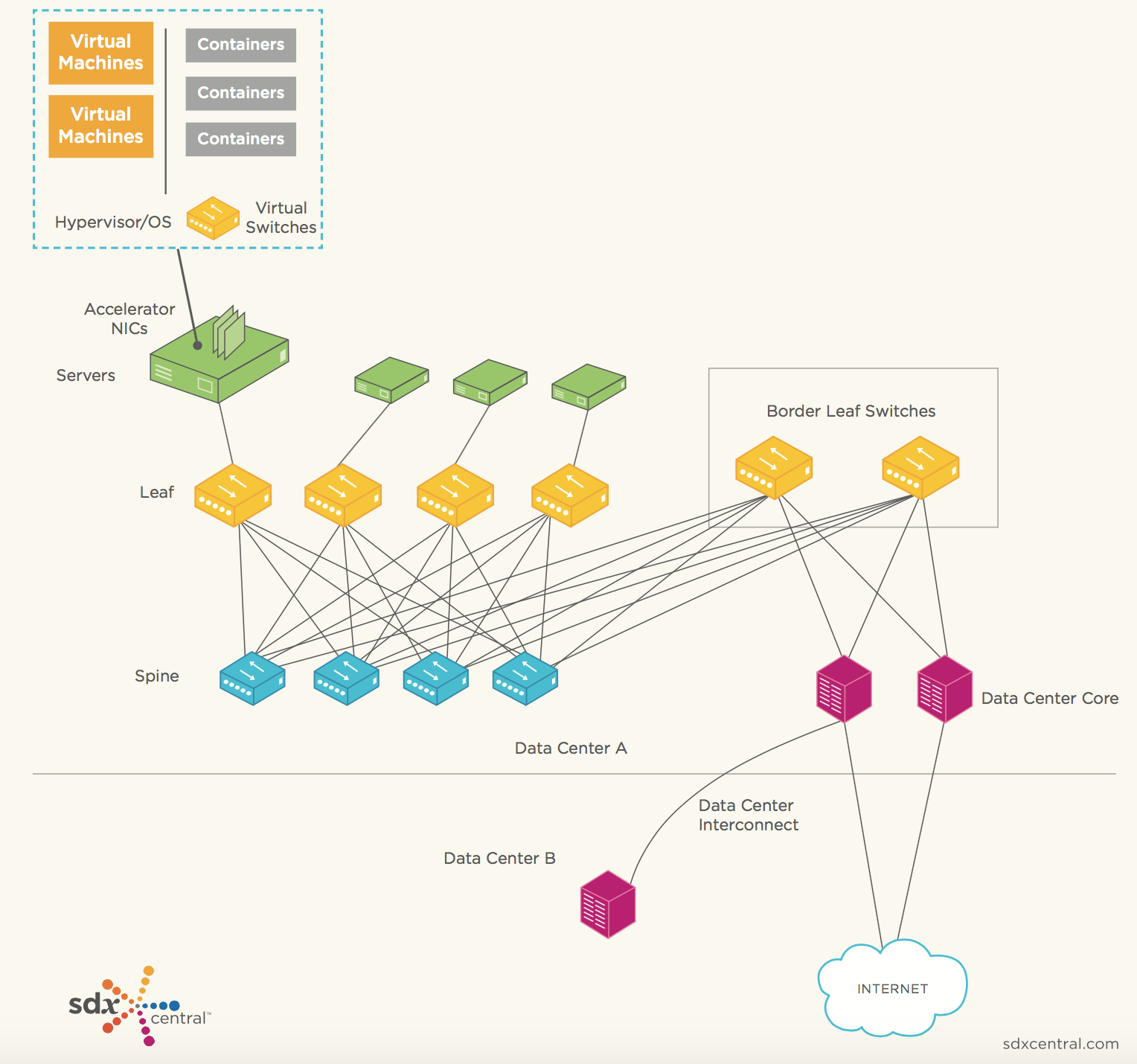
This article will describe how to set up a monitoring system for your server using the ELK (Elasticsearch, Logstash and Kibana) Stack. The OS used for this tutorial is an AWS Ubuntu 16.04 AMI, but the same steps can easily be applied to other Linux distros.
There are various daemons that can be used for tracking and monitoring system metrics, such as StatsD or collectd, but the process outlined here uses Metricbeat, a lightweight metric shipper by Elastic, to ship data into Elasticsearch. Once indexed, the data can be then easily analyzed in Kibana.
As it’s name implies, Metricbeat collects a variety of metrics from your server (i.e. operating system and services) and ships them to an output destination of your choice. These destinations can be ELK components such as Elasticsearch or Logstash, or other data processing platforms such as Redis or Kafka.
Installing the stack
We’ll start by installing the components we’re going to use to construct the logging pipeline — Elasticsearch to store and index the data, Metricbeat to collect and forward the server metrics, and Kibana to analyze them.
Installing Java
First, to set up Elastic Stack 5.x, we need Java 8:
sudo apt-get update
sudo apt-get install default-jre
You can verify using this command:
$ java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build 1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)
Installing Elasticsearch and Kibana
Next up, we’re going to dDownload and install the public signing key for Elasticsearch:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Save the repository definition to ‘/etc/apt/sources.list.d/elastic-5.x.list’:
echo "deb https://artifacts.elastic.co/packages/5.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-5.x.list
Update the system, and install Elasticsearch:
sudo apt-get update && sudo apt-get install elasticsearch
Run Elasticsearch using:
s
You can make sure Elasticsearch is running using:
curl localhost:9200
The output should look something like this:
{
"name" : "OmQl9JZ",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "aXA9mmLQS9SPMKWPDJRi3A",
"version" : {
"number" : "5.2.2",
"build_hash" : "f9d9b74",
"build_date" : "2017-02-24T17:26:45.835Z",
"build_snapshot" : false,
"lucene_version" : "6.4.1"
},
"tagline" : "You Know, for Search"
}
Next up, we’re going to install Kibana with:
sudo apt-get install kibana
To verify Kibana is connected properly to Elasticsearch, open up the Kibana configuration file at: /etc/kibana/kibana.yml, and make sure you have the following configuration defined:
server.port: 5601
elasticsearch.url: "http://localhost:9200"
And, start Kibana with:
sudo service kibana start
Installing Metricbeat
Our final installation step is installing Metricbeat:
sudo apt-get update && sudo apt-get install metricbeat
Configuring the pipeline
Now that we’ve got all the components in place, it’s time to build the pipeline. Our next step involves configuring Metricbeat — defining what data to collect and where to ship it to.
Open the configuration file at /etc/metricbeat/metricbeat.yml
In the Modules configuration section, you define which system metrics and which service you want to track. Each module collects various metricsets from different services (e.g. Apache, MySQL). These modules, and their corresponding metricsets, need to be defined separately. Take a look at the supported modules here.
By default, Metricbeat is configured to use the system module which collects server metrics, such as CPU and memory usage, network IO stats, and so on.
In my case, I’m going to uncomment some of the metrics commented out in the system module, and add the apache module for tracking my web server.
At the end, the configuration of this section looks as follows:
- module: system
metricsets:
- cpu
- load
- core
- diskio
- filesystem
- fsstat
- memory
- network
- process
enabled: true
period: 10s
processes: ['.*']
- module: apache
metricsets: ["status"]
enabled: true
period: 1s
hosts: ["http://127.0.0.1"]
Next, you’ll need to configure the output, or in other words where you’d like to send all the data.
Since I’m using a locally installed Elasticsearch, the default configurations will do me just fine. If you’re using a remotely installed Elasticsearch, make sure you update the IP address and port.
output.elasticsearch:
hosts: ["localhost:9200"]
If you’d like to output to another destination, that’s fine. You can ship to multiple destinations or comment out the Elasticsearch output configuration to add an alternative output. One such option is Logstash, which can be used to execute additional manipulations on the data and as a buffering layer in front of Elasticsearch.
Once done, start Metricbeat with:
sudo service metricbeat start
One way to verify all is running as expected is to query Elasticsearch for created indices:
curl http://localhost:9200/_cat/indices?v
You should see a list of indices, one being for metricbeat.
Analyzing the data in Kibana
Our last and final step is to understand how to analyze and visualize the data to be able to extract some insight from the logged metrics.
To do this, we first need to define a new index pattern for the Metricbeat data.
In Kibana (http://localhost:5601), open the Management page and define the Metricbeat index in the Index Patterns tab (if this is the first time you’re analyzing data to Kibana, this page will be displayed by default):

