BuildKit is a new project under the Moby umbrella for building and packaging software using containers. It’s a new codebase meant to replace the internals of the current build features in the Moby Engine.
BuildKit emerged from the discussions about improving the build features in Moby Engine. We received a lot of positive feedback for the multi-stage build feature introduced in April and had proposals and user requests for many similar additions. But before that, we needed to make sure that we have capabilities to continue adding such features in the future and a solid foundation to extend on. Quite soon it was clear that we would need to redefine most of the fundamentals about how we even define a build operation and needed a clean break from the current codebase.
Fn, a new serverless open source project was announced at this year’s JavaOne. There’s no risk of cloud lock-in and you can write functions in your favorite programming language. “You can make anything, including existing libraries, into a function by packaging it in a Docker container.” We invited Bob Quillin, VP for the Oracle Container Group to talk about Fn, its best features, next milestones and more.
JAXenter: Oracle’s Mike Lehmann told us recently that “Oracle sees serverless as a natural next step from where the industry has gone from app server-centric models to containers and microservices and more recently with serverless.” At JavaOne 2017, Mark Cavage discussed Java’s pervasiveness in the cloud and the need to support container-centric microservices and serverless architectures. Why the sudden interest in serverless?
Bob Quillin:Developer efficiency, economics, and ease of use will drive serverless forward. We believe serverless technology will drive a new, more efficient economic model – for both development teams and cloud providers while making a developer’s life that much easier.
AT&T says it’s not enough to deploy white box hardware and to orchestrate its networks with the Open Network Automation Platform (ONAP) software. “Each individual machine also needs its own operating system,” writes Chris Rice, senior vice president of AT&T Labs, Domain 2.0 Architecture, in a blog post. To that end, AT&T announced its newest effort — the Open Architecture for a Disaggregated Network Operating System (dNOS).
“If we want to take full advantage of the benefits of white box routers and other hardware, we need an equally open and flexible operating system for those machines,” writes Rice.
DNOS appears to be in the visionary phase. “Our goal is to start an industry discussion on technical feasibility … and determine suitable vehicles (standards bodies, open source efforts, consortia, etc.) for common specification and architectural realization,” according to an AT&T white paper, introducing dNOS.
Fifteen people from 13 different countries have received Linux Foundation Training Scholarships (LiFT) in the category of Linux Newbies. This year, 27 people received scholarships across all categories —the most ever awarded by the Foundation.
Now in its seventh year, the program awards training scholarships to current and aspiring IT professionals worldwide who may not otherwise have the means for specialized training. The Foundation has awarded 75 scholarships worth more than $168,000 since the program began.
This year, The Linux Foundation received a record 1,238 applications for 14 scholarships, which are typically given to two people in seven categories. However, the quality of the applications in the Linux Newbies category was so high that the Foundation chose to award an unprecedented 15 scholarships in that category alone.
To qualify, candidates must demonstrate they want to contribute to the advancement of Linux and open source software and help influence their future. Applicants can be located anywhere in the world and must show a passion for these technologies and a proven interest in becoming an open source professional.
Linux Newbies
The 15 recipients in the Linux Newbies category are new to Linux but have learned the basics by completing the Intro to Linux online course. These recipients have been awarded scholarships to take the next course in this career-focused series: Essentials of System Administration along with the Linux Foundation Certified System Administrator exam.
They are:
AlexanderAnderson, 28, United Kingdom
Alexander starting coding in PHP at 14 years old, and currently runs Debian as his primary operating system. He hopes this scholarship will help him establish a career in open source so he can better care for his wife, who is disabled.
Fatma Aymaz, 28, Turkey
Fatma Aymaz
Fatma was raised in a region where most people believed women should not receive an education. She fought for the ability to attend school and eventually received a university degree in international relations. She is interested in programming and Linux and hopes to take this opportunity to make a move and establish a career in open source computer science. Her dream is to study and change herself and the world.
