As of last year, the Linux operating system was running 90 percent of public cloud workloads; has 62 percent of the embedded market share and runs all of the supercomputers in the TOP500 list, according to The Linux Foundation Open Mainframe Project’s 2018 State of the Open Mainframe Survey report.
Despite a perceived bias that mainframes are behemoths that are costly to run and unreliable, the findings also revealed that more than nine in 10 respondents have an overall positive attitude about mainframe computing.
The project conducted the survey to better understand use of mainframes in general. “If you have this amazing technology, with literally the fastest commercial CPUs on the planet, what are some of the barriers?” said John Mertic, director of program management for the foundation and Open Mainframe Project. “The driver was, there wasn’t any hard data around trends on the mainframe.”
The modern IT infrastructure is diverse by design. People are mixing different open source components that are coming from not only different vendors, but also from different ecosystems. In this article, we talk with Thomas Di Giacomo, CTO of SUSE, about the need for better collaboration between open source projects that are being used across industries as we are move toward a cloud native world.
Linux.com: Does the mix of different open source components create a challenge in terms of a seamless experience for customers? How can these projects work more closely with each other?
Thomas Di Giacomo:Totally, more and more, and it’s unlikely to slow down. It can be because of past investments and decisions, with existing pieces of IT and new ones needed to be added to the mix. Or, it might be because of different teams or different parts of an organization working on their own projects with different timelines etc. Or, again, because companies work with partners coming with their own stacks. But maybe even more importantly, it is also because no single one project can be the only answer on its own to what needs to be done.
Thomas Di Giacomo, CTO of SUSE
An OS needs additional modules and applications on top of it to address use cases. To address use cases, IaaS needs to handle specific networking and storage components that are provided by relevant projects. Infrastructure on its own is pretty useless if it’s not paired with application delivery elements, not only to manage the compute part but to tie in software development and application lifecycle.
Linux.com: Can you point out some industry wide efforts in that direction?
Thomas Di Giacomo: There’s a lot of more or less structured initiatives and approaches to that. On one hand, open source is de facto facilitating cross-project work, not only because the code is visible but with a focus on (open) APIs for instance, but it is also indirectly making it sometimes challenging as more and more open source projects are being started. That’s definitely a great thing for innovation, for people to contribute their ideas, for new ideas to grow, etc., but it requires specific attention and focus on helping users with putting together cross-project solutions they need for achieving their plans. Making sure cross-project solutions are easy to install and maintain, for example, and can co-exist with what’s already there.
What starts to happen is cross-project development, integration, and testing with, for instance, shared CI/CD flows and tools between different project. A good example is what OPNFV has initiated a while ago now, with cross CI/CD between OPNFV, OpenStack, OpenDaylight, and others.
Linux.com: At the same time, certain technologies like Kubernetes cut through many different landscapes — whether it be cloud, IoT, Paas, IaaS, containers, etc. That also means the expectations from traditional OS change. Can you talk about how SUSE Linux Enterprise (SLE) is evolving to handle containerized workloads and transactions/atomic updates?
Thomas Di Giacomo:Yes, indeed. Cutting through many different landscapes is also something Linux did (and still does) — from different CPU architectures, form factors, physical and virtualized, on-prem and public clouds, embedded to mainframes, etc.
But you’re right, although the abstractions are improving — getting to higher levels and better at making the underlying layers become less visible (that’s the whole point of abstracting) — the infrastructure components and even the OS, are still there and foundational for the abstracted layers to work. Hence, they have to evolve to meet today’s needs for portability, agility, stability.
We’ve constantly worked on evolving Linux in the past 26 years now, including some specific directions and optimizations to make SUSE Linux both a great container host OS or container base OS, so that container based technologies and use cases would run as smoothly, securely and infrastructure agnostically as possible. Technically, the snapshotting and transactional upgrade/rollback capabilities coming from btrfs as a filesystem, as well as having different possible container engines, keeping the certification, stability and maintainability of an enterprise-grade OS really makes it uniquely appropriate for running container clusters.
Linux.com: While we are talking about OSes, SUSE has both platforms — traditional SLE and atomic/transactional Kubic/SUSE CaaSP. How do these two projects work together, while making life easier for customers?
Thomas Di Giacomo:There are two angles of “together” here. The first one is our usual community/upstream first philosophy, where Kubic/openSUSE Tumbleweed are the core upstream projects for SUSE CaaS Platform and SUSE Linux Enterprise.