Select @timestamp as the time-field name and create the new index pattern.
Opening the Discover page, you should see all the Metricbeat data being collected and indexed.

If you recall, we are monitoring two types of metrics: system metrics and Apache metrics. To be able to differentiate the two streams of data, a good place to start is by adding some fields to the logging display area.
Start by adding the ‘metricset.module’ and ‘metricset.name’ fields.

Visualizing the data
Kibana is notorious for its visualization capabilities. As a simple example, let’s create a simple visualization that displays CPU usage over time.
To do this, open the Visualize page and select the area chart visualization type.
We’re going to compare, over time, the user and kernel space. Here is the configuration and the end-result:

Another simple example is a look at how our CPU is performing over time. To do this, we will pick the line chart visualization this time and use an average aggregation of the ‘system.process.cpu.total.pct’ field.

Or, you can set up a series of metric visualizations to show single stats on critical system metrics, such as the one below showing the amount of free memory.

You’ll need to edit the field in the Management page to have the metric display the correct measuring units.
Once you have a series of these visualizations built up, you can combine them all into a nice monitoring dashboard. Side note – if you’re using the Logz.io ELK Stack, you’ll find a Metricbeat dashboard ELK Apps, a library of free pre-made visualizations and dashboards for different data types.
Summing it up
In just a few steps you can have a good comprehensive picture of how well your system is performing. Starting from memory consumption, through to CPU usage and network packets — ELK is a very useful stack to have pn your side, and Metricbeat is a sueful tool to use if its server metric monitoring you’re after.
I highly recommend setting up a local dev environment to test this configuration, and compare it with the other metric reporting tools.