

The following is adapted from Open Source Compliance in the Enterprise by Ibrahim Haddad, PhD.
A successful open source management program has seven essential elements that provide a structure around all aspects of open source software. In the previous article, we gave an overview of the strategy and process behind open source management. This time we’ll discuss two more essential elements: staffing on the open source compliance team and the tools they use to automate and audit open source code.
Compliance Teams
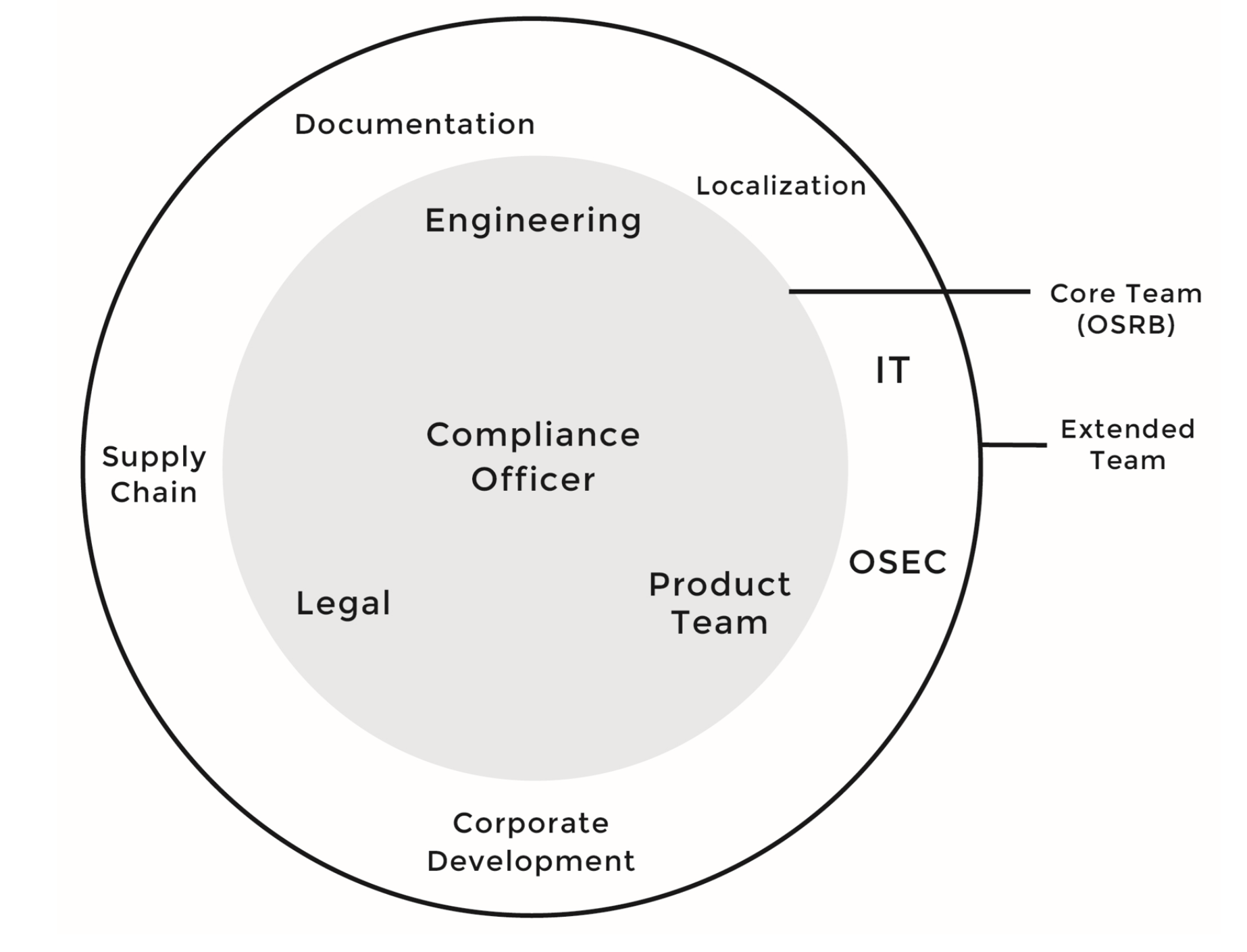
The open source compliance team is a cross-disciplinary group consisting of various individuals tasked with the mission of ensuring open source compliance. There are actually a pair of teams involved in achieving compliance: the core team and the extended team.
-
The core team, often called the Open Source Review Board (OSRB), consists of representatives from engineering and product teams, one or more legal counsel, and the Compliance Officer.
-
The extended team consists of various individuals across multiple departments that contribute on an ongoing basis to the compliance efforts: Documentation, Supply Chain, Corporate Development, IT, Localization and the Open Source Executive Committee (OSEC). However, unlike the core team, members of the extended team are only working on compliance on a part-time basis, based on tasks they receive from the OSRB.
Tools
Open source compliance teams use several tools to automate and facilitate the auditing of source code and the discovery of open source code and its licenses. Such tools include:
• A compliance project management tool to manage the compliance project and track tasks and resources.
• A software inventory tool to keep track of every single software component, version, and product that uses it, and other related information.
• A source code and license identification tool to help identify the origin and license of the source code included in the build system.
• A linkage analysis tool to identify the interactions of any given C/C++ software component with other software components used in the product. This tool will allow you to discover linkages between source code packages that do not conform to company policy. The goal is to determine if any open source obligations extend to proprietary or third party software components. If a linkage issue is found, a bug ticket is assigned to Engineering with a description of the issue in addition to a proposal on how to solve the issue.
• A source code peer review tool to review the changes introduced to the original source code before disclosure as part of meeting license obligations.
• A bill of material (BOM) difference tool to identify the changes introduced to the BOM of any given product given two different builds. This tool is very helpful in guiding incremental compliance efforts.
Next time we’ll cover another key element of any open source management program: education. Employees must possess a good understanding of policies governing the use of open source software. Open source compliance training — formal or informal — raises awareness of open source policies and strategies and builds a common understanding within the organization.

Read the previous article in this series:
The 7 Elements of an Open Source Management Program: Strategy and Process
Read the next articles in this series:
How and Why to do Open Source Compliance Training at Your Company
Basic Rules to Streamline Open Source Compliance For Software Development


