
The Node.js project has three major updates this month:
- Node.js v7 will become a current release line.
- Node.js v6, code named “Boron,” transitions to LTS.
- Node.js v0.10 will reach “End of Life” at the end of the month. There will be no further releases of this line, including security or stability patches.
Node.js v6 transitioned to LTS line today, so let’s talk about what this means, where other versions stand, and what to expect with Node.js v7.
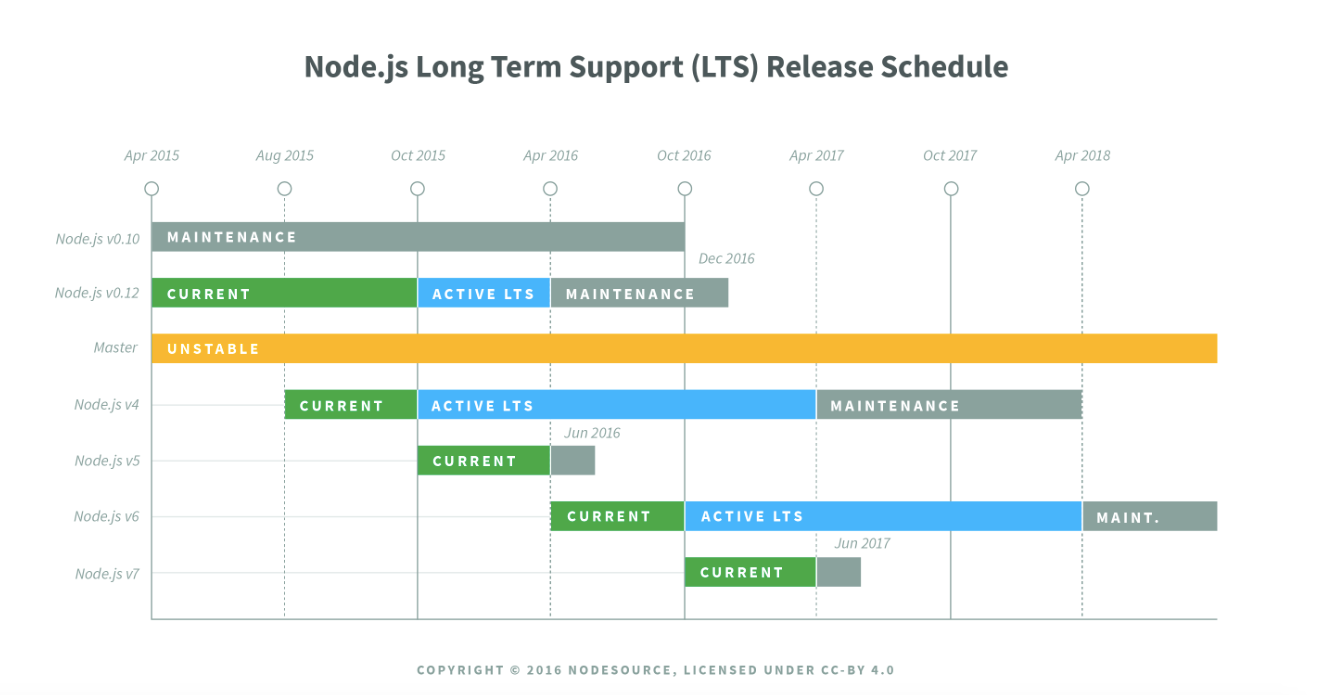
Node.js Project’s LTS Strategy
In a nutshell, the Long Term Support (LTS) strategy is focused on creating stability and security to organizations with complex environments that find it cumbersome to continually upgrade Node.js. These release lines are even numbered and are supported for 30 months — more information on the LTS strategy can be found here.
*This image is under copyright of NodeSource.
Another good source for the history and strategy of the Node.js release lines, can be found in Rod Vagg’s blog post, “Farewell to Node.js v5, Preparing for Node.js v7.” Rod is the Node.js Project’s technical steering committee director and a Node.js Foundation board member.
