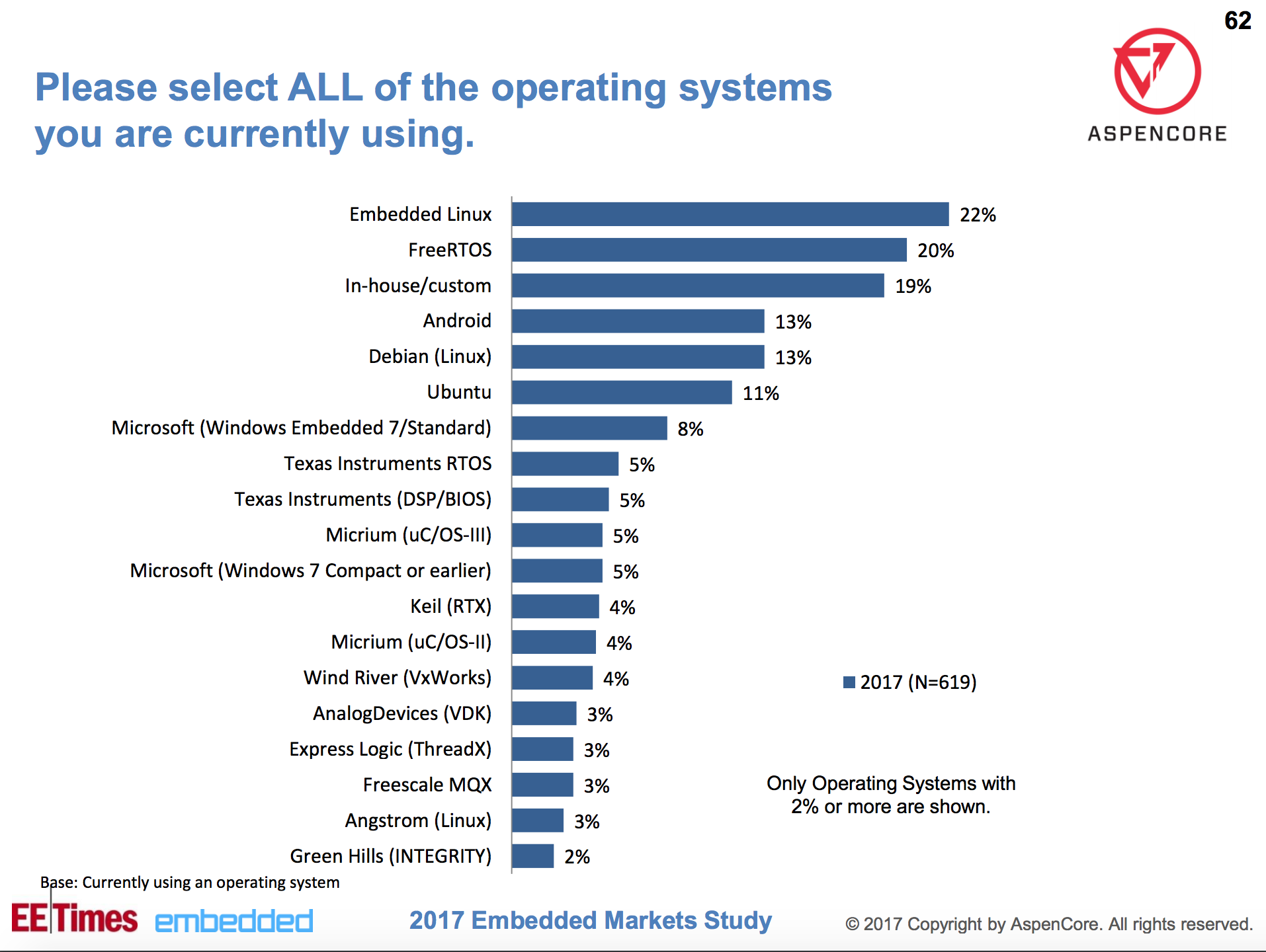
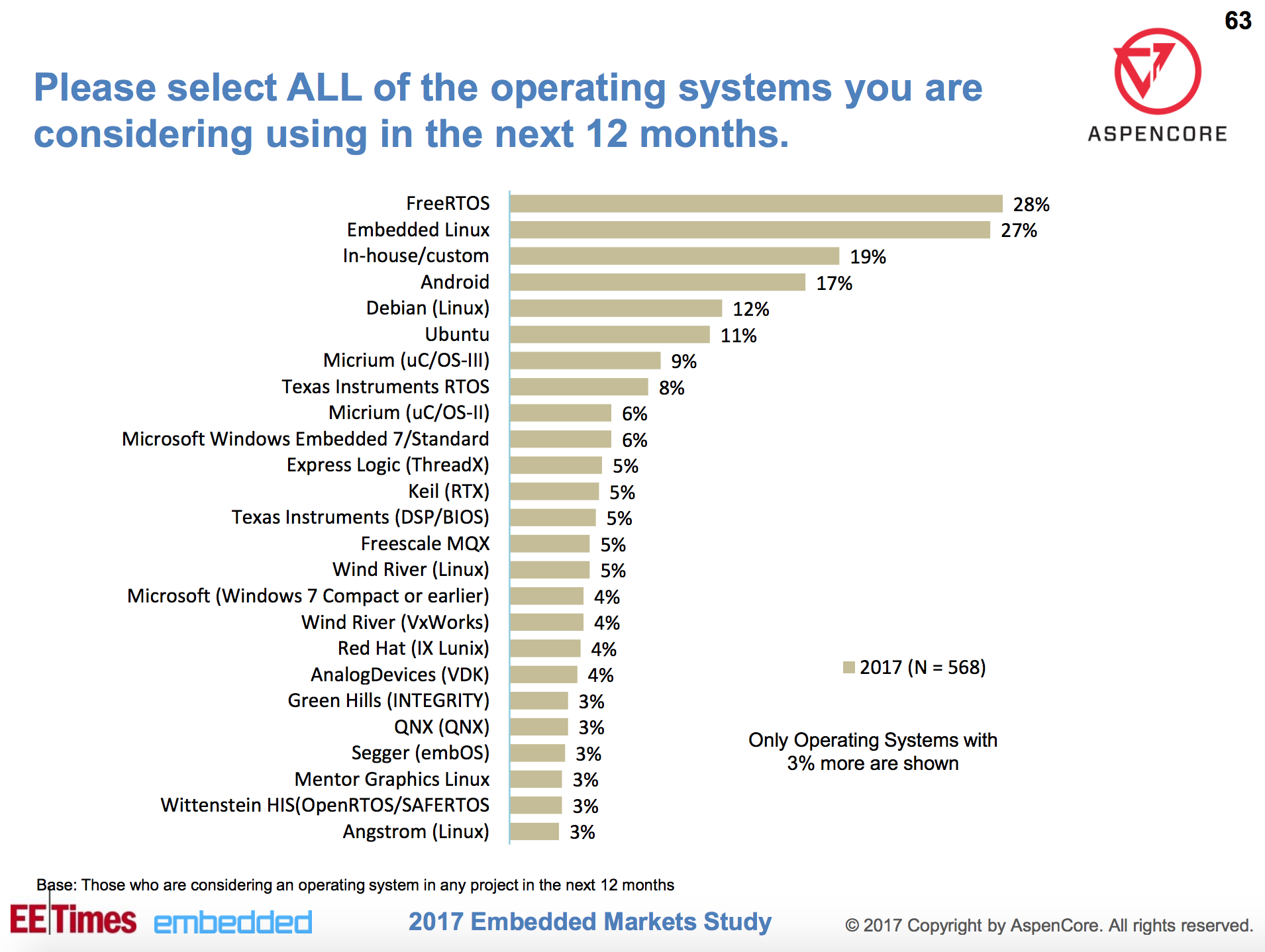
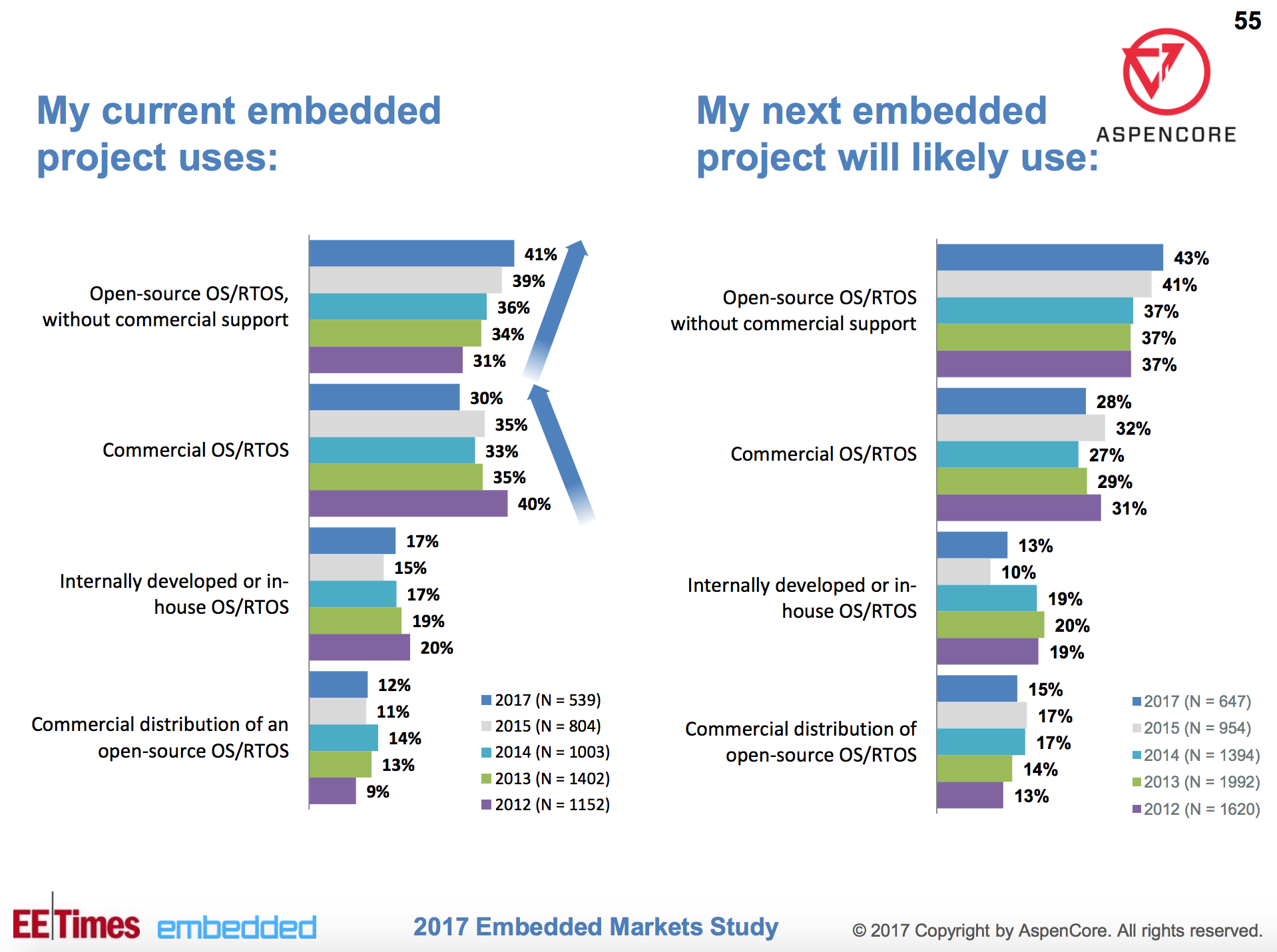
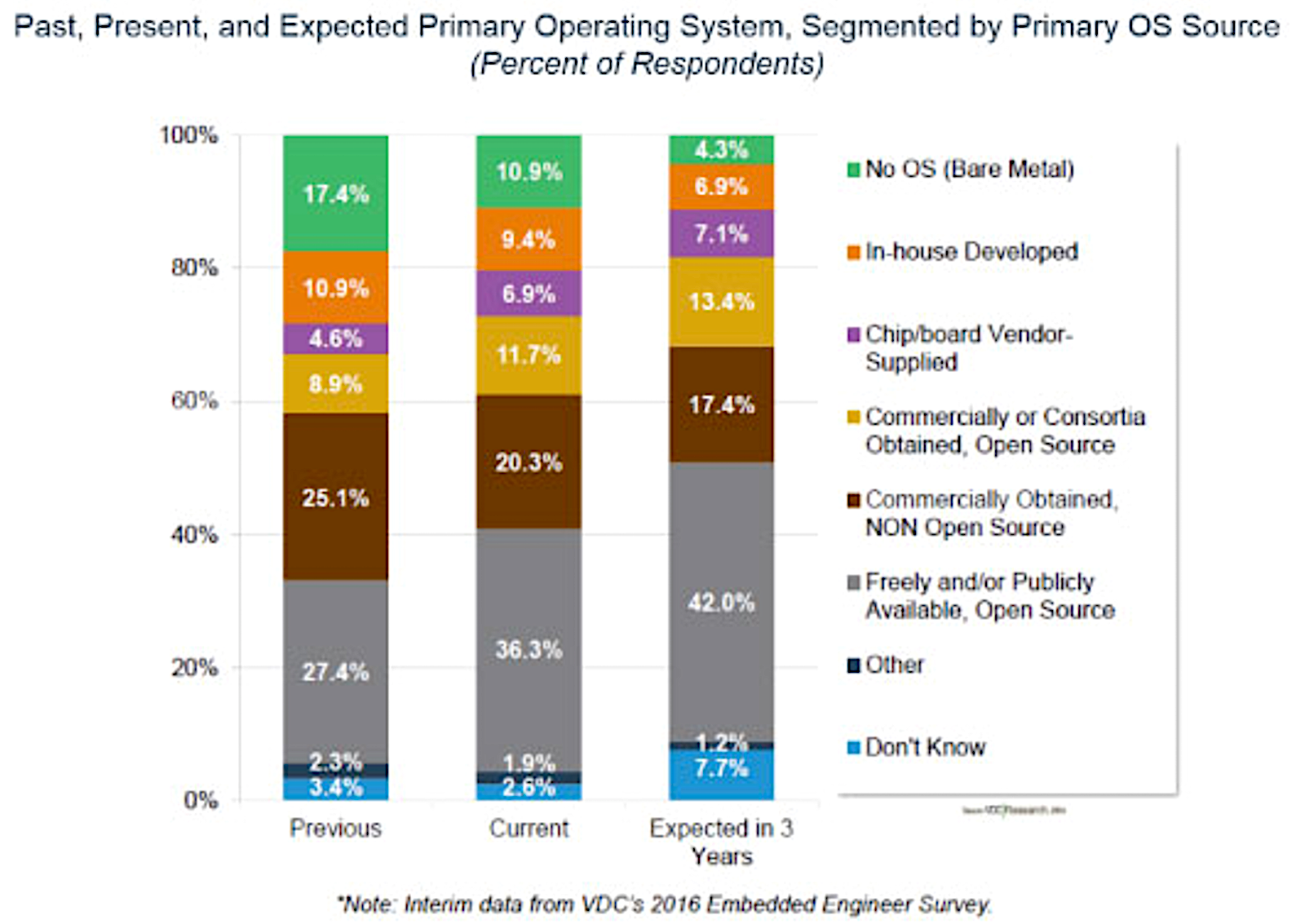
Securing your Docker containers and the hosts upon which they run is key to sustaining reliable and available services. From my professional DevSecOps perspective, securing the containers and the orchestrators (e.g., OpenShift, Docker Swarm, and Kubernetes) is usually far from easy. This is primarily because the goal posts change frequently thanks to the technology evolving at such a rapid pace.
A number of relatively new-world challenges need to be addressed but one thing you can do to make a significant difference is remap your server’s user (UIDs) and group (GIDs) ranges to different user and group ranges within your containers.
With some unchallenging configuration changes, it’s possible to segregate your host’s root user from the root user inside your containers with a not-so-new feature called User Namespaces. This feature has been around since Docker 1.10, which was released sometime around February 2016. I say that it’s a not-so-new feature because anybody that has been following the containerization and orchestration space will know that a feature more than six months old is considered all but an antique!
The lowdown
To get us started, I’ll run through the hands-on methodology of running host-level, or more accurately kernel-level, User Namespaces.
