You may have heard about the concept of custom Operators in Kubernetes. You may have even read about the CoreOS operator-sdk, or tried walking through the setup. The concept is cool: Operators can help you extend Kubernetes functionality to include managing any stateful applications your organization uses. At Kenzan, we see many possibilities for their use on stateful infrastructure apps, including upgrades, node recovery, and resizing a cluster. An ideal future for platform ops will inevitably include operators themselves maintaining stateful applications and keeping runtime intervention by a human to a bare minimum. We also admit the topic of operators and the operator-idk is a tad confusing. After reading a bit, you may secretly still be mystified as to what operators exactly do, and how all the components work together.
In this article, we will demystify what an operator is, and how the CoreOS operator-sdk translates its input to the code that is then run as an operator. In this step-by-step tutorial, we will create a general example of an operator, with a few bells and whistles beyond the functionality shown in the operator-sdk user guide. By the end, you will have a solid foundation for how to build a custom operator that can be applied to real-world use cases.
Hello Operator, could you tell me what an Operator is?
To describe what an operator does, let’s go back to Kubernetes architecture for a bit. Kubernetes is essentially a desired state manager. You give it a desired state for your application (number of instances, disk space, image to use, etc.) and it attempts to maintain that state should anything get out of wack. Kubernetes uses what’s called a control plane on it’s master node. The control plane includes a number of controllers whose job is to reconcile against the desired state in the following way:
-
Monitor existing K8s objects (Pods, Deployments, etc.) to determine their state
-
Compare it to the K8s yaml spec for the object
-
If the state is not the same as the spec, the controller will attempt to remedy this
A common scenario where reconciling takes place is a Pod is defined with three replicas. One goes down, and with K8s’ controller watching, it recognizes that there should be three Pods running, not two. It then works to create a new instance of the Pod.
