Microservices allow engineering teams to move quickly to grow a product… assuming they don’t get bogged down by the complexity of operating a distributed system. In this post, I’ll show you how some of the hardest operational problems in microservices—staging and canarying of deep services—can be solved by introducing the notion of routing to the RPC layer.
Looking back at my time as an infrastructure engineer at Twitter (from 2010 to 2015), I now realize that we were “doing microservices”, though we didn’t have that vocabulary at the time. (We used what I now understand to be a bad word—SOA).
Buzzwords aside, our motivations were the same as those doing microservices today. We needed to allow engineering teams to operate independently—to control their own deploy schedules, on call rotations, availability, and scale. These teams needed the flexibility to iterate and scale quickly and independently—without taking down the site.
In 2008, Patrick Debois laid the foundations for DevOps at an Agile conference in Toronto. He was trying to come up with a solution for the inherent conflicts between developers and system admins. Both disciplines seemed to be at odds: developers wanted to release software more frequently, but system admins wanted to ensure stability, performance, and scalability. While this conflict isn’t necessarily black and white, it highlighted the need for developers and system admins to no longer consider themselves as mutually exclusive roles, but rather as cross-functional partners.
A year later, Paul Hammond and John Allspaw gave a talk at the Velocity ‘09 conference that highlighted the necessity for cooperation between Dev and Ops. This inspired Debois to coin the term “DevOps” (#DevOps)…
This tutorial will be the first in a series that will help you create continuous integration and deployment (CI/CD) pipelines for your applications.
CI/CD are vital in an Agile organization. We are going to discover how the addition of Docker tools in our toolkit can greatly improve application updates, testing and shipping.
Depending on your resources and constraints, there are of course multiple ways of achieving such a goal. Here, we are going to start simple and discover the free tools that Docker has made available to us.
You are going to create a Dockerfile for a simple web application, build it, get it to run locally, store it online, and create your first automated build on Docker Hub.
Requirements
A valid account on Docker Hub
A valid account on either Github or Bitbucket. Both platforms have free plans to get you started.
Docker toolbox installed and running on your local machine.
Create a local repo for your app
For this tutorial you will use a very simple Flask application, written in python, and create a production ready Docker image.
Create a folder for your application code and initiate a git repo in it with:
mkdir flask-demo-app
cd flask-demo-app
git init
Add the following code in a file named app.py:
from flask import Flask
app = Flask(__name__)
app.debug = True
@app.route('/')
def main():
return 'Hi ! I'm a Flask application.'
if __name__ == '__main__':
app.run(host='0.0.0.0')
Docker helps us stay as DRY as possible, by giving us the ability to extend an already existing image. Here, I propose to use the image jazzdd/alpine-flask, as it is based on Alpine Linux, thus very lightweight.
Create a Dockerfile with the following content in it:
Test it by running curl in a temporary container with:
docker run --rm --link app:app byrnedo/alpine-curl http://app
You should see in your terminal something like:
Hi ! I'm a Flask application.
Stop and remove your container with:
docker rm -vf app
Add and commit your files to your local repo:
git add app.py Dockerfile
git commit -a -m "Initial commit"
Upload your repo online
Here, you can choose either Github or Bitbucket. Both are very well supported by Docker Hub. In case it’s the first time you’re doing this, here are the links to their documentation:
If you navigate through the web interface, you should now see the code of your application.
Create an automated build on Docker Hub
In the top right part of your Docker Hub account web interface, click on the create automatic build button and follow the process, which is really self-explanatory.
In the top right part of your Docker Hub account web interface, click on the create automatic build button.
As the documentation is not exactly up to date, you will need to trigger the first build manually by clicking on the Trigger button in the Build settings tab:
Test your Build
Once you’ve created your automatic build and triggered its first run, you should now be able to test it with:
docker run -d --name app -p 80:80 <your_docker_hub_id>/<your_project_name>:latest
Stop and remove this container, once you’re done with it.