First, here’s a quick reminder of the definitions of two commonly related pieces of terminology when it comes to securing your Docker containers, or many other vendors’ containers for that matter. You might have come across cgroups. These allow a process to be locked down from within the kernel. When I say locked down, I mean we can limit its capacity to take up system resources. That applies to CPU, RAM, and IO, among many aspects of a system.
These are not to be confused with namespaces which control the visibility of a process. You might not want a process to see all of your network stack or other processes running inside the process table for example.
I’ll continue to use Docker as our container runtime example as it’s become so undeniably popular. What we will look at in this article is the remapping of users and groups inside a container with the host’s own processes. For clarity, the “host” being the server that the Docker daemon is running on. And, by extension we will affect the visibility of the container’s processes in order to protect our host.
That remapping of users and groups is known as manipulating User Namespaces to affect a user’s visibility of other processes on the system.
If you’re interested in some further reading then you could do worse than look at the manual on User Namespaces. The man page explains: “User namespaces isolate security-related identifiers and attributes, in particular, user IDs and group IDs…”.
It goes on to say that: “process’s user and group IDs can be different inside and outside a user namespace. In particular, a process can have a normal unprivileged user ID outside a user namespace while at the same time having a user ID of 0 inside the namespace; in other words, the process has full privileges for operations inside the user namespace, but is unprivileged for operations outside the namespace.”
Figure 1 offers some further insight in the segregation that we’re trying to achieve with User Namespaces. You could do worse than look at this page for some more detailed information.

Figure 1: An illustrative view of User Namespaces (Image source: https://endocode.com/blog/2016/01/22/linux-containers-and-user-namespaces)
Seconds out
Let’s clarify what we’re trying to achieve. Our aim is actually very simple; we want to segregate our host’s superuser (the root user which is always UID 0) away from a container’s root user.
The magical result of making these changes is that even if the container’s application runs as the root user and uses UID 0 then in reality the superuser UID only matters inside the container and no longer correlates to the superuser on your host.
Why is this a good thing you may ask? Well, if your container’s application is compromised, then you are safe in the knowledge that an attacker will still have to elevate their privileges if they escape from the container to take control of other services (running as containers) on your host and then ultimately your host itself.
Add a daemon option
It’s important to first enable your Docker daemon option, namely –userns-remap.
It’s worth pointing out at this stage that the last time I checked you will need to use Kubernetes v1.5+ to avoid breaking network namespaces with User Namespaces. Kubernetes simply won’t fire up from what I saw, complaining about Network Namespace issues.
Also, let me reiterate the fact that adding options to your Docker daemon might have changed recently due to a version change. If you’re using a version more than a month old then please accept my sympathies. There is a price for a continued rate of evolution; backward compatibility or a new way of doing things sometimes causes some eye strain. To my mind, there’s little to complain about, however; the technology is fantastic.
It’s for the reason of version confusion that I’ll show you the current way that I add this option to my Docker daemon and as a result your petrol-consumption may of course vary; different versions and different flavors needing additional tweaks. When there’s confusion about versions don’t be concerned if you know of a more efficient way of doing something. In other words, feel free to skip the parts that you know.
And so it begins
The first step is asking our Docker daemon to use for a JSON config file from now on (instead of a text file key=value, Unix-style config) and to do so we’ll add a DOCKER_OPTS to the file /etc/default/docker. It should make adding many options a bit easier in the medium term and stops you from editing systemd unit files with clumsy options.
Inside the file mentioned, we simply add the following line which, erm, points to another config file from now on:
DOCKER_OPTS="--config-file=/etc/docker/daemon.json"
I’m sure you’ve guessed that our newly created /etc/docker/daemon.json file needs to contain formatted JSON. And, in this case, I’ve stripped out other config for simplicity and just added a —userns-remap option as follows.
{
"userns-remap": "default"
}
For older versions (and different Linux distributions) or personal preference, you can probably add this config change directly into /etc/default/docker as DOCKER_OPTS=”–user-remap=default” and not use the JSON config file.
Equally, we can probably fire our Docker daemon up even without a service manager like systemd as shown below.
$ dockerd --userns-remap=default
I hope one of these ways of switching on this option works for you. Google is, as ever, your friend otherwise.
