
Log centralization and analysis are crucial for organizations in troubleshooting system errors, identifying cybersecurity threats, and adhering to various regulations such as The Health Insurance Portability and Accountability Act (HIPAA), Gramm-Leach-Bliley Act (GLBA), Payment Card Industry Data Security Standards (PCI), Cybersecurity Maturity Model Certification (CMMC), and more. While contemporary SIEM solutions have simplified log management, features like threat intelligence and advanced event correlation are often restricted to paid, closed-code systems. This article will walk you through deploying log collectors, a comprehensive log management solution, and correlation rules using UTMStack, an open source and free SIEM and XDR solution, for effective threat detection, system error identification, and automated remediation.
Technology and Architecture Overview
Deploying UTMStack for log centralization and analysis involves three main components: log collectors aka agents, a central server for log centralization, and correlation rules for detection and incident response.
Agents: These collect logs from systems and execute local and remote incident response commands. Agents can also function as proxies for collecting syslog and netflow logs from network devices.
Central Server: This server stores and correlates logs from various assets like other servers and firewalls to identify potential threats and orchestrates incident responses across the IT ecosystem.
Correlation rules and Incident Response: These detect possible threats to system security and availability by correlating logs from multiple systems with threat intelligence and predefined malicious sequences of behaviors and compromise indicators. Once a correlation rule evaluates a group of logs as potentially malicious, an alert triggers the incident response command.
Deploying the Open Source Security Stack
Log Centralization Server
The log centralization server can be deployed using an ISO image from the utmstack website for simplicity. For advanced installation options, please visit the official GitHub repository https://github.com/utmstack/UTMStack
Here are the instructions for installing without the ISO on Ubuntu Linux 22.04 LTS.

After installation, access the server via a browser using the server’s IP address or DNS name and the random secure password provided by the installer.
Deploying Log Collectors
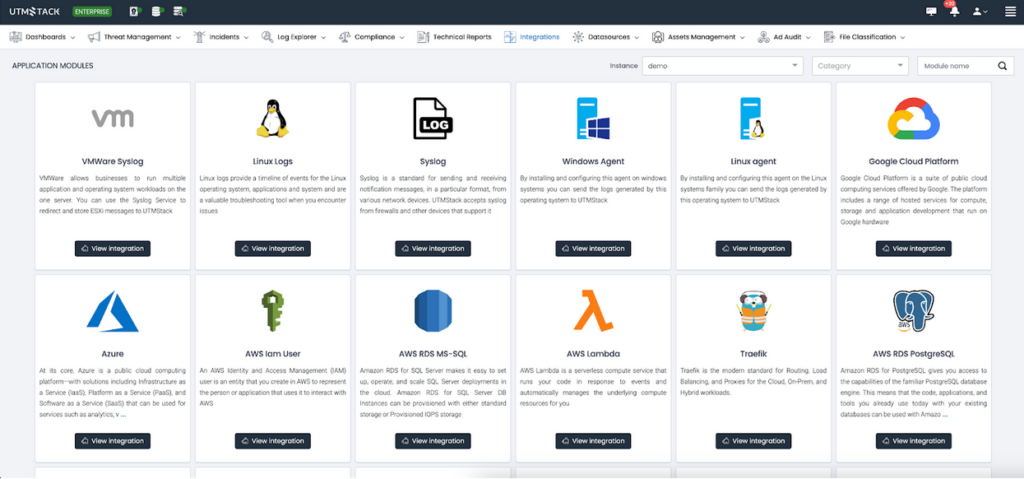
Navigate to the “Integrations” section and select the appropriate agent for your operating system. Additional integrations can be configured as needed.
Defining Correlation Rules and Incident Response
Correlation rules form the core of a log management system, defining which logs or combinations thereof should trigger an alert or incident. UTMStack uses these rules as a basis for Incident Response playbooks.
Let’s take, for instance, a brute-force attack. This type of cybersecurity threat attempts to guess a user’s password by trying massive random combinations of characters until the correct sequence matches the user’s credentials. These types of attacks usually leave behind a trail of logs that indicate a user has failed to log into a system several times in a short period of time.
You can access the complete list of prebuilt correlation rules and the guide to creating new ones from the official UTMStack repository. For this guide, we’ll create a sample correlation rule to detect brute-force attacks.
UTMStack correlation rules are written in plain YAML and have three main components. Threat documentation that describes the rule, defines a tactic category of attack, severity and name of the rule. The second component is the logic and frequency block, where the rules for triggering this alert are defined. Finally, the alert information block, where the information is extracted from the logs and saved into the alert item.