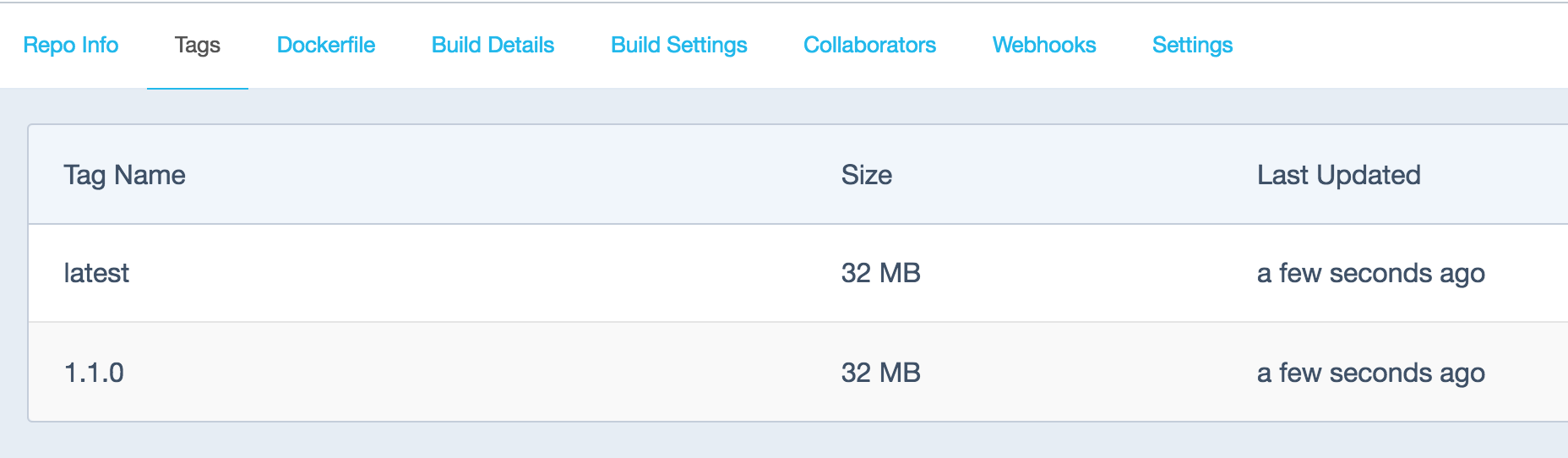
Version tagging
One of the most interesting features of the Hub is the ability to tag your Docker images. This way you can easily differentiate between them and, in the case of a problem with a specific version, perform a rollback.
In most cases the default configuration should suffice. It is very well integrated with Github and Bitbucket repositories.
When using a specific git branch name, Docker Hub will create your images with the matching tags.
Create a branch for a newer version of your code.
git checkout -b 1.1.0
Modify your app.py code with:
def main():
return 'Hi ! I'm a Flask application in a Docker container.'
Upload your new branch:
git push -u origin 1.1.0
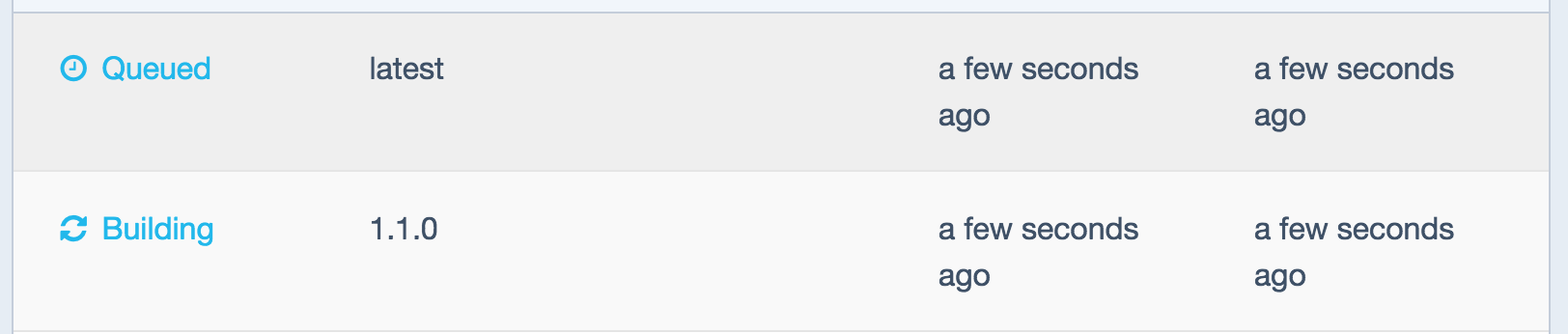
See the new image being built:
See the new image being built.
A new tagged build is now available:
A new tagged build is now available.
Run it with:
docker run -d --name app -p 80:80 <your_docker_hub_id>/<your_project_name>:1.1.0
Bravo, you just connected to the version 1.1.0 of your application!
Conclusion
As I mentioned earlier, using Docker Hub to build your images each time the code is modified and pushed to repository has some limitations. As of today it will build your images at the most every 5 minutes. But it is certainly a very cheap way of doing so as you don’t have to maintain your own repository. Later on, you might want to look into using base images of your making and hosting your own private Docker registry for obvious privacy and performance reasons.