The other “together” is about bringing traditional and container-optimized OS closer together. FIrst, the operating system is required to be super modular, where not just a particular functionality is a module but where everything is a module. Second, the OS needs to be multi-modal. By that we mean it should be designed to take care of requirements for both traditional infrastructure and software-defined/cloud-native container-based infrastructure. This is what the community is putting together with Leap15, and what we’re doing for SUSE Linux Enterprise 15 coming out very soon.
Linux.com: SUSE is known for working with partners, instead of building its own stack. How do you cross-pollinate ideas, talent, and technologies as you (SUSE) work across platforms and projects like SLE, Kubic, Cloud Foundry, and Kubernetes?
Thomas Di Giacomo: We work upstream in the respective open source projects as much as we can. Sometimes some open source components are in different projects or outside upstream, and here again we try to bring them back as much as possible. Let me give just a couple of examples to illustrate that.
We’ve been initiating and contributing to a project called openATTIC, aiming at providing a management tool for storage, software-defined storage solutions, and especially for Ceph. openATTIC is obviously open source like everything we do, but it was sitting outside of Ceph. Working with the Ceph community, we’ve started contributing openATTIC code and features to the upstream ceph dashboard/ceph manager, speeding it up with fueling more existing capabilities rather than re-developing the whole from scratch. And then together with the Ceph partners/community and with other Ceph components, we’re facilitating cross-projects by somehow merging them.
Another example is a SUSE project called Stratos. It is a UI for Cloud Foundry distributions (any one of them, upstream and vendors), which we contributed to Cloud Foundry upstream.
Linux.com: Thanks to Cloud Foundry Container Runtime (CFCR), Cloud Foundry and Kubernetes are working closely, can you tell us about the work SUSE is doing with these two communities?
Thomas Di Giacomo: There are lots of container-related initiatives within the Cloud Foundry Foundation, for instance. Some of them we’re leading, some of them we are involved with, and in any case working together with the community and partner companies on those topics. We, for instance, focus on the containerization of Cloud Foundry itself, so that it is lightweight, portable, easily deployable, upgradable on any type of Kubernetes infrastructure (via Helm), so that containers and services are available to both Kubernetes and Cloud Foundry applications on there, and that actually simply containerized applications and Cloud Foundry developed ones co-exist easily.
So today such a containerized Cloud Foundry is available on top of AKS or EKS, on top of SUSE CaaS Platform obviously as well, as possibly any Kubernetes. This was started a while ago and now part of Cloud Foundry upstream, used by our solutions obviously but also by others to provide the CF developer experience on Kubernetes in the most straightforward and native way as possible. There are other activities focused on providing a pluggable container scheduler for CFCR, as well as improving the cross-interoperable service capabilities.
Now this is currently mostly happening in the CF upstream and CF community, and we’re also working to start a workgroup within CNCF on the same topic (especially the containerization of Cloud Foundry), to bring the projects and their communities closer together.
This article was sponsored by SUSE and written by The Linux Foundation.
Sign up to receive updates on LinuxCon + ContainerCon + CloudOpen China / 注册以接收更新:
SUSE如何将开源项目与社区联结在一起
现代 IT 基础设施因设计而异。人们混合的不仅是来自不同供应商的还包括来自不同生态系统的开源组件。在本文中,我们将与SUSE的首席技术官Thomas Di Giacomo讨论的是:当我们正在迈向云原生世界时,让各行各业使用的开源项目进行更好地协作的必要性。
Thomas Di Giacomo: 这是当然,挑战会越来越多,而且出现的速度不太可能放缓。这可能是因为过去的投资和决策,需要将现有的 IT已有的部分和新的部分添加到混合。或者,这也可能是因为在同一个企业内的不同团队或不同部门在不同的时间表上进行自己的项目。又或者,是因为公司与有其自己节奏的合作伙伴一起工作。但也许更重要的是因为,当面对一个有需要解决问题的项目,不只有一个唯一的方案或答案。
Thomas Di Giacomo: 行业中有很多或多或少的结构化举措和方法。一方面,开源事实上促进了跨项目的工作,不仅因为代码是可见的,还因大家重点关注(开放) API,但这也间接地使其有时更具挑战性,因为越来越多的开源项目正在启动。对于创新来说,这绝对是一件好事,人们可以贡献他们的想法,获得新的想法等等,但需要特别关注并专注于帮助用户制定实现计划所需的跨项目解决方案。确保跨项目解决方案易于安装和维护,并且可与现有解决方案共存。
Today is the first official day of Call for Code, an annual global initiative from creator David Clark Cause, with IBM proudly serving as Founding Partner. Call for Code aims to unleash the collective power of the global open source developer community against the growing threat of natural disasters.