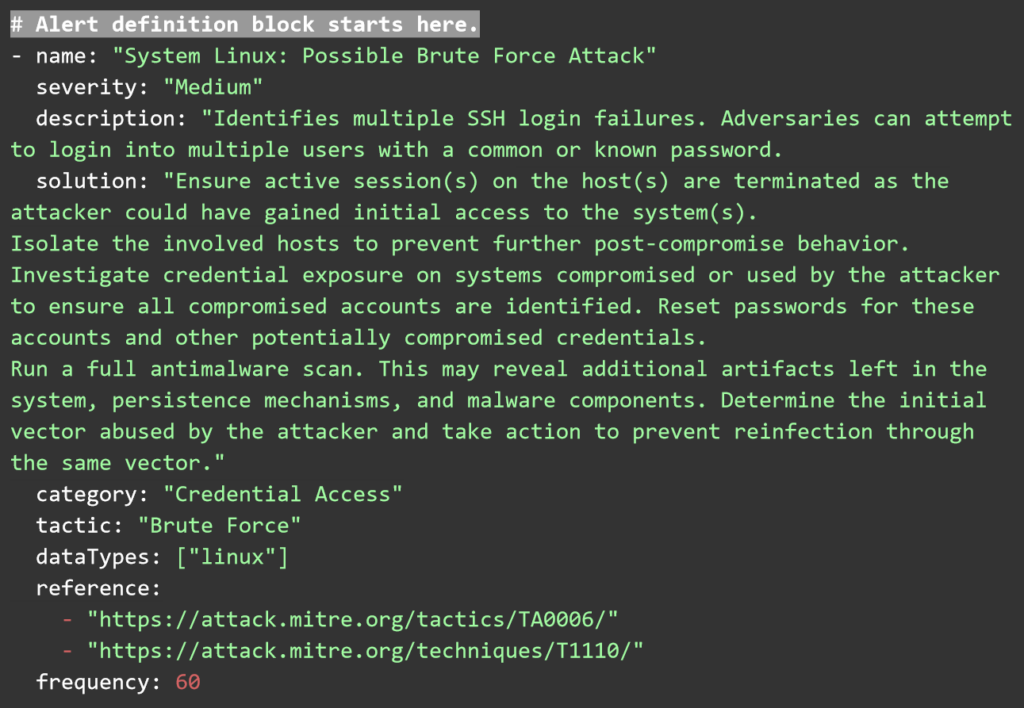
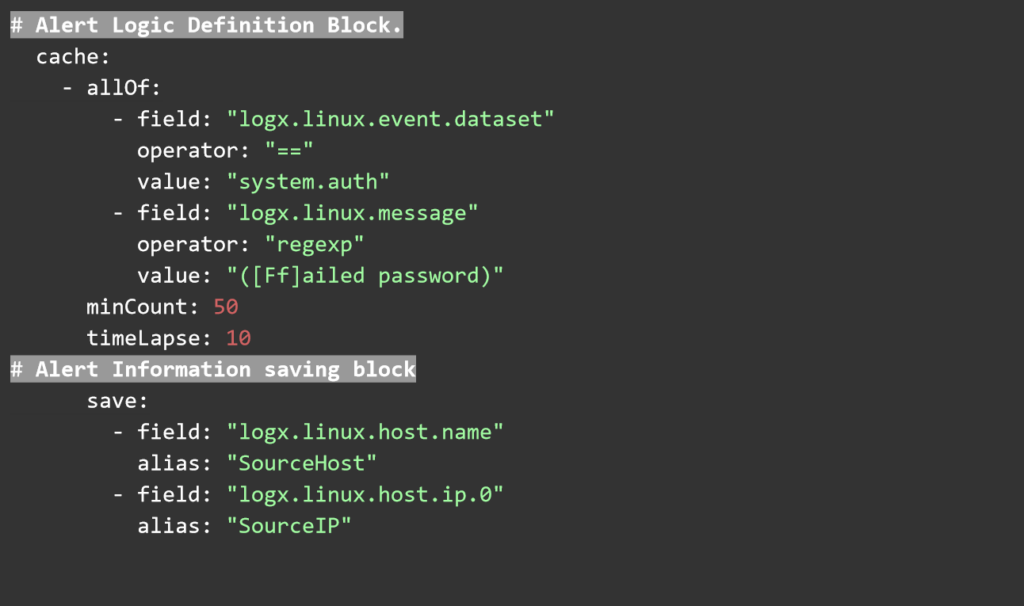
These YAML rules can be saved as text files and copied into the correlation rules folder via the Web User interface. Any rules uploaded there will be processed by the correlation engine automatically.
All logs the system receives are aggregated and correlated for indicators of compromise (IOCs) using several open threat intelligence feeds. This feature is enabled by default, and there is no need for custom correlation rules or configurations.
Finally, to deploy the incident response playbooks, navigate to the incident response automation section and drop a command to disable future login attempts from the offender host. This can be done by blocking its IP in the firewall or disabling the victim user until further investigation can be done.
UTMStack’s Incident response commands use dynamic variables to handle the execution of commands with different targets. Here are some examples.
Command to block a user:usermod -L ${source.user}
Command to block an IPiptables -A INPUT -s ${source.ip} -j DROP
Summary
Log centralization and analysis are essential for security, availability, and compliance. Open source tools can deliver advanced flexibility and rich feature sets to meet complex use cases and deliver an enterprise-ready experience. The UTMStack open source project is a powerful SIEM and XDR system that can deliver log management, threat detection and incident response by correlating and aggregating logs in real-time. Advanced features such as IOC detection, threat intelligence, and compliance are built-in features of the security stack.
Join Our Community and Contribute
We’re always looking for passionate individuals to contribute to our project. Whether you’re a developer, security expert, or just enthusiastic about cybersecurity, your input is valuable. Here’s how you can get involved:
GitHub Repository: Visit our GitHub repository to explore our code, submit issues, or contribute enhancements. Your code contributions can help us improve and expand UTMStack’s capabilities.
Discord Channel: Join our Discord community to discuss with fellow contributors, share ideas, and collaborate on projects. It’s a great place to learn from others and contribute your expertise.
Online Chat and Forums: For quick questions or discussions, use the online chat feature on our official website or the forums. It’s a direct line to our team and community for real-time interactions.
Your contributions, big or small, play a crucial part in the development and improvement of UTMStack. Together, we can build a stronger, more secure open-source SIEM & XDR solution. Join us today and help shape the future of cybersecurity!
Author

Rick Valdes
Founder, UTMStack