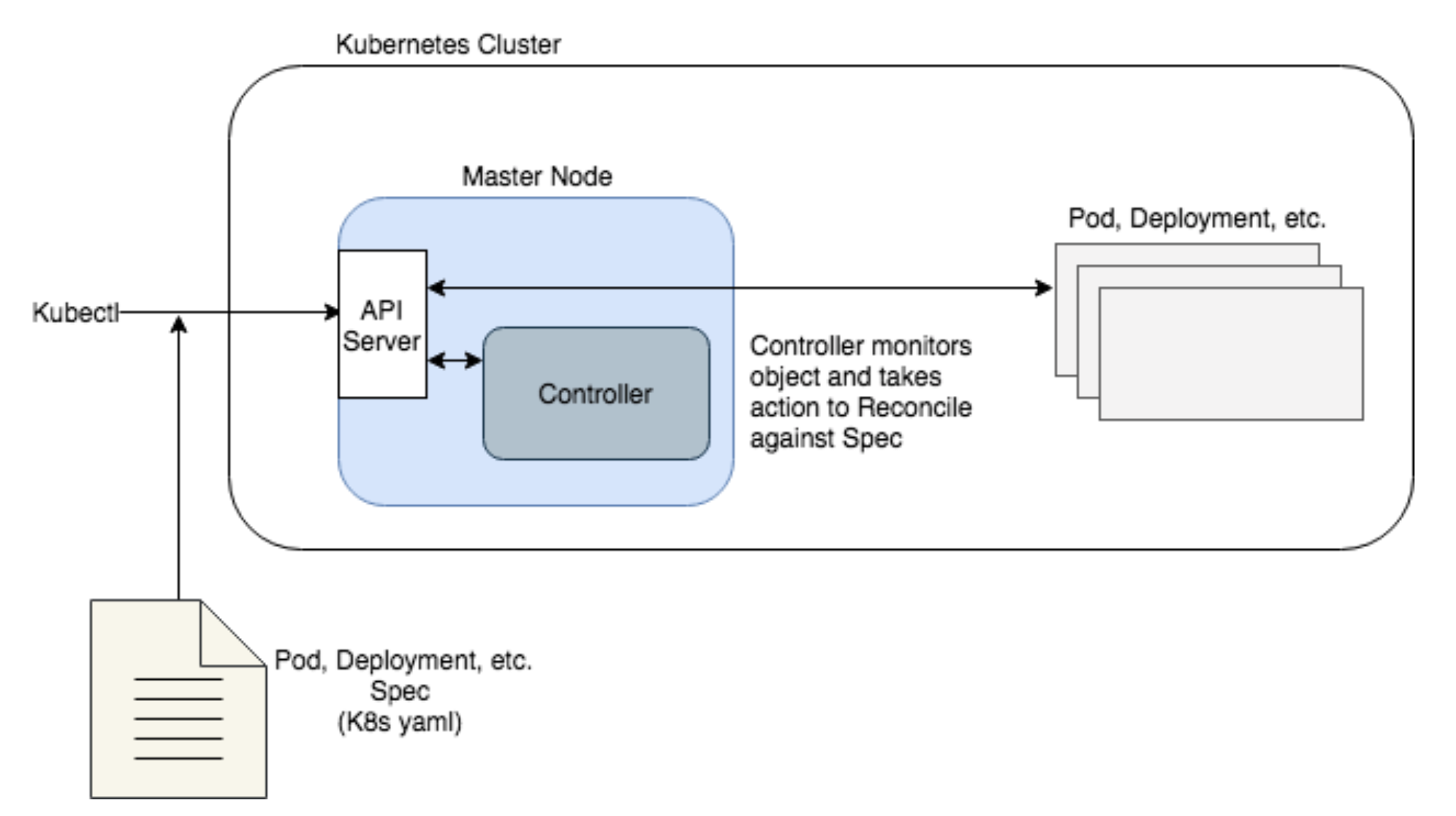
This simplified diagram shows the role of controllers in Kubernetes architecture as follows.
-
The Kubectl CLI sends an object spec (Pod, Deployment, etc.) to the API server on the Master Node to run on the cluster
-
The Master Node will schedule the object to run (not shown)
-
Once running, a Controller will continuously monitor the object and reconcile it against the spec
In this way, Kubernetes works great to take much of the manual work out of maintaining the runtime for stateless applications. Yet it is limited in the number of object types (Pods, Deployments, Namespaces, Services, DaemonSets, etc.) that it will natively maintain. Each of these object types has a predetermined behavior and way of reconciling against their spec should they break, without much deviation in how they are handled.
Now, what if your application has a bit more complexity and you need to perform a custom operation to bring it to a desired running state?
Think of a stateful application. You have a database application running on several nodes. If a majority of nodes go down, you’ll need to reload the database from a specific snapshot following specific steps. Using existing object types and controllers in Kubernetes, this would be impossible to achieve. Or think of scaling nodes up, or upgrading to a new version, or disaster recovery for our stateful application. These kinds of operations often need very specific steps, and typically require manual intervention.
Enter operators.
Operators extend Kubernetes by allowing you to define a Custom Controller to watch your application and perform custom tasks based on its state (a perfect fit to automate maintenance of the stateful application we described above). The application you want to watch is defined in Kubernetes as a new object: a Custom Resource (CR) that has its own yaml spec and object type (in K8s, a kind) that is understood by the API server. That way, you can define any specific criteria in the custom spec to watch out for, and reconcile the instance when it doesn’t match the spec. The way an operator’s controller reconciles against a spec is very similar to native Kubernetes’ controllers, though it is using mostly custom components.
