

One of the many great aspects of the Linux operating system is its ability to bring new life to old hardware. This is not only a boon for your bottom line but also an environmentally sound philosophy. Instead of sending that older (still functioning) hardware to the trash heap, give it a second lease on life with the help of Linux. You certainly won’t be doing that with Windows 7, 8, or 10. Linux, on the other hand, offers a good number of options for those wanting to extend the life of their aging machines.
And don’t think these distributions aimed at outdated hardware are short on features. Remember, when that hardware was in its prime, it was capable of running everything you needed. Even though times have changed (and software demands far more power from the supporting hardware), you can still get a full-featured experience from a lightweight distro.
Let’s take a look at four distributions that will make your aging machines relevant again.
Linux Lite
If you’re looking for a distribution that is fully functional, out of the box, Linux Lite might be your ticket. Not only is Linux Lite an ideal distribution for aging hardware, it’s also one of the best distributions for new users. Linux Lite is built upon the latest Ubuntu LTS release and achieves something few other distributions in this category can — it manages to deliver all the tools you need to get your work done. This isn’t a distro that substitutes AbiWord and Gnumeric for LibreOffice (not that there’s anything wrong with those pieces of software).
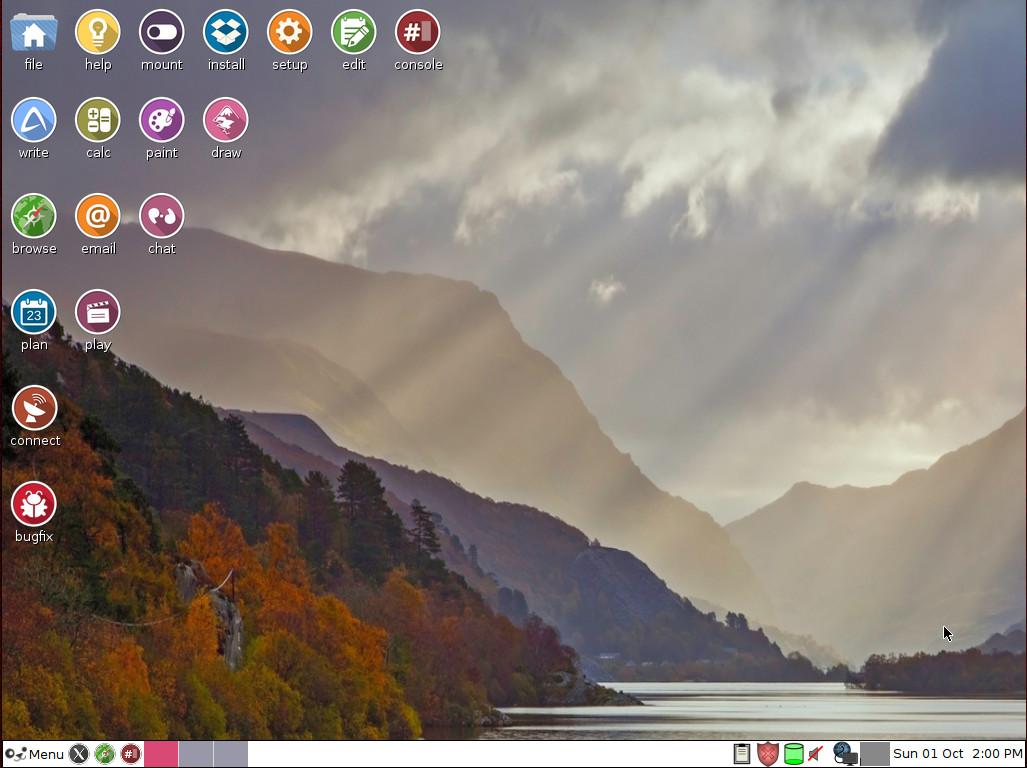
Linux Lite depends upon the Xfce Desktop Environment (Figure 1) and includes the likes of LibreOffice, Firefox, Thunderbird, VLC, GIMP, GNOME Disks, and much more. With the use of Xfce and the inclusion of a full complement of software, Linux Lite makes for an outstanding distribution for new users, working with old hardware. That’s a serious win-win for businesses who want to save costs by distributing old hardware to temp employees and homes who want to hand down hardware to younger members of the family.

Don’t let the “Lite” moniker full you; this isn’t some stripped-down operating system. Linux Lite is a full-fledged distribution that just so happens to run well on lesser-powered machines.
The minimum system requirements for Linux Lite are:
-
700MHz processor
-
512mb RAM
-
VGA screen 1024×768 resolution
-
DVD drive or USB port (in order to install from the ISO image)
-
At least 5 GB free disk space
Bodhi Linux
Bodhi Linux has always held a special place in my heart. As the Enlightenment desktop was one of the first to pull me away from my beloved AfterStep, it was a breath of fresh air that a distribution was dedicated to keeping that particular desktop relevant. And what a masterful job the developers of Bodhi Linux have done.
Although the Enlightenment desktop isn’t exactly one that will have new users crying to the heavens, “Where have you been all my life?”, it is certainly a fan-favorite for many an old-school Linux user. But don’t think new users will have nothing but trouble with Enlightenment. For standard usage, it’s fairly straightforward. It’s when you want to begin customizing the desktop that you might encounter complexity. But if new users can get into the Enlightenment groove, they will find one of the most flexible desktops available.
Like Linux Lite, Bodhi is built upon the latest Ubuntu LTS release, but makes use of the Moksha Desktop (Figure 2) as its user interface. Moksha is a continuation of the Enlightenment E17 desktop and the Bodhi developers have done an outstanding job of bringing Enlightenment into the modern day (while retaining that which makes Enlightenment special).

