

The new year is upon us, and it’s time to look toward what the next 365 days have in store. As we are wont to do, Linux.com looks at what might well be the best Linux distributions to be found from the ever-expanding crop of possibilities.
Of course, we cannot just create a list of operating systems and say “these are the best,” not when so often Linux can be very task-oriented. To that end, I’m going to list which distros will rise to the top of their respective heaps…according to task.
With that said, let’s get to the list!
Best distro for sysadmins : Parrot Linux
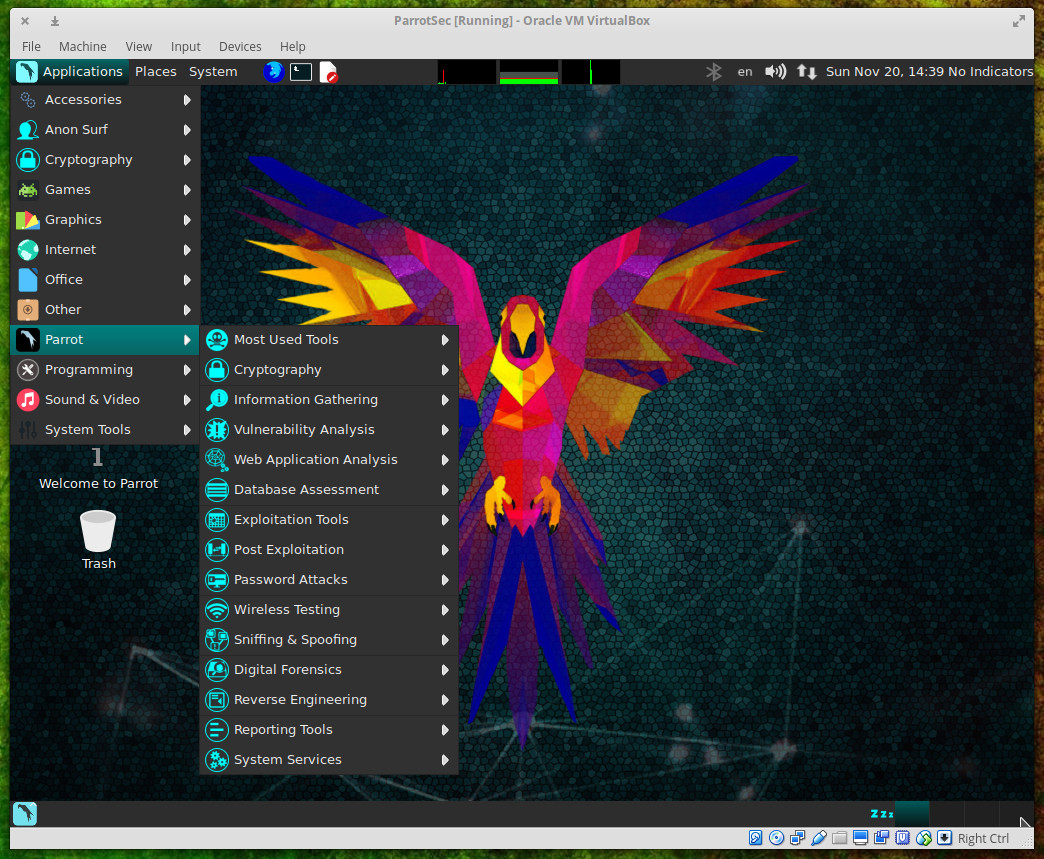
Administrators are tasked with so much on a daily basis. Without a solid toolkit, that job becomes incredibly challenging. For that, there are a host of Linux distributions ready to serve. I believe the one distribution that will find a significant rise in popularity for the coming year will be Parrot Linux. This particular distribution is based on Debian and offers nearly every penetration testing tool you could possibly want. You will also find tools for cryptography, cloud, anonymity, digital forensics, programming, and even productivity. All of these tools (and there are many) are coupled with an already rock-solid foundation to create a Linux distribution perfect for the security and network administrator
Parrot currently stands at #57 on Distrowatch, and I expect to see a significant leap on that list by the end of the year.
Read more about Parrot Linux in Parrot Security Could Be Your Next Security Tool.