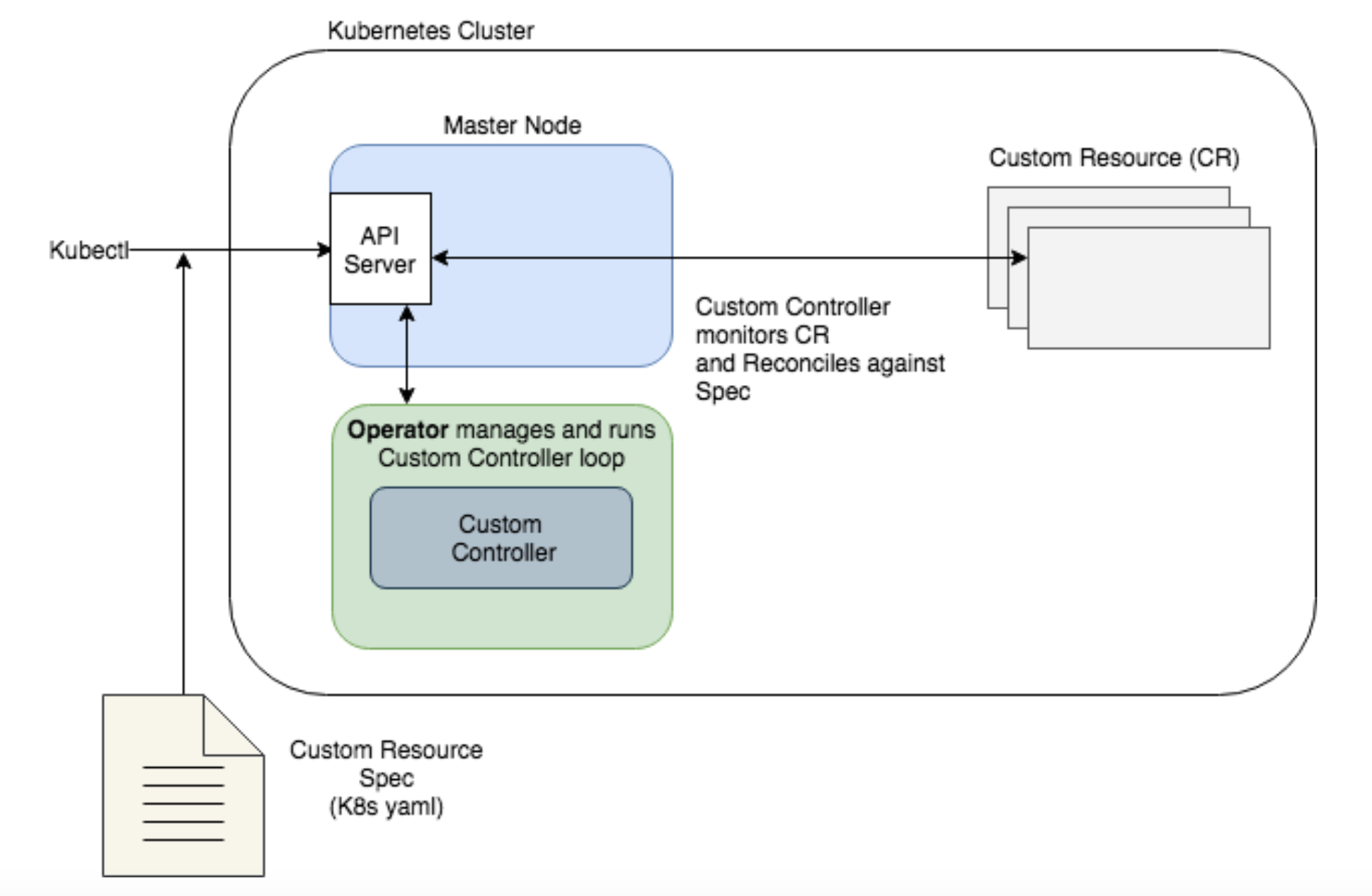
Note the primary difference in our diagram from the previous one is that the Operator is now running the custom controller to reconcile the spec. While the API Server is aware of the custom controller, the Operator runs independently, and can run either inside or outside the cluster.
|
Because Operators are a powerful tool for stateful applications, we are seeing a number of pre-built operators from CoreOS and other contributors for things like ectd, Vault, and Prometheus. And while these are a great starting point, the value of your operator really depends on what you do with it: what your best practice is for failed states, and how the operator functionality may have to work alongside manual intervention. |
Dial it in: Yes, I’d like to try Building an Operator
Based on the above diagram, in order to create our custom Operator, we’ll need the following:
-
A Custom Resource (CR) spec that defines the application we want to watch, as well as an API for the CR
-
A Custom Controller to watch our application
-
Custom code within the new controller that dictates how to reconcile our CR against the spec
-
An Operator to manage the Custom Controller
-
A deployment for the Operator and Custom Resource
All of the above could be created by writing Go code and specs by hand, or using a tool like kubebuilder to generate Kubernetes APIs. But the easiest route (and the method we’ll use here) is generating the boilerplate for these components using the CoreOS operator-sdk. It allows you to generate the skeleton for the spec, the controller, and the operator, all via a convenient CLI. Once generated, you define the custom fields in the spec and write the custom code to reconcile against the spec. We’ll walk through each of these steps in the next part of the tutorial.

Toye Idowu is a Platform Engineer at Kenzan Media.