

Ubuntu Linux comes in a few officially recognized flavors, as well as several derivative distributions. The recognized flavors are:
-
Kubuntu – Ubuntu with the KDE desktop
-
Lubuntu – Ubuntu with the LXDE desktop
-
Mythbuntu – Ubuntu MythTV
-
Ubuntu Budgie – Ubuntu with the Budgie desktop
-
Xubuntu – Ubuntu with Xfce
Up until recently, the official Ubuntu Linux included the in-house Unity desktop and a sixth recognized flavor existed: Ubuntu GNOME — Ubuntu with the GNOME desktop environment.
When Mark Shuttleworth decided to nix Unity, the choice was obvious to Canonical—make GNOME the official desktop of Ubuntu Linux. This begins with Ubuntu 18.04 (so April, 2018) and we’ll be down to the official distribution and four recognized flavors.
For those already enmeshed in the Linux community, that’s some seriously simple math to do—you know which Linux desktop you like, so making the choice between Ubuntu, Kubuntu, Lubuntu, Mythbuntu, Ubuntu Budgie, and Xubuntu couldn’t be easier. Those that haven’t already been indoctrinated into the way of Linux won’t see that as such a cut-and-dried decision.
To that end, I thought it might be a good idea to help newer users decide which flavor is best for them. After all, choosing the wrong distribution out of the starting gate can make for a less-than-ideal experience.
And so, if you’re considering a flavor of Ubuntu, and you want your experience to be as painless as possible, read on.
Ubuntu
I’ll begin with the official flavor of Ubuntu. I am also going to warp time a bit and skip Unity, to launch right into the upcoming GNOME-based distribution. Beyond GNOME being an incredibly stable and easy to use desktop environment, there is one very good reason to select the official flavor—support. The official flavor of Ubuntu is commercially supported by Canonical. For $150.00 per year, you can purchase official support for the Ubuntu desktop. There is, of course, a 50-desktop minimum for this level of support. For individuals, the best bet for support would be the Ubuntu Forums, the Ubuntu documentation, or the Community help wiki.
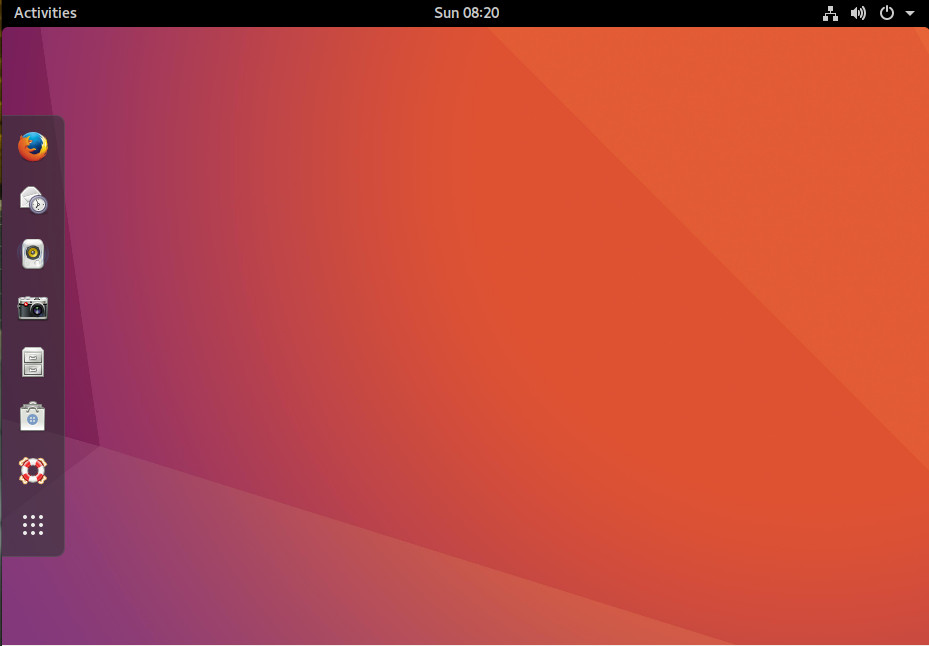
Beyond the commercial support, the reason to choose the official Ubuntu flavor would be if you’re looking for a modern, full-featured desktop that is incredibly reliable and easy to use. GNOME has been designed to serve as a platform perfectly suited for both desktops and laptops (Figure 1). Unlike its predecessor, Unity, GNOME can be far more easily customized to suit your needs—to a point. If you’re not one to tinker with the desktop, fear not, GNOME just works. In fact, the out of the box experience with GNOME might well be one of the finest on the market—even rivaling (or besting) Mac OS X. If tinkering and tweaking is of primary interest, you will find GNOME somewhat limiting. The GNOME Tweak Tool and GNOME Shell Extensions will only take you so far, before you find yourself wanting more.