Next time, we will explore how to run unit tests on your application using Travis.
Plasma has always been the talk of the town for its sleek and cutting edge look. KDE Plasma among all other Linux Desktop Environments have always stood out for its continuous development. The latest release of KDE Plasma is 5.6 which includes some new features, tweaks and fixes. Plasma desktop is also highly customizable so that you can customize it the way you need it to be.
While cloud is still top of mind for many chief information officers, Red Hat office of technology vice president and chief technologist Chris Wright believes an increasing area of focus for businesses today is trying to figure out how to automate their infrastructure stack.
Speaking to ZDNet, Wright said a key goal of many businesses today is to improve their speed to market, and part of making that happen has been through automation so that engineers and developers can focus on application development, rather than be concerned with running the backend.
“It’s all about the application at the end of the day; we’re not just building infrastructure to just sit there … we actually want to do real work and that work is generated from application developers being able to quickly build apps,” he said.
Traditional approaches to network management and security are ill-suited for the fluid nature of container and microservices-based architectures. Containers appear, disappear and are moved around to different compute nodes far too frequently to be assigned static IP addresses, much less be protected by firewalls and IP tables at the network’s perimeter.
With this in mind, two open source projects, CoreOS’ Flannel virtual networking technology, and the Project Calico, another network overlay technology with strong security controls, have joined forces to offer a single package, called Canal, that will offer policy-based secure networking for the container and microservices era.
A new San Francisco-based company has been formed, Tigera, that will manage both projects. Tigera is a spin-off of network solutions provider Metaswitch, and many of the San Francisco Metaswitch engineers who worked on Calico have moved over to Tigera. CoreOS is donating the Flannel codebase to Tigera.
When combined, SDN and NFV promise to bring an unprecedented level of digital control to global IT networks.
While software-defined networking (SDN) shuns proprietary hardware for an open, programmable global network infrastructure that can be centrally managed, network functions virtualization (NFV) enables features, such as firewall/proxy and acceleration, to be virtualized and delivered either from the network or from customer premise equipment (CPE), enabling zero touch provisioning when additional functionality is required.
Together these technologies make it possible for enterprises to access network capacity on demand via a self-service portal. In addition, routing and security policies can automatically adapt to address real-time congestion, security threats or network outages.
Countless organizations around the world are now working with data sets so large and complex that traditional data processing applications can no longer drive optimized analytics and insights. That’s the problem that the new wave of Big Data applications aims to solve, and the Apache Software Foundation (ASF) has recently graduated a slew of interesting open source Big Data projects to Top-Level status. That means that they will get active development and strong community support.
Most people have heard of Apache Spark,a Big Data processing framework with built-in modules for streaming, SQL, machine learning and graph processing. IBM and other companies are pouring billions of development dollars into Spark initiatives, and NASA and theSETI Institute are collaborating to analyze terabytes of complex deep space radio signals using Spark’s machine learning capabilities in a hunt for patterns that might betray the presence of intelligent extraterrestrial life.
However, several other recently elevated Apache Big Data projects deserve attention, too. In fact, some of them may produce ecosystems of activity and development that will rival Spark’s. In conjunction with this week’sApacheCon North America conference and Apache: Big Data events, this article will round up the Apache Big Data projects that you should know about.
Apache recentlyannounced that its Kylin project, an open source Big Data project born at eBay, has graduated to Top-Level status. Kylin is an open source Distributed Analytics Engine designed to provide an SQL interface and multi-dimensional analysis (OLAP) on Apache Hadoop, supporting extremely large datasets. It is still widely used at eBay and at a few other organizations.
“Apache Kylin’s incubation journey has demonstrated the value of Open Source governance at ASF and the power of building an open-source community and ecosystem around the project,” said Luke Han, Vice President of Apache Kylin. “Our community is engaging the world’s biggest local developer community in alignment with the Apache Way.”
As an OLAP-on-Hadoop solution, Apache Kylin aims to fill the gap between Big Data exploration and human use, “enabling interactive analysis on massive datasets with sub-second latency for analysts, end users, developers, and data enthusiasts,” according to developers. “Apache Kylin brings back business intelligence (BI) to Apache Hadoop to unleash the value of Big Data,” they added.
Apache also recently announced that Apache Lens, an open source Big Data and analytics tool, has graduated from the Apache Incubator to become a Top-Level Project (TLP). According to theannouncement: “Apache Lens is a Unified Analytics platform. It provides an optimal execution environment for analytical queries in the unified view. Apache Lens aims to cut the Data Analytics silos by providing a single view of data across multiple tiered data stores.”