Jules Bashizi Irenge, 36, United Kingdom
Jules Bashizi Irenge
Jules is seeking asylum from Congo. He has earned a Masters in Computer Science from the University of Liverpool. He is a long-time Linux user, having completed his undergraduate project on CentOS 6. He hopes to go on to complete a Ph.D. program in computer science and use Linux for future research projects. Jules says he is passionate about Linux and in the future he wants to learn about kernel programming.
Cruzita Thalia Cabunoc, 21, Philippines
Cruzita Thalia Cabunoc
Cruzita is a student at the Technological Institute of the Philippines-Quezon City, where she is currently studying Computer Engineering. She found shell scripting intriguing while taking Intro to Linux and now has the goal of becoming a Linux systems administrator after she completes her studies. Cruzita has no experience developing open source software but is interested in taking additional Linux training courses and is open to new knowledge.
Dimitris Grendas, 27, Greece
Dimitris Grendas
Dimitris has studied informatics and cybersecurity at two different universities and hopes to eventually earn a Master’s degree in cybersecurity. He is preparing to start an internship where he will compile a custom Linux system based on systemd from source code instead of using pre-compiled binary packages. His interests in IT are cybersecurity and networking and looks forward to advancing his IT skills with more education and practice. “I can’t wait to move to my next education step!” he said.
Valentin Ilco, 25, Moldova
Valentin Ilco
Valentin works at the Center of Space Technologies of Technical University of Moldova, where he has helped with development of the first Moldovan satellite, which utilized open source software. He hopes to use even more open source in his future projects. The most interesting about the Intro to Linux to him was learning how Linux can make complex operations and interactions with hardware easier. “The Intro to Linux course put everything in its own place and made a really good base for future development,” he said.
Andreea Ilie, 28, Romania
Andreea Ilie
Andreea studied Japanese and East Asian culture during her university years, but had a strong interest in IT. She taught herself using free online resources in her free time, and eventually managed to secure an IT job despite her lack of formal training and experience. She has a few Python projects hosted on GitHub, and she hopes this scholarship provides her with a stronger knowledge of Linux, and the certification to demonstrate it.
Andreea said she liked that the Linux course “tried to introduce a wide set of topics geared towards a beginner background, explained in a concise way that was easy to understand and not daunting to someone not accustomed to Linux.” She found the background information about the history of Linux and the different distributions interesting “and a welcome addition, which made appreciating the origins and usefulness of this often-dreaded operating system much easier.”
Carlo Martini
Carlo Martini, 27, Italy
Carlo is pursuing a computer science degree at night school. He is active in the Venice Linux Users Group, volunteers to write documentation for the Mozilla Developer Network and is part of the Amara Translating Team for the GitHub. His day job is working for a government-sponsored program for Italian youth, but he hopes this course will help him become a full-time open source professional.
Emmanuel Ongogo, 24, Kenya
Emmanuel Ongogo
Emmanuel holds a computer science degree and is a fan of Ubuntu, using it as his primary operating system since 2013. He has seen an increase in the use of open source in Kenya, including using CentOS to run the recent elections and hopes to encourage it to spread further in the country. “Apart from advancing my career, I would wish to support others who might also have an interest in Linux,” he said.
Darius Palmer, 47, United States
Darius Palmer
Darius is a ward of the state of California, currently living in a halfway house with other formerly incarcerated men. He always had an interest in computers when he was younger, and after completing the free Intro to Linux course, he wants to learn more and eventually become active as a contributor to the Linux community.
Darius said the most interesting of the Intro to Linux course was “the growth and impact that Linux has had on society.” He noted that development of the operating system has provided millions of people with careers and a livelihood. “It’s been involved in the creation of multitudes of extremely profitable entrepreneurial endeavors, such as Google. The Linux kernel has been with this company from day one. But, despite all the influence that Linux has had on the world anyone can download, use and become involved with this software for free. I want to be a part of this phenomenon.”
Andi Rowley, 25, United States
Andi has a drive to learn more about open source as she wants to live in a world where individuals collaborate to improve technology. Since completing Intro to Linux, she has wanted to become a Linux systems administrator and hopes this scholarship will help her accomplish that goal. In her scholarship application, Andi said the most interesting section of the course was how the Linux kernel generates random numbers. “My experience using open source software has been awesome!” she said.