Even as we prepare to accept submissions from technology teams around the world, the response from the technology community has been overwhelming and today I am thrilled to announce two new partners joining the cause.
New Enterprises Associates (NEA) has confirmed its participation as a Partner Affiliate and the official Founding Venture Capital Partner to the cause. With over $20 billion in committed capital and a track record of partnering with entrepreneurs and innovations that have truly changed the world, NEA will extend the Call for Code into the startup and venture capital ecosystem and the Global Prize Winners will have the opportunity to pitch their solution to NEA for evaluation and feedback.
The Cloud Native Computing Foundation (CNCF) has also confirmed it will join the Call for Code as a Gold Sponsor. CNCF will bring invaluable experience and advice for technology teams looking to deploy their solutions across a variety of topologies and real-world constraints.
With NEA and CNCF on board the commitment to the cause is widening, and this is only the beginning. Since making the announcement, technology companies, consumer companies, universities, NGOs and celebrities have all expressed interest in answering or supporting the call. Events have taken place in 50 cities around the world, and many more are planned in coming months, providing training and bringing teams together.
Announced on May 24 by IBM Chairman, President and CEO Ginni Rometty, IBM is investing $30 million over five years as well as technology and resources to help kick start Call for Code to address some of the toughest social issues we face today. The goal is to develop technology solutions that significantly improve disaster preparedness, provide relief from devastation caused by fires, floods, hurricanes, tsunamis and earthquakes, and benefit Call for Code’s charitable partners — the United Nations Human Rights Office and the American Red Cross.
The need was never more apparent. Even as we made the announcement in Paris, Hawaii’s Kilauea volcano was erupting, reportedly destroying more than 450 homes. In recent weeks, Guatemala’s ‘Volcano of Fire’ reportedly left 110 dead and around 200 missing. In a worrying preview to the 2018 Atlantic hurricane Season, two category 4 hurricanes – Aletta and Bud – formed in a matter of days last week.
2017 was in fact one of the worst on record for catastrophic natural disasters, impacted millions of lives and billions of dollars of damage – from heat waves in Australia and sustained extreme heat in Europe to famine from drought in Somalia and massive floods and landslides in South East Asia.
We can’t stop a hurricane or a lava flow from wreaking havoc, but we can work together to predict their path; get much needed supplies into an area before disaster strikes, and help emergency support teams allocate their precariously stretched resources.
Last week, The Weather Company, an IBM business, announced it would make weather APIs available to Call for Code participants for access to data on weather conditions and forecasts. IBM Code Patterns get developer teams up and running in minutes, with access to cloud, data, AI and blockchain technologies.
Of course, the real magic happens when coders code. The open source developer community has helped build so much of the technology that is transforming our world. IBM has been supporting that community for over two decades and together we have helped reinvent the social experience. Our hope is that this community can help transform the experience of so many people impacted by natural disasters in coming years.
To help rally that community the Linux Foundation, a long-term partner for IBM, is lending its support and Linus Torvalds, the creator of Linux, will join a panel of eminent technologists to evaluate submissions.
Less surprising, at least to me, was the enthusiasm IBMers showed in responding to the call. We saw internal celebrations around the world in support of the launch last month and we anticipate a healthy contribution to the cause from the 35,000 developers within IBM, plus of course IBM’s own Corporate Service Corps will help deploy the winning ideas on the ground.
Ultimately, the real measure of success will be the impact Call for Code has on some of the most at-risk communities around the globe, and the lives that are saved and improved. With Call for Code now open, the time to make a difference is now.
The open source world isn’t defined by geography, nor are the communities within it. Open source communities are defined by sharing attitudes, interests, and goals, wherever their participants are. An open source community spans locations, political affiliations, religion, and life experience. There are no boundaries of company, country, or even language. People from all backgrounds with diverse perspectives can get involved. And they do.
It’s this very diversity that makes a healthy community thrive — diversity of thought, diversity of experience, and diversity of opinion. All of these elements make us stronger by giving us opportunities to solve problems together, in the spirit of collaboration….
Open source diversity is good for business. But I’d argue that being part of an open source community is good for you as a human being. Learning to collaborate, to listen to others, to embrace diversity, can make you a better person. When you adopt kindness as a guiding principle, you’re compelled to reflect on the words you use and the promises you make. It makes you more mindful. And when you can let go of the need to always be right, you might even learn and grow.