Eleventy-one
At this stage, note that so far I have taken the lazy option in the examples above and simply said “default” for our remapped user. We’ll come back to that in a second — fear not.
You can now jump to the only other mandatory config required to enable User Namespaces, courtesy of our friendly, neighborhood kernel.
Even if you stick to using “default” as I did above you should add these entries to the following files. On Red Hat derivatives, do this before restarting your Docker daemon with the added option shown above. On some distros these files don’t exist yet, so create them (using the echo command as below will do it) if they don’t already.
echo "dockremap:123000:65536" >> /etc/subuid
echo "dockremap:123000:65536" >> /etc/subgid
Restarting your daemon on modern Linux versions looks like this (a reminder that RHEL might be using the docker-latest service and Ubuntu might have required apt install docker.io to install the daemon in the first place amongst other gotchas).
$ systemctl restart docker
Crux of the matter
By adding the “subordinate” dockremap user and group entries to the files above, we are saying that we want to remap container user IDs and group IDs to the host range starting at 123,000. We can in theory use 65,536 above that starting range, but in practice this differs. In “current” versions, Docker actually only maps the first, single UID. Docker has said this will hopefully change in the future.
I mentioned that I’d explain the “default” user setting we used. That value tells the Docker internals to use the username and groupname dockremap as we’ve seen. You can use arbitrary names, but make sure your /etc/subuid and /etc/subgid files reflect the new name before then restarting your daemon.
Other changes
Note that you’ll have to re-pull your container images as they will now live in a new local subdirectory on your host.
If you look under the directory /var/lib/docker you will note our image storage directory is named after our now familiar UID.GID number-formatted range as follows:
$ ls /var/lib/docker
drwx------. 9 dockremap dockremap 4096 Nov 11 11:11 123000.123000/
From here, if you enter your container with a command like this one shown below then you should see that your application is still running as the root user and using UID 0.
$ docker exec -it f73f181d3e bash
On the host, you can run the ps command and see that although the container thought it was using UID 0 (or the root user), actually it’s running as our 123,000 UID.
$ ps -ef | grep redis
If it helps, the command that I use on the host and directly inside containers to get the corresponding numbered UID for comparison with the username — which is displayed by most ps commands — is as follows:
$ ps -eo uid,gid,args
Limitations
As with all added security, there are tradeoffs; however, these aren’t too onerous in the case of User Namespaces.
To start, note that you won’t be able to open up your containers using –net=host or share PIDs with –-pid=host if you use the above config.
Also, be warned that you can’t use a –read-only container, which is effectively a stateless container with User Namespaces.
Additionally, the super-lazy and highly dangerous —privileged mode won’t work with this set up either. Also, you will need to make sure that any filesystems that you mount, such as NFS drives, can allow access to the UIDs and GIDs that you use.
One final gotcha is that Red Hat derivatives, such as CentOS, need to open up the kernel settings via the boot loader to enable User Namespaces. You can achieve this as so using grubby:
$ grubby --args="user_namespace.enable=1"
--update-kernel="$(grubby --default-kernel)"
Having done so, reboot your server for the to take effect. To disable that setting, you can use this command line:
$ grubby --remove-args="user_namespace.enable=1"
--update-kernel="$(grubby --default-kernel)";
The End
I suggest that these simple changes are well worth the effort in relation to bolstering your Docker host’s security.
The last thing that anybody wants is an attacker to sit idle with superuser access on a host for months learning about the weak links in your set up. Also known as an Advanced Persistent Threat, it would be very unwelcome and, of course, might happen entirely without your knowledge. All it takes is for the person who built an image that you pulled off Docker Hub to forget to upgrade a vulnerable library. On that ever so cheery note: Stay vigilant!
Learn more about essential sysadmin skills: Download the Future Proof Your SysAdmin Career ebook now.
Chris Binnie’s latest book, Linux Server Security: Hack and Defend, shows how hackers launch sophisticated attacks to compromise servers, steal data, and crack complex passwords, so you can learn how to defend against these attacks. In the book, he also talks you through making your servers invisible, performing penetration testing, and mitigating unwelcome attacks. You can find out more about DevSecOps and Linux security via his website (http://www.devsecops.cc).