Sara Santos, 46, Portugal
Sara Santos
Sara recently completed a specialized course in managing computer systems and networks but has been unable to secure a job. She is passionate about open source, and would like to work in systems administration, especially with web servers, so expects this scholarship will help her achieve that. “I like the concept of open source software and the community also. I intend to continue for many many years and forward my studies to become an expert,” she said.
Sokunrotanak Srey, 28, Cambodia
Sokunrotanak Srey
Sokunrotanak didn’t study computers but he decided after school to go into the field anyway. He works as an IT technician at non-profit Asian Hope, where he first encountered open source in the form of Ubuntu. He hopes this scholarship will help him improve his skills to better serve Asian Hope and the people it helps. “I love how the Linux community collaborates and helps each other out. I have received lots of help from the community to solve problems in my organization, and I’m looking forward to improving my skill so that I can contribute to the community,” he said.
George Udosen
George Udosen, 42, Nigeria
George originally studied biochemistry, but now has a passion for open source. He would like to learn more and become certified in Linux, so he can pursue a career teaching it and encouraging more people to join the open source community.
Glenda Walter, 28, Dominica
Glenda Walter
Glenda studied building and civil engineering in college, but now wants to become a Linux systems administrator. She has started running CentOS 7 but knows she needs more training before she can make a big career change into open source.
The Google Container Tools team originally built container-diff, a new project to help uncover differences between container images, to aid our own development with containers. We think it can be useful for anyone building containerized software, so we’re excited to release it as open source to the development community.
Containers and the Dockerfile format help make customization of an application’s runtime environment more approachable and easier to understand. While this is a great advantage of using containers in software development, a major drawback is that it can be hard to visualize what changes in a container image will result from a change in the respective Dockerfile. This can lead to bloated images and make tracking down issues difficult.
Imagine a scenario where a developer is working on an application, built on a runtime image maintained by a third-party. During development someone releases a new version of that base image with updated system packages. The developer rebuilds their application and picks up the latest version of the base image, and suddenly their application stops working; it depended on a previous version of one of the installed system packages, but which one? What version was it on before?
In the early days of open source, one of the primary goals of the open source community was educating people about the benefits of open source and why they should use it. Today, open source is ubiquitous. Almost everyone is using it. That has created a unique challenge around educating new users about the open source development model and ensuring that open source projects are sustainable.
Peter Guagenti, the Chief Marketing Officer at Mesosphere, Inc., has comprehensive experience with how open source works, having been involved with several leading open source projects. He has been a coder, but says that he considers himself a hustler. We talked with him about his role at Mesosphere, how to help companies become good open source citizens, and about the role of culture in open source. Here is an edited version of that interview.
By George Kiagiadakis, Senior Software Engineer at Collabora.
Earlier this year I worked on a certain GStreamer plugin that is called “ipcpipeline”. This plugin provides elements that make it possible to interconnect GStreamer pipelines that run in different processes. In this blog post I am going to explain how this plugin works and the reason why you might want to use it in your application.
Why ipcpipeline?
In GStreamer, pipelines are meant to be built and run inside a single process. Normally one wouldn’t even think about involving multiple processes for a single pipeline. You can (and should) involve multiple threads, of course, which is easily done using the queue element, in order to do parallel processing. But since you can involve multiple threads, why would you want to involve multiple processes as well?
Splitting part of a pipeline to a different process is useful when there is one or more elements that need to be isolated for security reasons. Imagine the case where you have an application that uses a hardware video decoder and therefore has device access privileges. Also imagine that in the same pipeline you have elements that download and parse video content directly from a network server, like most Video On Demand applications would do. Although I don’t mean to say that GStreamer is not secure, it can be a good idea to think ahead and make it as hard as possible for an attacker to take advantage of potential security flaws. In theory, maybe someone could exploit a bug in the container parser by sending it crafted data from a fake server and then take control of other things by exploiting those device access privileges, or cause a system crash. ipcpipeline could help to prevent that.