Programmers are passionate about which development methodology is the best. Is it Agile? Waterfall? Feature Driven Development? Scrum? So everyone took notice when one of the 17 original signers of the seminal Agile Manifestowrote a blog post last month headlined “Developers Should Abandon Agile.”
Further down in his post, 78-year-old Ron Jeffries made a clear distinction between Manifesto Agile — “the core ideas from the Manifesto, in which I still believe” — and its usurping follower, “Faux Agile” (or, in extreme cases, “Dark Agile”). Jeffries ultimately urged developers to learn useful development methods — including but not limited to Extreme Programming — that are true to the Manifesto’s original principles, while also detaching their thinking from particular methodologies with an Agile name.
His blog post advocates a world where developers produce running, tested, working, integrated software at shorter and shorter intervals, and designing clean software that avoids complexity and “cruft” by constantly and consistently refactoring code. Managers and product leaders could then always be referred to the software’s latest increment, cultivating a collaborative approach which just might change management’s focus from “do all this” to “do this next.”
The good news about containers, such as Docker‘s, is they make it easy to deploy applications, and you can run far more of them on a server than you can on a virtual machine. The bad news is that putting an application into a container can be difficult. That’s where Buildah comes in.
Buildah is a newly released shell program for efficiently and quickly building Open Container Initiative (OCI) and Dockercompliant images and containers. Buildah simplifies the process of creating, building, and updating images while decreasing the learning curve of the container environment. Better still, for those interested in continuous integration (CI), it’s easily scriptable and can be used in an environment where one needs to spin up containers automatically based on application calls.
Recently, there’s been a lot of turmoil in the systems language community. We have the Rust Evangelism Strikeforce nudging us towards rewriting everything in Rust. We have the C++17 folks who promise the safety and ease of use of modern programming languages with the performance and power of C. And then there’s a long tail of other “systems” programming languages, like Nim, Reason / OCaml, Crystal, Go, and Pony.
Personally, I’m super excited we’re seeing some interesting work in the programming language theory space. This got me excited to learn more about what’s out there. A lot of the problems I solve are usually solved in C. Recently, Go has begun to encroach on C’s territory. I enjoy C and Go as much as the next person …
What Is a Systems Language?
Let’s back up a bit. What is a systems language? Well, I think that depends on where you are in the stack, and who you ask. In general, I would suggest the definition of a systems language is a language that can be used to implement the components your systems runs atop.
The Linux operating system includes a plethora of tools, all of which are ready to help you administer your systems. From simple file and directory tools to very complex security commands, there’s not much you can’t do on Linux. And, although regular desktop users may not need to become familiar with these tools at the command line, they’re mandatory for Linux admins. Why? First, you will have to work with a GUI-less Linux server at some point. Second, command-line tools often offer far more power and flexibility than their GUI alternative.
Determining memory usage is a skill you might need should a particular app go rogue and commandeer system memory. When that happens, it’s handy to know you have a variety of tools available to help you troubleshoot. Or, maybe you need to gather information about a Linux swap partition or detailed information about your installed RAM? There are commands for that as well. Let’s dig into the various Linux command-line tools to help you check into system memory usage. These tools aren’t terribly hard to use, and in this article, I’ll show you five different ways to approach the problem.
I’ll be demonstrating on the Ubuntu Server 18.04 platform. You should, however, find all of these commands available on your distribution of choice. Even better, you shouldn’t need to install a single thing (as most of these tools are included).
With that said, let’s get to work.
top
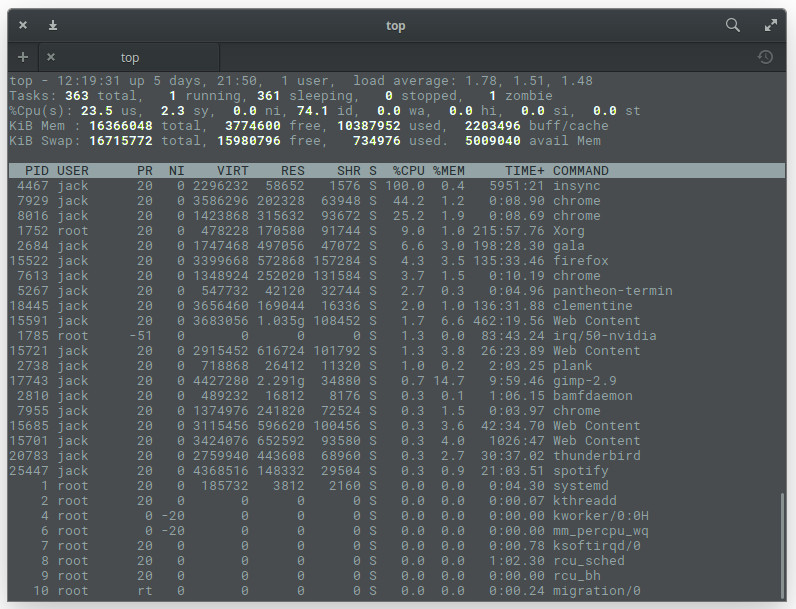
I want to start out with the most obvious tool. Thetopcommand provides a dynamic, real-time view of a running system. Included in that system summary is the ability to check memory usage on a per-process basis. That’s very important, as you could easily have multiple iterations of the same command consuming different amounts of memory. Although you won’t find this on a headless server, say you’ve opened Chrome and noticed your system slowing down. Issue the top command to see that Chrome has numerous processes running (one per tab – Figure 1).