The one caveat to Bodhi (besides the learning curve of Moksha) is that, out of the box, it doesn’t include much in the way of user-facing applications. You will find the Midori browser, ePad text editor, ePhoto image viewer, and not much more. Fortunately, Bodhi includes its own app store, called Appcenter, where users can easily install any number of software titles.
The minimum system requirements for Bodhi are:
-
500mhz processor
-
256MB of RAM
-
4GB of drive space
The recommended requirements are:
-
1.0ghz processor
-
512MB of RAM
-
10GB of drive space
Puppy Linux
No list of lightweight Linux distributions would be complete without Puppy Linux. Puppy is unique in that it isn’t a single Linux distribution, but a collection of distributions that share the same guiding principles and built with the same tool (Woof-CE). There are three categories of Puppy Linux:
-
The official Puppy Linux distributions. These are maintained by the Puppy Linux team and are targeted for general purpose.
-
The woof-built Puppy Linux distributions. These are developed to suit specific needs and appearances (while also targeting general purpose).
-
The unofficial derivatives (aka “puplets”). These are remasters, made and maintained by Puppy Linux enthusiasts, that target specific purposes.
Instead of a distribution based only on Ubuntu, Puppy offers releases based on Ubuntu and Slackware.
As you might expect, the tools offered on the Puppy Linux desktop (Figure 3) lean toward the minimal side of things (AbiWord, Gnumeric, mtPaint, Slypheed, Palemoon, etc.). Considering the size of the Puppy Linux ISO comes in at 224 MB, that is understandable. Along with this minimalist take on Linux, Puppy Linux is one of the best at making older hardware feel new again. Puppy Can work with a 333Mhz processor and 256MB of RAM and make it run smooth and fast.
According to the Puppy Linux developers, Puppy is “grandpa-friendly certified.”
Lubuntu
If you’re looking for a Ubuntu respin that will give life to that aging PC, Lubuntu is a winner. Lubuntu is part of the Ubuntu family and makes use of the LXDE desktop (Figure 4). This aging PC-friendly distribution includes a selection of lite applications that won’t ever bog down your machine. Like Puppy Linux, Lubuntu is incredibly easy to use and opts for slimmer applications (such as Abiword and Gnumeric). Lubuntu also includes Firefox (for web browsing) as well as Audacious and GNOME-Mplayer for multimedia playback.
Lubuntu is a lightweight distribution, but not nearly as lightweight as, say, Puppy Linux. Lubuntu can work on computers up to around ten years old. The minimum requirements for this particular desktop Linux are:
-
CPU: Pentium 4 or Pentium M or AMD K8
-
For local applications, Lubuntu can function with 512MB of RAM. For online usage (Youtube, Google+, Google Drive, and Facebook), 1GB of RAM is recommended.
Lubuntu also includes the Synaptic package manager; so if those base applications aren’t enough, you can always install whatever you need. New users will greatly appreciate the simplicity of the desktop.
There is next to zero learning curve involved with LXDE. Combine the ease of LXDE and the inclusion of the lightweight apps, you cannot go wrong with Lubuntu. If you’re concerned you will miss out (using the likes of Abiword), some of these tools are capable of working with more standard formats. Take, for instance, Abiword — this tool can save as .doc, .rtf, .txt, .epub, .pdf, .odt, and more. What’s best about the included apps is that they are lightning fast and reliable. The default software list, included with Lubuntu, offers quite a bit more than your average lightweight Linux distribution. You’ll find:
-
Xfburn
-
Mpv Media Player
-
guvcview
-
Audacious
-
GNOME Mplayer
-
PulseAudio Volume Control
-
AbiWord
-
Gnumeric
-
Firefox
-
Pidgin
-
Sylpheed
-
Transmission
-
Document Viewer
-
mtPaint
-
Simple Scan
-
GNOME Disks
-
PCManFM
-
Leafpad
-
Xpad
If you’re looking for an official Ubuntu flavor, that can breath life into that old hardware, Lubuntu is a great call.
The choice is yours
There are quite a number of other lightweight Linux distributions, but the four I’ve listed here offer the most variety, reliability, and capability, all the while performing like champs on older hardware. Give one of these a shot and see if those old desktops can’t be given new life without too much work.
Learn more about Linux through the free “Introduction to Linux” course from The Linux Foundation and edX.