“By providing an online analytical processing (OLAP) model on top of data, Lens seamlessly integrates Apache Hadoop with traditional data warehouses to appear as one. It also provides query history and statistics for queries running in the system along with query life cycle management.”
“Incubating Apache Lens has been an amazing experience at the ASF,” said Amareshwari Sriramadasu, Vice President of Apache Lens. “Apache Lens solves a very critical problem in Big Data analytics space with respect to end users. It enables business users, analysts, data scientists, developers and other users to do complex analysis with ease, without knowing the underlying data layout.”
The ASF has alsoannounced that Apache Ignite has become a top-level project. It’s an open source effort to build an in-memory data fabric.
“Apache Ignite is a high-performance, integrated and distributed In-Memory Data Fabric for computing and transacting on large-scale data sets in real-time, “orders of magnitude faster than possible with traditional disk-based or flash technologies,” according to Apache community members. “It is designed to easily power both existing and new applications in a distributed, massively parallel architecture on affordable, industry-standard hardware.”
The foundationannounced that Apache Brooklyn is now a Top-Level Project (TLP), “signifying that the project’s community and products have been well-governed under the ASF’s meritocratic process and principles.” Brooklyn is an application blueprint and management platform used for integrating services across multiple data centers as well as and a wide range of software in the cloud.
According to the Brooklyn announcement: “With modern applications being composed of many components, and increasing interest in micro-services architecture, the deployment and ongoing evolution of deployed apps is an increasingly difficult problem. Apache Brooklyn’s blueprints provide a clear, concise way to model an application, its components and their configuration, and the relationships between components, before deploying to public Cloud or private infrastructure. Policy-based management, built on the foundation of autonomic computing theory, continually evaluates the running application and makes modifications to it to keep it healthy and optimize for metrics such as cost and responsiveness.”
Brooklyn is in use at some notable organizations. Cloud service providers Canopy and Virtustream have created product offerings built on Brooklyn. IBM has also made extensive use of Apache Brooklyn in order to migrate large workloads from AWS to IBM Softlayer.
In April, the Apache Software Foundationelevated its Apex project to Top-Level status.It is billed as “a large scale, high throughput, low latency, fault tolerant, unified Big Data stream and batch processing platform for the Apache Hadoop ecosystem.” Apex works in conjunction with Apache Hadoop YARN, a resource management platform for working with Hadoop clusters.
Finally, Apache Tajo, an advanced open source data warehousing system in Apache Hadoop, is another new Big Data project to know about. Apache claims that Tajo provides the ability to rapidly extract more intelligence for Hadoop deployments, third party databases, and commercial business intelligence tools.
Clearly, although Apache Spark draws the bulk of the headlines, it is not the only Big Data tool from Apache to keep your eyes on. As this year continues, Apache likely will graduate even more compelling Big Data projects to Top-Level status, where they will benefit from optimized development resources and more.
A user group for enterprise IT managers is taking on software-defined networking, calling for new technologies they say would better serve enterprise needs.
On Tuesday, the Open Networking User Group (ONUG) announced initiatives behind four technologies that it says would help enterprises build and run their networks better.
There’s no shortage of platforms and protocols for software-defined infrastructure, including things like OpenFlow, OpenStack and ONOS (Open Network Operating System). But they were developed around the needs of vendors and service providers more than of enterprises, ONUG founder Nick Lippis said. His group wants to push along a few more pieces that aren’t there yet.
SDN (software-defined networking) has been around since 2009 and found its way into some major products and some enterprise and carrier implementations. SD-WAN, a variant for wide-area networks, is expected to grow quickly in the next few years.
Both place more control of infrastructure into software, which can bring new capabilities and let less expensive commodity hardware take the place of proprietary gear.
In his keynote address at the Embedded Linux Conference’s OpenIoT Summit, Open Connectivity Foundation (OCF) Executive Director Mike Richmond discussed the potential for interoperability — and a possible merger — between the two major open source IoT frameworks: the OCF’s IoTivity and the AllSeen Alliance’s AllJoyn spec. “We’ve committed to interoperability between the two,” said Richmond, who went on to explain how much the two Linux Foundation hosted specs had in common.
Richmond also seemed open to a merger, although he framed this as a more challenging goal. “The political part of this is going to be with us even if we make the technical problem less severe,” he said.