Figure 1: Multiple instances of Chrome appearing in the top command.
Chrome isn’t the only app to show multiple processes. You see the Firefox entry in Figure 1? That’s the primary process for Firefox, whereas the Web Content processes are the open tabs. At the top of the output, you’ll see the system statistics. On my machine (a System76 Leopard Extreme), I have a total of 16GB of RAM available, of which just over 10GB is in use. You can then comb through the list and see what percentage of memory each process is using.
One of the things topis very good for is discovering Process ID (PID) numbers of services that might have gotten out of hand. With those PIDs, you can then set about to troubleshoot (or kill) the offending tasks.
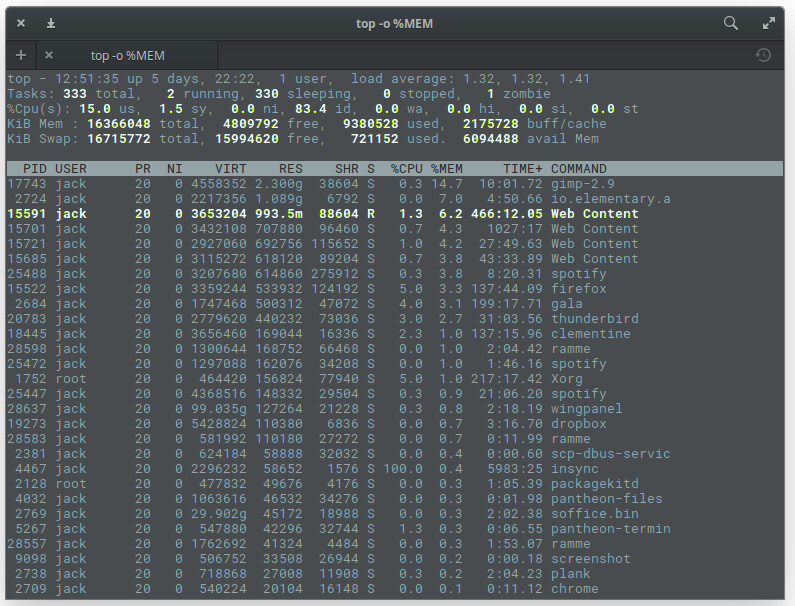
If you want to make topa bit more memory-friendly, issue the command top -o %MEM, which will cause top to sort all processes by memory used (Figure 2).
Figure 2: Sorting process by memory used in top.
The topcommand also gives you a real-time update on how much of your swap space is being used.
free
Sometimes, however, top can be a bit much for your needs. You may only need to see the amount of free and used memory on your system. For that, there is the free command. The freecommand displays:
Total amount of free and used physical memory
Total amount of swap memory in the system
Buffers and caches used by the kernel
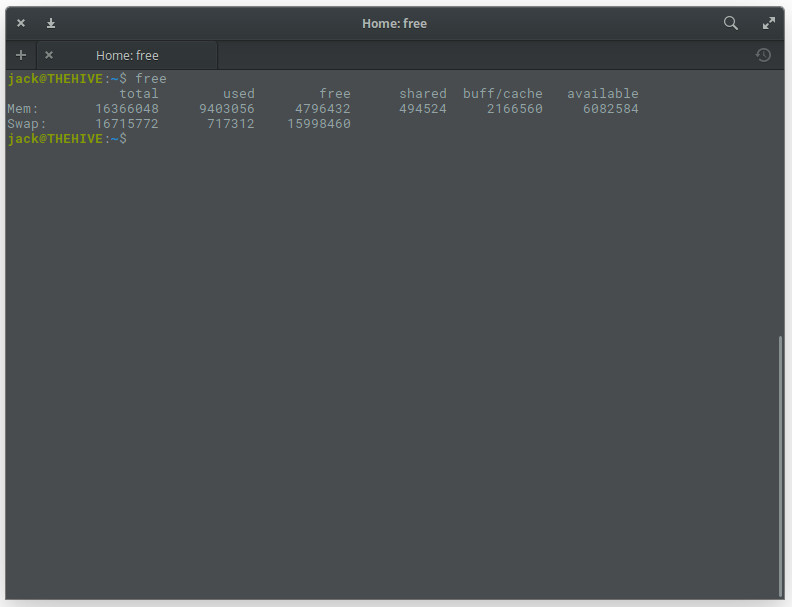
From your terminal window, issue the command free. The output of this command is not in real time. Instead, what you’ll get is an instant snapshot of the free and used memory in that moment (Figure 3).