Best lightweight distribution: LXLE
Without a doubt, I believe LXLE will become the lightweight distribution of choice in 2017. Why? Simple. LXLE manages to combine a perfect blend of small footprint with large productivity. In other words, this is a small-sized distribution that won’t stop you from getting your work done. You’ll find all the tools you need in a desktop Linux release that will feel right at home on older hardware (as well as newer machines). LXLE is based on Ubuntu 16.04 (so it will enjoy long-term support) and makes use of the LXDE window manager, which brings with it an instant familiarity.
LXLE ships with many of the standard tools (such as LibreOffice and GIMP). The only caveat is the need to install a more modern (and up-to-date browser).
Currently LXLE stands at #16 on Distrowatch. I look for this to break the top 10 by mid 2017. You can read more about LXLE in this article.
Best desktop distribution: Elementary OS
I may be biased, but I’m certain that Elementary OS Loki will do the impossible and usurp Linux Mint from the coveted “best desktop distribution” for 2017. That will be a fairly impressive feat, considering that Linux Mint consistently clobbers the competition on Distrowatch. Currently, Elementary OS stands at #6 (where Linux Mint continues its reign at the number one spot). How is it possible that Elementary OS could de-throne Mint? Loki has not only proved itself to be one of the more beautiful Linux distributions, it is also rock solid and offers an unmatched user-friendliness and consistency across the desktop.
Some might find the Elementary OS desktop to be too “Mac-like.” However, that metaphor has proved incredibly effective with end users and, of course, the Elementary take on the design isn’t nearly as limiting as is the OS X desktop…so feel free to tweak it to your liking.
I’ve covered Elementary OS Loki previously, so you can read more in this article.
Best distribution for those with something to prove: Gentoo
This is a category specific to those who want to show their prowess with the Linux operating system. This is for those who know Linux better than most and want a distribution built specificly to their needs. When this flavor of Linux is desired, there is only one release that comes to mind…Gentoo.
Gentoo is a source-based Linux distribution that starts out as a live instance and requires you to then build everything you need from source. This not only requires a higher level of Linux understanding but also demands more time and patience. In the end, however, you will be rewarded with exactly the distribution you want and nothing more. Gentoo is not new, it’s been around for quite some time; but if you want to prove your Linux skills, it helps to start with Gentoo.

Best Linux for IoT: Snappy Ubuntu Core
Now we’re talking really, really small form factor. The Internet of Things category is where embedded Linux truly shines, and there are a number of distributions ready to take on the task. I believe 2017 will be the year of Snappy Ubuntu Core. Ubuntu Snaps have already made it incredibly easy to install packages without worrying about dependencies and breakage due to upgrades. By leveraging this system, Snappy Core makes for a perfect platform for IoT. Ubuntu Snappy Core can already be found in the likes of various hacker boards (such as the Raspberry Pi) as well as Erle-Copter drones, Dell Edge Gateways, Nextcloud Box, and LimeSDR.
Best non-enterprise server distribution: CentOS
It should come as no surprise here that CentOS remains the Linux darling of the server room for small- and medium-sized businesses. There’s a very good reason CentOS continues to stand at the top of this hill—it’s derived from the Red Hat Enterprise Linux (RHEL) sources. Because of this, you know you are getting as reliable a server platform as you can find. The major difference between Red Hat Enterprise Linux and CentOS (besides the branding) is support. With RHEL, you benefit from official Red Hat support. On the contrary, since 2004, CentOS has enjoyed a massive community-driven support system. So, if your small- or medium-sized business is looking to migrate a data center to an open source platform, your first stop is CentOS.
Best enterprise server distribution: RHEL
Once again, there is no surprise here. SUSE is doing a remarkable job of climbing the enterprise ladder and one of these days they will usurp the reigning king of enterprise Linux from the throne. Unfortunately, 2017 will not be that year. Red Hat Enterprise Linux (RHEL) will continue to top the most wanted list for enterprise businesses. According to Gartner, Red Hat has a 67 percent market share within the realm of Linux (with RHEL subscriptions driving about 75 percent of Red Hat’s revenue). The reasons for this are many. Not only is Red Hat perfectly in tune with what enterprise business needs, they also are major contributors to nearly every software stack within the open source community.
Red Hat knows Linux, and they know enterprise. Red Hat is trusted by numerous Fortune 500 companies (such as ING, Sprint, Bayer Business Services, Atos, Amadeus, and Etrade) and RHEL has managed to push many envelopes far and wide in areas of security, integration, cloud, and management. I also look for Red Hat to focus a good amount of energy on IoT in the coming year. Even still, don’t be surprised if, by the end of 2017, SUSE further chips away at the current Red Hat market share.
The choice is yours
One of the greatest aspects of the Linux platform is that, in the end, the choice is yours. There are hundreds of distributions to choose from, many of which will perfectly meet your needs. However, if you want to give what I believe will be the best in 2017, take one of the above distributions for a spin; I’m certain you won’t be disappointed. Next time, I’ll look at which distros are best designed for new users.



