time workloads, but only within non-safety critical systems, such as for IVI application isolation.
Hypervisors, however, can meet all these requirements and are also optimized for particular multi-core SoCs. “Virtualization provides the best performance in terms of security, isolation and overhead when supported directly by the hardware platform,” says the white paper.
For hypervisors, the open source options listed by EG-VIRT include Xen, Kernel-based Virtual Machine (KVM), the L4Re Micro-Hypervisor, and ACRN. The latter was announced as a new Linux Foundation embedded reference hypervisor project in March. The Intel-backed, BSD-licensed ACRN hypervisor provides workload prioritization and supports real-time and safety-criticality functions. The lightweight ACRN supports other embedded applications in addition to automotive.
Commercial hypervisors that will likely receive support in the AGL virtualization stack include the COQOS Hypervisor SDK, SYSGO PikeOS, and the Xen-based Crucible and Nautilus. The latter was first presented by the Xen Project as a potential solution for AGL virtualization back in 2014. There’s also the Green Hills Software Integrity Multivisor. Green Hills announced AGL support for Integrity earlier this month.
Unlike hypervisors, system partitioners do not tap specific virtualization functions within multi-core SoCs, and instead run as bare-metal solutions. Only two open source options were listed: Jailhouse and the Arm TrustZone based Arm Trusted Firmware (ATF). The only commercial solution included is the TrustZone based VOSYSmonitor.
In conclusion, EG-VIRT notes that this initial list of potential virtualization solutions is “non-exhaustive,” and that “the role of EG-VIRT has been defined as virtualization technology integrator, identifying as key next contribution the development of a communication bus reference implementation…” In addition: “Future EG-VIRT activities will focus on this communication, on extending the AGL support for virtualization (both as a guest and as a host), as well as on IO devices virtualization (e.g., GPU).”
In this tutorial, we will show you how to use the shutdown utility through practical examples and detailed explanations of the most common shutdown options.
The shutdown command brings the system down in a secure way. When the shutdown is initiated, all logged-in users and processes are notified that the system is going down, and no further logins are allowed. You can shut down your system immediately or at the specified time.
Shutdown Command Syntax
Before going into how to use the shutdown command, let’s start by reviewing the basic syntax.
The shutdown utility expressions take the following form:
shutdown [OPTIONS][TIME][MESSAGE]
options – Shutdown options such as halt, power-off (the default option) or reboot the system.
time – The time argument specifies when to perform the shutdown process.
message – The message argument specifies a message which will be broadcast to all users.
As usual there’s been a flurry of activity in the cloud and DevOps security space recently. In case you missed it, a particularly painful flaw was found in Red Hat Enterprise Linux’s DHCP (Dynamic Host Configuration Protocol) service not long ago.
The bug specifically affects RHEL 6 and 7 (and derivative OS, Fedora 28, apparently). The CVE folks allocated the following ID to it in case you want to look it up: CVE-2018-1111. What’s important to note about this discovery is that DHCP (the service which asks a DHCP server for a (usually) temporary IP address and then binds it to one of the host’s network interfaces) is a sometimes forgotten cornerstone of our current tech stacks. Amazon’s EC2 for example shouts out to a DHCP server whenever an instance is spun up. As well as asking for an IP address, your servers will usually pick up DNS servers from DHCP requests, too.
A descendant of BOOTP, a similar service from a time gone by, the pervasive DHCP bug is commonly used on your home networks, your mobile networks and beyond. According to Red Hat the bug affects the “dhclient”, in tandem with the “NetworkManager” daemon, and means that “A malicious DHCP server, or an attacker on the local network able to spoof DHCP responses, could use this flaw to execute arbitrary commands with root privileges on systems using NetworkManager and configured to obtain network configuration using the DHCP protocol.”
At first glance, this vulnerability might make the RHEL naysayers complain that there’s yet another security issue that only affects Red Hat and not other Linux flavors. And, that must therefore mean that the other distributions are better at securing their packages. However, they couldn’t be more wrong.
The commercial model that Red Hat Inc offer is based around supporting enterprises with their products, on a paid-for basis, along with some consultancy on top for good measure. They’ve been very successful and now their products are in use globally on many mission critical opensource server estates. Why is this relevant? Well, aside from the fact that the (free) CentOS Linux flavour benefits from the downstream improvements made by Red Hat, the community as a whole does in addition.
I normally find that it’s hard to know who to believe when a lofty claim is made in the relatively congested Internet giants’ space, However, a report published in November 2017 — called “The State of Open Source Security” — shows some evidence that Red Hat’s Linux might be ruling the roost for security currently. Obviously, I can’t make any guarantees for the report’s impartiality.
Commissioned by Snyk, the report states: “Open source library vulnerabilities increased by 53.8% in 2016, while Red Hat Linux vulnerabilities have decreased.” The report is well-constructed and easy to digest and, as a plumb line to what’s going on the with security on the Internet in general, it’s a welcome read. It states that there’s been a “65% decrease in Red Hat vulnerabilities since 2012” and in addition to that: “In 2016, 69% of Red Hat Linux vulnerabilities were fixed within a day of their public disclosure, and 90% were fixed within 14 days of their public disclosure”.
The report continues: “Red Hat Linux seems to be finding some level of stability” and “…it does make us optimistic that better security is achievable with a little bit of work”.
The truth, of course, is that every device or service has a vulnerability of some description or another, and, as the report states, “there are a lot of steps involved in the lifecycle of an open source security vulnerability. From discovery through final adoption of fixes, each part of the process is important in its own way, and ultimately plays a role in the overall state of security.” Code auditing is key as well as timely response to vulnerabilities. Check out the report to learn more.
Chris Binnie’s latest book, Linux Server Security: Hack and Defend, shows how hackers launch sophisticated attacks to compromise servers, steal data, and crack complex passwords. In the book, he also shows you how to make your servers invisible, perform penetration testing, and mitigate unwelcome attacks. You can find out more about DevOps, DevSecOps, Containers, and Linux security on his website: https://www.devsecops.cc.