Figure 3: The output of the free command is simple and clear.
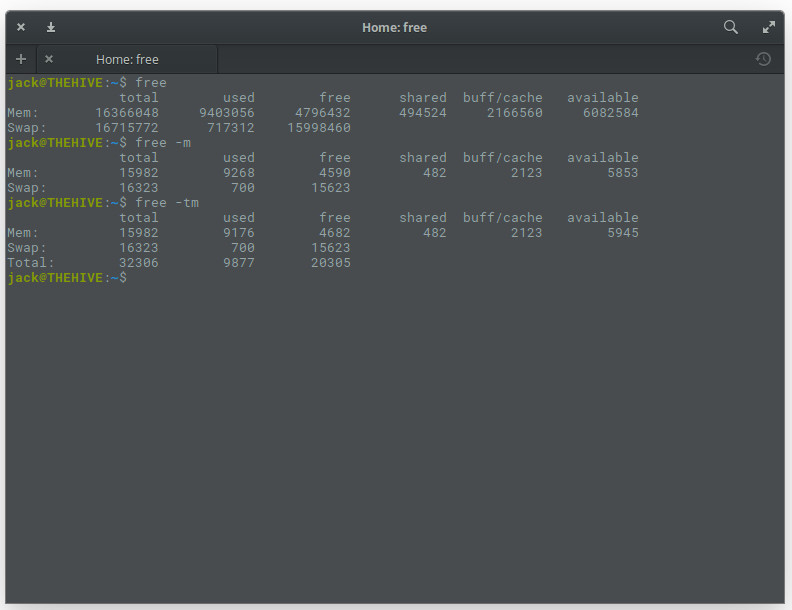
You can, of course, make freea bit more user-friendly by adding the -moption, like so:free -m. This will report the memory usage in MB (Figure 4).
Figure 4: The output of the free command in a more human-readable form.
Of course, if your system is even remotely modern, you’ll want to use the -goption (gigabytes), as in free -g.
If you need memory totals, you can add thet option like so: free -mt. This will simply total the amount of memory in columns (Figure 5).
Figure 5: Having free total your memory columns for you.
vmstat
Another very handy tool to have at your disposal is vmstat. This particular command is a one-trick pony that reports virtual memory statistics. The vmstat command will report stats on:
Processes
Memory
Paging
Block IO
Traps
Disks
CPU
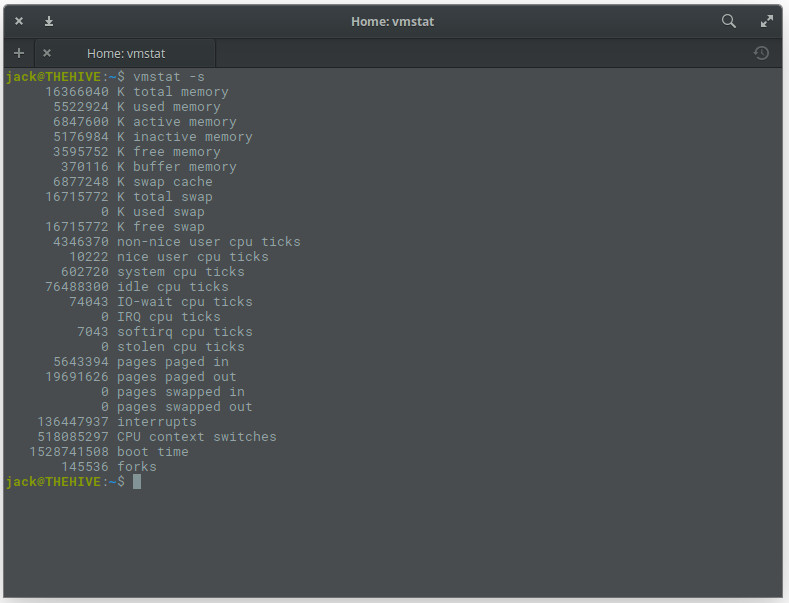
The best way to issue vmstatis by using the -sswitch, like vmstat -s. This will report your stats in a single column (which is so much easier to read than the default report). The vmstatcommand will give you more information than you need (Figure 6), but more is always better (in such cases).