How does it work?
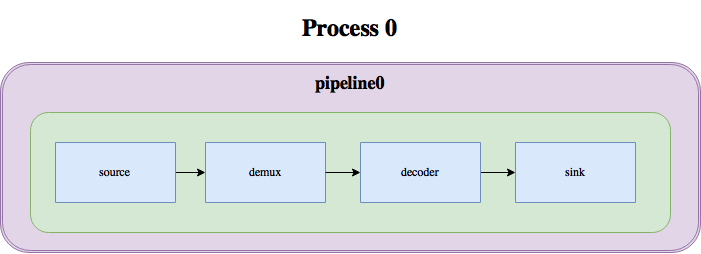
In the – oversimplified – diagram below we can see how the media pipeline in a video player would look like with GStreamer:
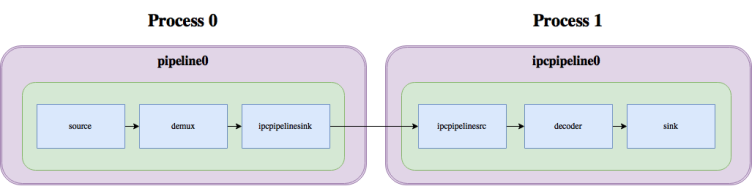
With ipcpipeline, this pipeline can be split into two processes, like this:
As you can see, the split mainly involves 2 elements: ipcpipelinesink, which serves as the sink for the first pipeline, and ipcpipelinesrc, which serves as the source for the second pipeline. These two elements internally talk to each other through a unix pipe or socket, transferring buffers, events, queries and messages over this socket, thus linking the two pipelines together.
This mechanism doesn’t look very special, though. You might be wondering at this point, what is the difference between using ipcpipeline and some other existing mechanism like a pair of fdsink/fdsrc or udpsink/udpsrc or RTP? What is special about these elements is that the two pipelines behave as if they were a single pipeline, with the elements of the second one being part of a GstBin in the first one:
As Michelle Noorali put it in her keynote address at KubeCon Europe in March of this year: the Kubernetesopen source container orchestration engine is still hard for developers. In theory, developers are crazy about Kubernetes and container technologies, because they let them write their application once and then run it anywhere without having to worry about the underlying infrastructure. In reality, however, they still rely on operations in many aspects, which (understandably) dampens their enthusiasm about the disruptive potential of these technologies.
One major downside for developers is that Kubernetes is not able to auto-manage and auto-scale its own machines. As a consequence, operations must get involved every time a worker node is deployed or deleted. Obviously, there are many node deployment solutions, including Terraform, Chef or Puppet, that make ops live much easier.
“How do you run an operating system?” may seem like a simple question, since most of us are accustomed to turning on our computers and seeing our system spin up. However, this common model is only one way of running an operating system. As one of Linux’s greatest strengths is versatility, Linux offers the most methods and environments for running it.
To unleash the full power of Linux, and maybe even find a use for it you hadn’t thought of, consider some less conventional ways of running it — specifically, ones that don’t even require installation on a computer’s hard drive.
We’ll Do It Live!
Live-booting is a surprisingly useful and popular way to get the full Linux experience on the fly. While hard drives are where OSes reside most of the time, they actually can be installed to most major storage media, including CDs, DVDs and USB flash drives.
Recently, while reviewing the FAQ, I came across the question “What’s a Socket?” For those who are not familiar, I shall explain.
In brief, a Unix Socket (technically, the correct name is Unix domain socket, UDS) allows communication between two different processes on either the same machine or different machines in client-server application frameworks. To be more precise, it’s a way of communicating among computers using a standard Unix descriptors file.
Every UNIX systems Input/Output action is executed by writing or reading the descriptor file. A Descriptor file is an open file, which is associated with an integer. It can be a network connection, text file, terminal or something else. It looks and behaves much like a low-level file descriptor. This happens because the commands like read () and write () works with the same way they do with the files and pipes.