Kubuntu
The K Desktop Environment (otherwise known as KDE) has been around as long as GNOME and has, at times, been maligned as a lesser desktop. With the release of KDE Plasma 5, that changed. KDE has become an incredibly powerful, efficient, and stable desktop that can stand toe to toe with the best of them. But why would you select Kubuntu over the official Ubuntu? The answer to that question is quite simple—you’re used to the Windows XP/7 desktop metaphor. Start menu, taskbar, system tray, etc., KDE has those and more, all fashioned in such a way that will make you feel like you’re using the best of the past and current technologies. In fact, if you’re looking for one of the most Windows 7-like official Ubuntu flavors, you won’t find one that better fits the bill.
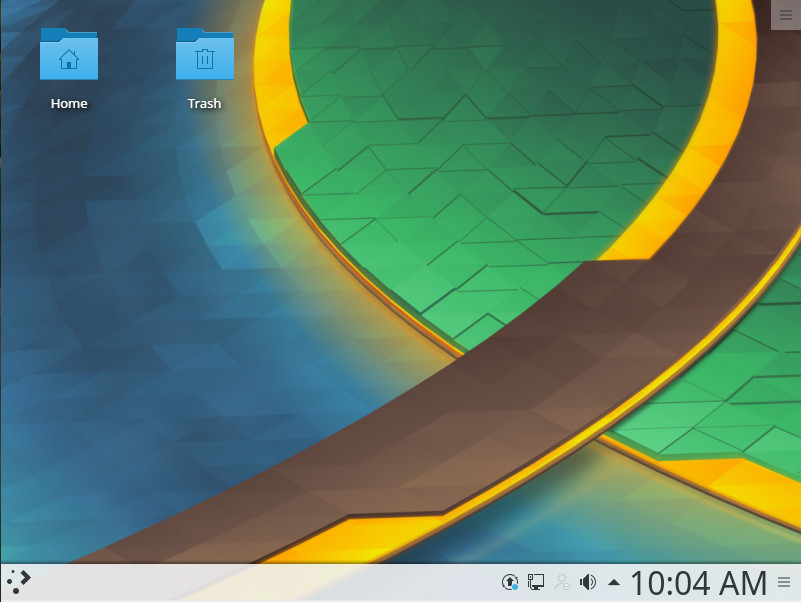
One of the nice things about Kubuntu, is that you’ll find it a bit more flexible than any Windows iteration you’ve ever used—and equally reliable/user-friendly. And don’t think, because KDE opts to offer a desktop somewhat similar to Windows 7, that it doesn’t have a modern flavor. In fact, Kubuntu takes what worked well with the Windows 7 interface and updates it to meet a more modern aesthetic (Figure 2).
The official Ubuntu is not the only flavor to offer desktop support. Kubuntu users also can pay for commercial support. Be warned, it’s not cheap. One hour of support time will cost you $103.88 cents.
Lubuntu
If you’re looking for an easy-to-use desktop that is very fast (so that older hardware will feel like new) and far more flexible than just about any desktop you’ve ever used, Lubuntu is what you want. The only caveat to Lubuntu is that you’re looking at a bit more bare bones on the desktop then you may be accustomed to. Lubuntu makes use of the LXDE desktop and includes a list of applications that continues the lightweight theme. So if you’re looking for blazing fast speeds on the desktop, Lubuntu might be a good choice.
However, there is a caveat with Lubuntu and, for some users, this might be a deal breaker. Along with the small footprint of Lubuntu come pre-installed applications that might not stand up to task. For example, instead of the full-blown office suite, you’ll find the AibWord word processor and the Gnumeric spreadsheet tool. Don’t get me wrong; both of these are fine tools. However, if you’re looking for software that’s business-ready, you will find them lacking. On the other hand, if you want to install more work-centric tools (e.g., LibreOffice), Lubuntu includes the Synaptic Package Manager to make installation of third-party software simple.