Figure 6: Using the vmstat command to check memory usage.
dmidecode
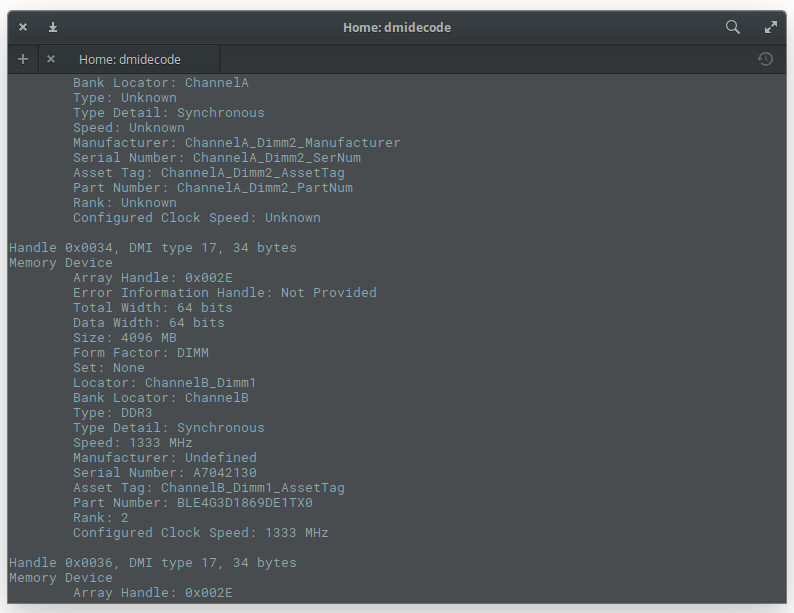
What if you want to find out detailed information about your installed system RAM? For that, you could use the dmidecode command. This particular tool is the DMI table decoder, which dumps a system’s DMI table contents into a human-readable format. If you’re unsure as to what the DMI table is, it’s a means to describe what a system is made of (as well as possible evolutions for a system).
To run the dmidecode command, you do need sudoprivileges. So issue the command sudo dmidecode -t 17. The output of the command (Figure 7) can be lengthy, as it displays information for all memory-type devices. So if you don’t have the ability to scroll, you might want to send the output of that command to a file, like so: sudo dmidecode –t 17 > dmi_infoI, or pipe it to the lesscommand, as in sudo dmidecode | less.
Figure 7: The output of the dmidecode command.
/proc/meminfo
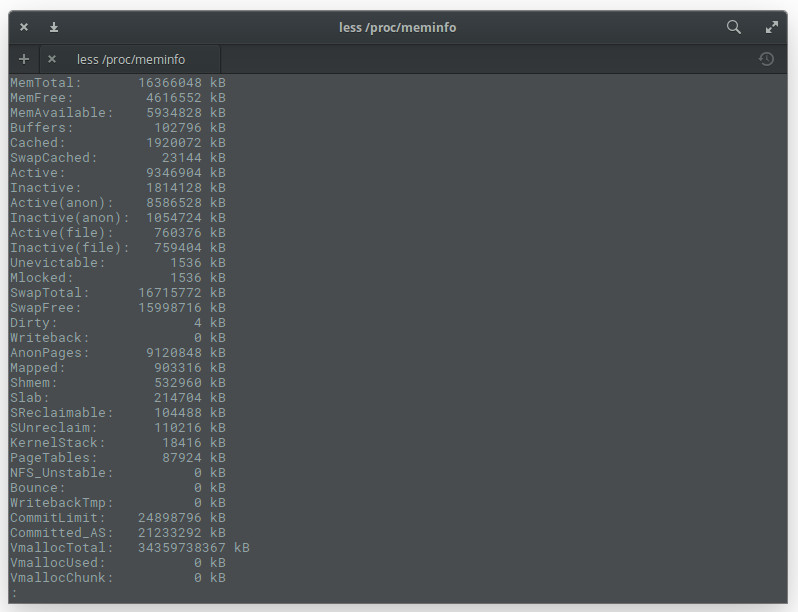
You might be asking yourself, “Where do these commands get this information from?”. In some cases, they get it from the /proc/meminfo file. Guess what? You can read that file directly with the commandless /proc/meminfo. By using the lesscommand, you can scroll up and down through that lengthy output to find exactly what you need (Figure 8).