The launch of the OCF in February was seen as a major victory for IoTivity in its competition with AllSeen and other IoT groups. IoTivity emerged in July, 2014, from the Open Interconnect Consortium (OIC), with members including Intel, Atmel, Dell, and Samsung. OIC and IoTivity arrived seven months after The Linux Foundation joined with Qualcomm, Haier, LG, Panasonic, Sharp, Cisco, and others to found the AllSeen Alliance, built around Qualcomm’s AllJoyn framework. Shortly before OIC was formed, Microsoft joined AllSeen.
In November of 2015, OIC acquired the assets of the Universal Plug and Play (UPnP) Forum, and in February of this year, OIC morphed into OCF. The transition was notable not only for the fact that OCF would be hosted by The Linux Foundation, which already sponsored AllSeen, but that Qualcomm, Microsoft, and Electrolux had joined the group.
The three companies remain AllSeen members, but the cross-pollination increased the potential for a merger between the groups — or if not, perhaps the rapid decline of AllSeen. Behind the scenes, a big change from OIC to OCF is the emergence of a new plan for adjudicating intellectual property claims within an open source framework, as detailed in this February VDC Research report.
In Richmond’s keynote, he explained why strong interoperability was so important. Without better standardization, it will be impossible to achieve the stratospheric expectations for the IoT market, he said. “There simply aren’t enough embedded engineers around to make customized solutions.”
In Richmond’s view, IoTivity and AllSeen are both well-suited to bring order to the fractured IoT world because they’re horizontal, mostly middleware-oriented frameworks. Both are agnostic when it comes to OSes on the one hand or wireless standards on the other.
“Maybe the radios have to be different down there or maybe it doesn’t even have to be a radio, but is it that different in the middle?” said Richmond, pointing to an architecture diagram. “That’s why we picked out this horizontal slice. We think there is a lot of commonality across markets and geographies.”
Richmond noted that neither group is dominated by a single tech giant, and that they have similar approaches to open source governance. “What we have in common is the belief that multiple companies should decide how IoT works, not just one,” said Richmond. Pointing to the success of the W3C Consortium, he added: “In the long run, we think that horizontal standards plus open source is what wins.”
OCF Executive Director Mike Richmond (left) on stage with Greg Burns, Chief IoT Software Technologist at Intel, at OpenIoT Summit.
At the end of the keynote, Richmond flashed a slide of a wedding invitation and then invited to the stage Greg Burns, who was the central creator of AllJoyn when he worked at the Qualcomm Innovation Center (QIC). Burns, who is now Chief IoT Software Technologist at Intel, has been one of the most active proponents of a merger.
The goals of the OCF and AllSeen are the same, argued Burns. “It’s the idea of having standardized data models and wire protocols, proximal first, with cloud connectivity,” he said. “There’s a lot of common terminology and agreement on the approach. They both use IP multicast for discovery.”
The specifics of the wire protocol “don’t matter that much,” continued Burns, and the same goes for some other components. “We can argue about whether object-oriented is better than a RESTful architecture, but ultimately it comes down to personal preferences,” he said. “My vision is that if we were to bring the components of each of these technologies together, we would evolve something that is better than either individually. We really do benefit as an industry and community if we have one standard, and my hope is that we can get there.”
“That’s my hope, too,” added Richmond.
In another ELC presentation, called “AllSeen Alliance, AllJoyn and OCF, IoTivity — Will We Find One Common Language for Open IoT?,” Affinegy CTO Art Lancaster seemed to agree that a high degree of interoperability was possible — but not at the expense of killing off AllSeen. Affinegy, which has developed the “Chariot” IoT stack, has been a major cheerleader for AllSeen, and Lancaster emphasized that AllSeen has a big lead in certifications compared to Iotivity.
I asked Philip DesAutels, senior director of IoT for The Linux Foundation, about the potential for interoperability or merger, and he had this to say. “The easiest and most enduring route to achieving a real and lasting IoT is one common framework,” said DesAutels. “That means bringing together disparate communities each with their own divergent approaches. Convergence and unification are key, but compromise and understanding take time.” DesAutels also noted the importance of the open source Device System Bridge contributed by Microsoft to the AllSeen Alliance, enabling AllJoyn® interoperability with IoTivity and other IoT protocols.”
Both Richmond and Lancaster made it clear that there are many dozens of other overlapping IoT interoperability efforts that must also be considered in developing a universal standard. At ELC, Intel’s Bruce Beare gave a presentation on one of the, Google’s open source Weave framework. Meanwhile, Samsung’s Phil Coval delivered a presentation on integrating IoTivity with Tizen, which Samsung is increasingly aiming at IoT.