Node.js follows semantic versioning (semver). Essentially, semver is how we signal how changes will affect the software, and whether or not upgrading will “break” software to help developers determine whether they should download a new version, and when they should download a new version. There is a simple set of rules and requirements that dictate how version numbers are assigned and incremented, and whether they fall into the following categories:
- Patch Release: Is a bug fix or a small improvement to performance. It doesn’t add new features or change the way the software works. Patches are an easy upgrade.
- Minor Release: This is any change to the software that introduces new features, but does not change the way that the software works. Given that there is a new feature being release, it is generally best to wait to upgrade to a minor release after it has been tested and patched.
- Major Release: This is a big breaking change. It changes how the software works and functions. With Node.js, it can be as simple as changing an error message to upgrading V8.
If you want more information on how releases work, watch Myles Borins’ presentation at JSConf Uruguay: https://www.youtube.com/watch?v=5un1I2qkojg. Myles is a member of the Node.js Project and Node.js Core Technical Committee.
Node.js v6 Moves from “Current” to “LTS”
Node.js v6 will be the LTS release line until April 2018, meaning new features (semver-minor) may only land with consent of the Node.js project’s Core Technical Committee and the LTS Working Group. These features will land on an infrequent basis.
Changes in a LTS-covered major version are limited to:
- Bug fixes;
- Security updates;
- Non-semver-major npm updates;
- Relevant documentation updates;
- Certain performance improvements where the risk of breaking existing applications is minimal;
- Changes that introduce a large amount of code churn where the risk of breaking existing applications is low and where the change in question may significantly ease the ability to backport future changes due to the reduction in diff noise.
After April 2018, Node.js v6 will transition into “maintenance” mode for 12 additional months. Maintenance mode means that only critical bugs, critical security fixes, and documentation updates will be permitted.
Node.js v6 is important to enterprises and users that need stability. If you have a large production environment and need to keep Node.js humming, then you want to be on an LTS release line. If you fall within this category, we suggest that you update to Node.js v6, especially if you are on v0.10 or v0.12. *More information on this as well as what to do if you are on Node.js v4 below.
Features, Focus and More Features
Node.js v6 became a current release line in April 2016. Its main focus is on performance improvements, increased reliability and better security. A few notable features and updates include:
Security Enhancements
- New Buffer API creation for increased safety and security.
- Experimental support for the “v8_inspector,” a new experimental debugging protocol. *If you have an environment that cannot handle updates or testing, do not try this new feature as it is not fully supported and could have bugs.
Increased Reliability
- Print warning to standard error when a native Promise rejection occurs, but there is no handler to receive it. This is particularly important for distributed teams building applications. Before this capability, they would have to chase down the problem, which is equivalent to finding a needle in a haystack. Now, they can easily pinpoint where the problem is and solve it.
Performance Improvements
- Support of V8 JavaScript engine 5.1, which includes default function parameters, destructuring, and rest parameters to name a few. You can view the full list of features here. Ninety-seven percent of ES6 featuresare now supported by Node.js v6.
Node.js v6 Equipped with npm v3
- Npm3 resolves dependencies differently than npm2 in that it tries to mitigate the deep trees and redundancy that nesting causes in npm2 — more on this can be found in npm’s blog post on the subject. The flattened dependency tree will be very important in particular to Windows users who have file path length limitations.
- In addition, npm’s shrinkwrap functionality has changed. The updates will provide a more consistent way to stay in sync with package.json when you use the save flag or adjust dependencies. Users who deploy projects using shrinkwrap consistently (most enterprises do) should watch for changes in behaviour.
Updating Node.js v4 to Node.js v6
If you are on Node.js v4, you have 18 months to transition from Node.js v4 to Node.js v6. We suggest starting now. Node.js v4 will stop being maintained April 2018.
At the current rate of download, Node.js v6 will take over the current LTS line v4 in downloads by the end of the year. This is a good thing as v6 will be the LTS line and in maintenance mode for the next 30 months. Node.js v4 will stop being maintained in April 2018.