Figure 8: The output of the less /proc/meminfo command.
One thing you should know about /proc/meminfo: This is not a real file. Instead /pro/meminfo is a virtual file that contains real-time, dynamic information about the system. In particular, you’ll want to check the values for:
MemTotal
MemFree
MemAvailable
Buffers
Cached
SwapCached
SwapTotal
SwapFree
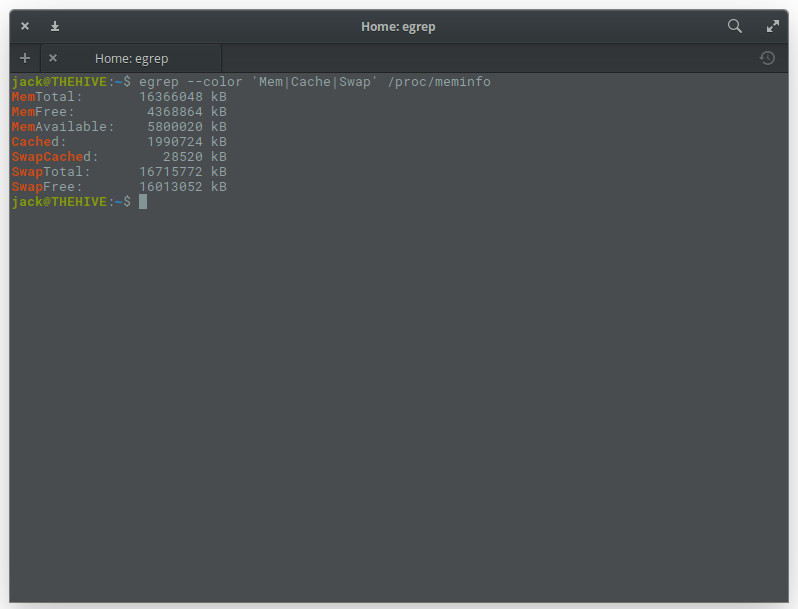
If you want to get fancy with /proc/meminfo you can use it in conjunction with the egrep command like so: egrep –color ‘Mem|Cache|Swap’ /proc/meminfo. This will produce an easy to read listing of all entries that contain Mem, Cache, and Swap … with a splash of color (Figure 9).
Figure 9: Making /proc/meminfo easier to read.
Keep learning
One of the first things you should do is read the manual pages for each of these commands (so man top, man free, man vmstat, man dmidecode). Starting with the man pages for commands is always a great way to learn so much more about how a tool works on Linux.
Learn more about Linux through the free “Introduction to Linux” course from The Linux Foundation and edX.
It’s GIF’s 31st anniversary — exciting, right? Those animated images have truly changed the world. All kidding aside, it is pretty amazing that the file format came to be way back in 1987!
To celebrate tomorrow’s milestone, Google releases a new open source tool today. Called “GIF for CLI,” it can convert a Graphics Interchange Format image into ASCII art for terminal. You can see such an example in the image above.
“Just in time for the 31st anniversary of the GIF, GIF for CLI is available today on GitHub. GIF for CLI takes in a GIF, short video, or a query to the Tenor GIF API and converts it to animated ASCII art. This means each time you log on to your programming workstation, your GIF is there to greet you in ASCII form. Animation and color support are performed using ANSI escape sequences,” says Sean Hayes, Tenor.
A supercomputer, of course, isn’t really a “computer.” It’s not one giant processor sitting atop an even larger motherboard. Instead, it’s a network of thousands of computers tied together to form a single whole, dedicated to a singular set of tasks. They tend to be really fast, but according to the folks at the International Supercomputing Conference, speed is not a prerequisite for being a supercomputer.
But speed does help them process tons of data quickly to help solve some of the world’s most pressing problems. Summit, for example, is already booked for things such as cancer research; energy research, to model a fusion reactor and its magnetically confined plasma tohasten commercial development of fusion energy; and medical research using AI, centering around identifying patterns in the function and evolution of human proteins and cellular systems to increase understanding of Alzheimer’s, heart disease, or addiction, and to inform the drug discovery process.