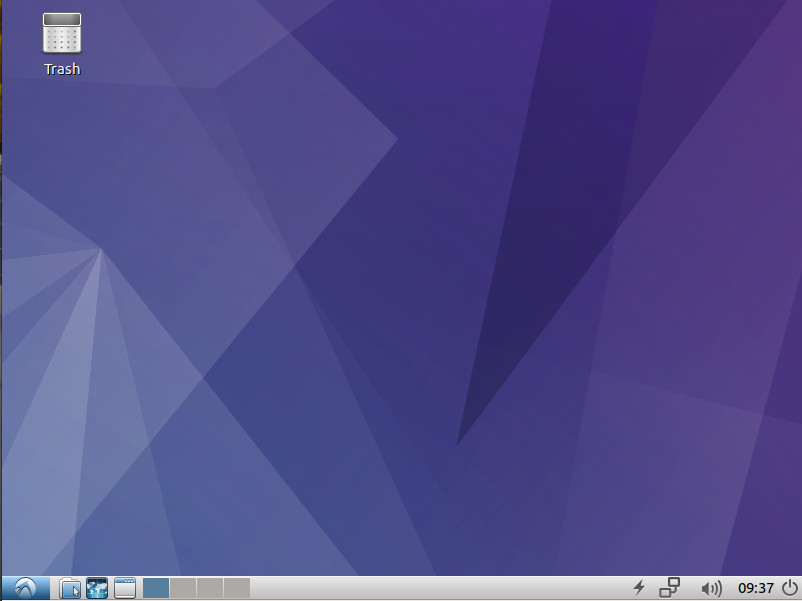
Even with the limited default software, Lubuntu offers a clean and easy to use desktop (Figure 3), that anyone could start using with little to no learning curve.
Mythbuntu
Mythbuntu is a sort of odd bird here, because it isn’t really a desktop variant. Instead, Mythbuntu is a special flavor of Ubuntu designed to be a multimedia powerhouse. Using Mythbuntu requires TV Tuners and TV Out cards. And, during the installation, there are a number of additional steps that must be taken (choosing how to set up the frontend/backend as well as setting up your IR remotes).
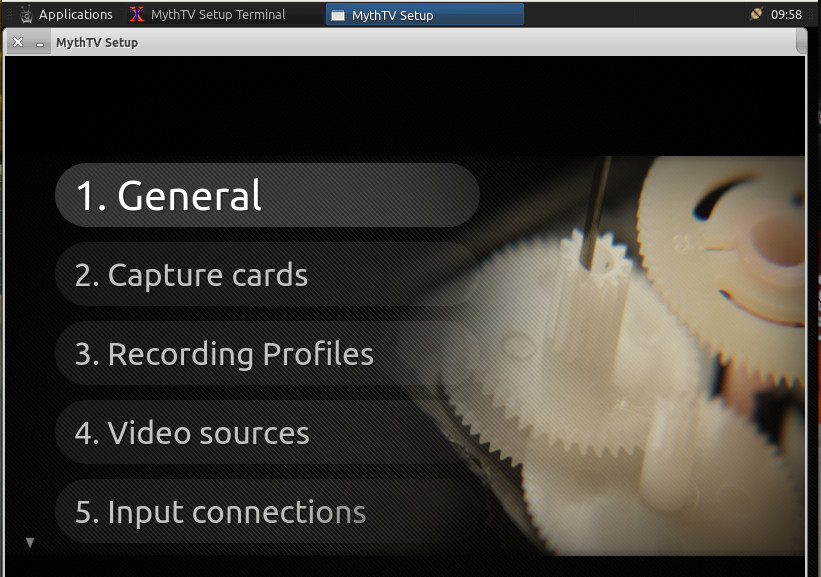
If you do happen to have the hardware (and the desire to create your own Ubuntu-powered entertainment system), Mythbuntu is the distribution you want. Once you’ve installed Mythbuntu, you will then be prompted to walk through the setup of your Capture cards, recording profiles, video sources, and Input connections (Figure 4).
Ubuntu Budgie
Ubuntu Budgie is the new kid on the block to the official flavor list. Sporting the Budgie Desktop, this is a beautiful and modern take on Linux that will please just about any type of user. The goal of Ubuntu Budgie was to create an elegant and simple desktop interface. Mission accomplished. If you’re looking for a beautiful desktop to work on top of the remarkably stable Ubuntu Linux platform, look no further than Ubuntu Budgie.
Adding this particular spin on Ubuntu to the list of official variants was a smart move on the part of Canonical. With Unity going away, they needed a desktop that would offer the elegance found in Unity. Customization of Budgie is very easy, and the list of included software will get you working and browsing immediately.
And, unlike the learning curve many users encountered with Unity, the developers/designers of Ubuntu Budgie have done a remarkable job of keeping this take on Ubuntu familiar. Click on the “start” button to reveal a fairly standard menu of applications. Budgie also includes an easy to use Dock (Figure 5) that holds applications launchers for quick access.