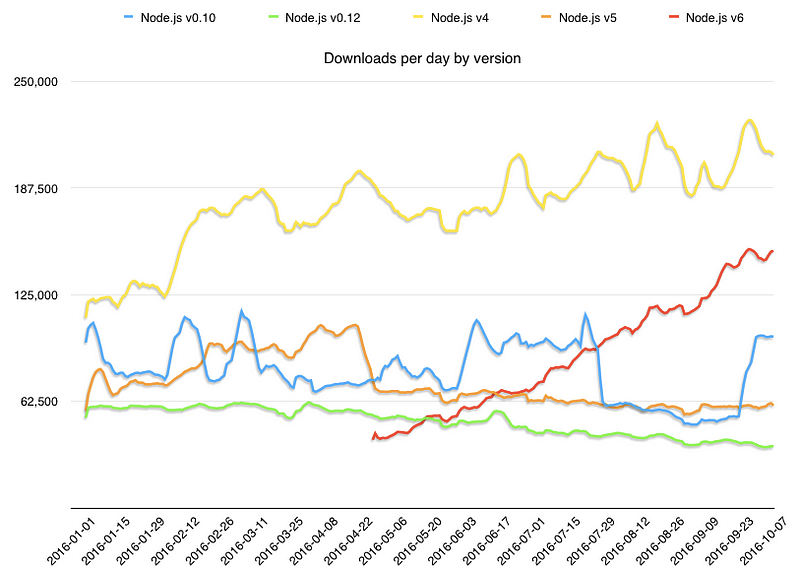
*Data pulled from Node.js metrics section: https://nodejs.org/metrics/
Time To Transition Off v0.12 & v0.10
On v0.12, v0.10, v5? Please upgrade! We understand you may have time constraints, but Node.js v0.10 will not be maintained after this month (October). This means no further official releases, including fixes for critical security bugs. End of life for Node.js v0.12 will be December 2016.
You might be wondering what our main reasons are for doing this? After December 31, we won’t be able to get OpenSSL updates for those versions. So that means we won’t be able to provide any security updates.
Additionally, the Node.js Core team has been maintaining the version of V8 included in Node.js v0.10 alone since the Chromium team retired it four years ago. This represents a risk for users as the team will no longer maintain this.
If you have a robust test environment setup, then an upgrade to Node.js v6 is what we would suggest. If you don’t feel comfortable making that big of a version leap, then Node.js v4 is also a good upgrade, however it won’t be supported as long as Node.js v6.
Node.js v4 and Node.js v6 are more stable than Node.js v0.10 and v0.12 and have more modern versions of V8, OpenSSL, and other critical dependencies. Bottom line: it’s time to get update.
What’s holding you back from upgrading? Let us know it the comments section below. If you have questions along the way, please ask them in this forum: https://github.com/nodejs/help
Okay, So What’s the Deal with Node.js v7?
Node.js v7 was released into beta at the end of September and is due to be released the week of October 25. Node.js v7 is a checkpoint release for the Node.js project and will focus on stability, incremental improvement over Node.js v6, and updating to the latest versions of V8, libuv, and ICU.
Node.js v7 will ship with JavaScript Engine V8 5.4, which focuses on performance improvements linked to memory. Included in this are new JavaScript language features such as the exponentiation operator, new Object property iterators, and experimental support for async functions. To note, the async function support will be unsupported until V8 5.5 ships. These features are still in experimental mode, so you can play around with them, but they likely contain bugs and should not be used in production.
Given it is an odd numbered release, it will only be available for eight months with its end of life slated for June 2017. It has some really awesome features, but it might not be right for you to download. If you can easily upgrade your deployment and can tolerate a bit of instability, then this is a good upgrade for you.
Want more technical information about breaking changes in Node.js v7? See the full list here: https://github.com/nodejs/node/pull/9099
Beyond v7, we’ll be focusing our efforts on language compatibility, adopting modern web standards, growth internally for VM neutrality and API development, and support for growing Node.js use cases. To learn more, check out James Snell’s’ recent keynote from Node.js Interactive Amsterdam “Node.js Core State of the Union” on where Node.js core has been over the past year and where we’re going. James is a member of the Node.js Technical Steering Committee. Additional technical details around Node.js v6 and additional release lines can be found here.
This article originally appeared on the Node.js Foundation blog.