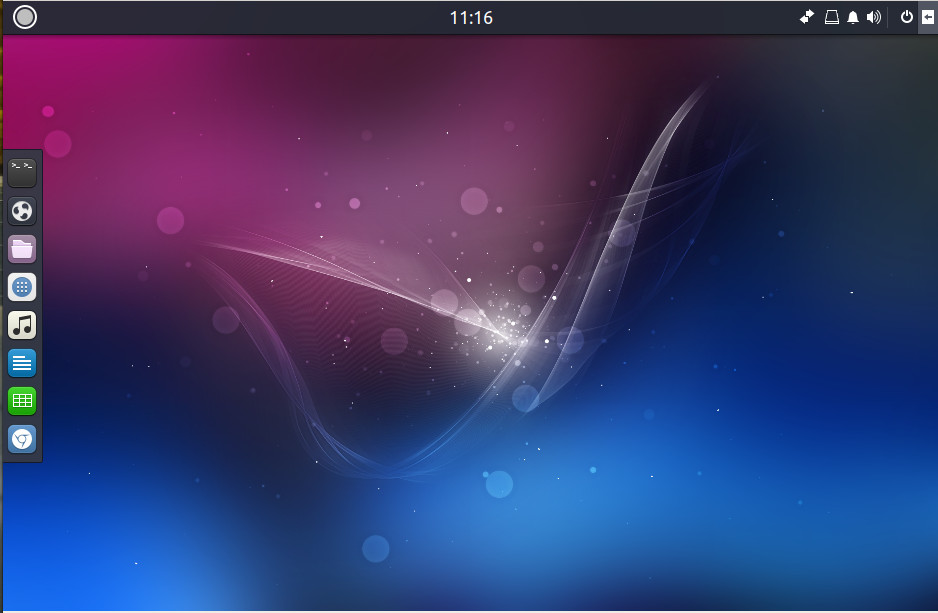
Another really nice feature found in Ubuntu Budgie is a sidebar that can be quickly revealed and hidden. This sidebar holds applets and notifications. With this in play, your desktop can be both incredibly useful, while remaining clutter free.
In the end, if you’re looking for something a bit different, that happens to also be a very modern take on the desktop—with features and functions not found on other distributions—Ubuntu Budgie is what you’re looking for.
Xubuntu
Another official flavor of Ubuntu that does a nice job of providing a small footprint version of Linux is Xubuntu. The difference between Xubuntu and Lubuntu is that, where Lubuntu uses the LXDE desktop, Xubuntu makes use of Xfce. What you get with that difference is a lightweight desktop that is far more configurable (than Lubuntu) as well as one that includes the more business-ready LibreOffice office suite.
Xubuntu is an out of the box experience that anyone, regardless of experience, can use. But don’t think that immediate familiarity means this flavor of Ubuntu is locked out of making it your own. If you’re looking for a take on Ubuntu that’s somewhat old-school out of the box, but can be heavily tweaked to better resemble a more modern desktop, Xubuntu is what you want.
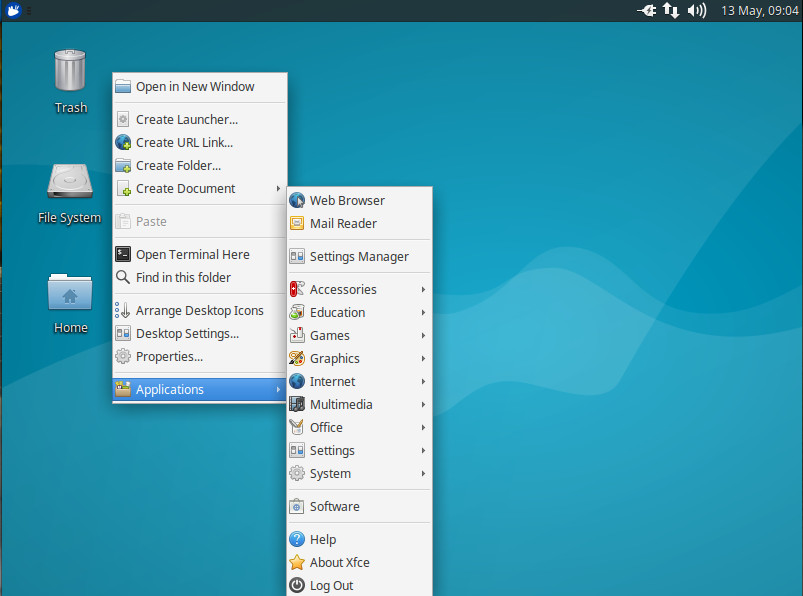
One really handy addition to Xubuntu that I’ve always enjoyed (one that harks back to Enlightenment) is the ability to bring up the “start” menu by right-clicking anywhere on the desktop (Figure 6). This can make for very efficient usage.
The choice is yours
There is a flavor of Ubuntu to meet nearly any need—which one you choose is up to you. As yourself questions such as:
-
What are your needs?
-
What type of desktop do you prefer to interact with?
-
Is your hardware aging?
-
Do you prefer a Windows XP/7 feel?
-
Are you wanting a multimedia system?
Your answers to the above questions will go a long way to determining which flavor of Ubuntu is right for you. The good news is that you can’t really go wrong with any of the available options.
Learn more about Linux through the free “Introduction to Linux” course from The Linux Foundation and edX.





