

Most every Linux distribution is based on another one. Many are based on Ubuntu or Debian, some are based on Fedora, while others are based on Arch Linux. And, even when a distribution offers different types of releases (stable vs. rolling, or various available desktops), they are generally based on the same base platform.
Netrunner, however, takes a slightly different approach. If that name sounds slightly familiar, you might remember the Collectable Card Game from the 1990s that pitted two players against each other — one playing a corporation and one playing a hacker attempting to break into the corporation’s network. There is no indication that Blue Systems (the company supporting Netrunner) named the OS after the game, but it’s a great launching point for yet another Linux distribution.
So, what is Netrunner doing differently? The main trick they have up their sleeve is that the distribution is offered in three different flavors:
-
Stable
-
Rolling
-
Core
That is a fairly common offering these days. But, whereas Netrunner’s Stable and Core releases are based on Debian Testing, the Rolling release is based on Manjaro (which is itself based on Arch Linux). So, depending upon the release cycle you want, you may be using a Debian-based or Arch-based distribution. No matter the choice of base, however, Netrunner only offers one desktop—a modified version of KDE Plasma. That modified Plasma desktop might intrigue some users and might put some users off. Why? Because, at first blush, the desktop offered on Netrunner looks as much like a Mate or Cinnamon interface as it does KDE.
Let’s install Netrunner and see what makes this uniquely released distribution tick.
Installation
Once again, I’m happy to report that there is no need to discuss the installation of a Linux distribution. This has become quite a selling point for so many open source operating systems… that installation has become as easy as installing an application. Netrunner offers yet another point-and-click install that’s as easy as answering a few simple questions and clicking a few buttons. That’s all there is to it. Simple, fast, and user-friendly. This installation throws not a single trick at the user and, in roughly five to ten minutes, you’ll have the operating system up and running and ready to serve.
What’s installed
Out of the box (and after a single update), you’ll find kernel 4.14.0-3, KDE Plasma version 5.12.2, KDE Apps version 17.08.3, Frameworks version 5.42.0, and Qt version 5.9.2. Along with those pieces, you’ll find the following installed software:
-
Synaptic Package Manager for the stable release and Octopi (Pacman front-end) for the rolling release (along with KDE’s Discovery on both).
-
Audacious (music player)
-
Firefox (web browser)
-
GIMP (image editor)
-
GMusic Browser (another music player)
-
HandBrake (video converter)
-
Inkskape (vector image editor)
-
Kamoso (webcam software)
-
Kdenlive (video editor)
-
LibreOffice (office suite)
-
Pidgin Internet Messenger (chat/message client)
-
Skype (VOIP client)
-
Steam (game console)
-
Thunderbird (email client)
-
VirtualBox (Virtual Machine manager)
-
Vokoscreen (screencasting)
-
Yakuake (terminal)
-
Yarock (music player)
Clearly, Netrunning contains all the software you need to get started with Linux on the desktop (especially if you’re a fan of music). The only qualm I have with the list of included software is that GMusic Browser is way out of date. The latest stable version was released August 20, 2015. I’d much rather see the likes of Clementine included, as it is under regular development. Or, just stick with Yarock (which is much more current, with the latest release out February 11, 2018).
It should also be noted that Firefox is installed along with the uBlock Origin extension. UBlock Origin is a web blocker that doesn’t consume much in the way of system resources. It’s easy to use and automatically filters with the help of the following lists:
-
EasyList
-
Peter Lowe’s Ad server list
-
EasyPrivacy
-
Malware domains
You won’t find anything by way of development packages installed out of the box. Of course, as this is Linux, all of the tools you need for development are a quick install away.
The Changes to KDE Plasma
What Netrunner has done with KDE is, effectively, organized the various modules such that the desktop becomes much more immediately familiar with users, with few of the standard KDE bits at the fore. The best way to test these changes is by opening the System Settings tool and going to the Plasma Tweaks section. Here you’ll find every aspect of KDE that has been tweaked by the developers (Figure 1).
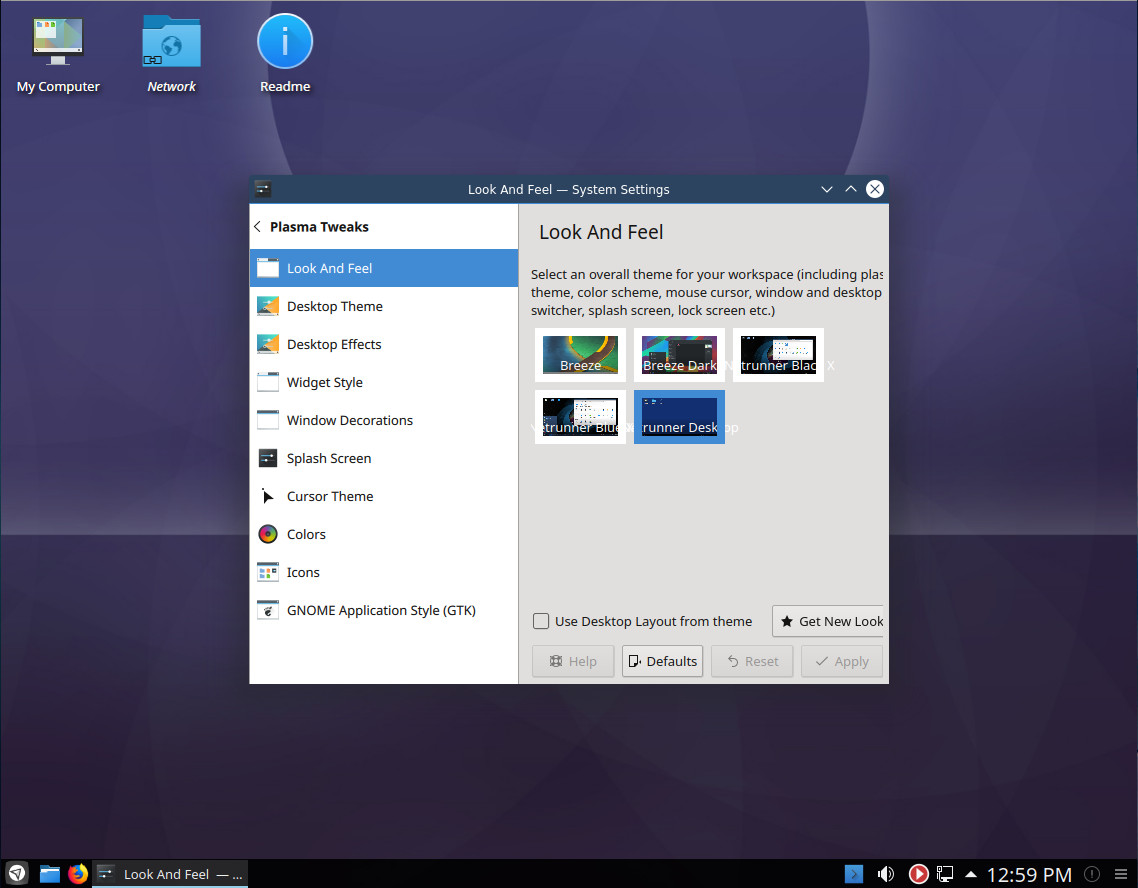
Select a different theme under Look And Feel, make sure to select Use Desktop Layout from theme, and click Apply. For example, select the Breeze theme and you’ll see how different the default Plasma desktop is from what Netrunner has done (Figure 2).
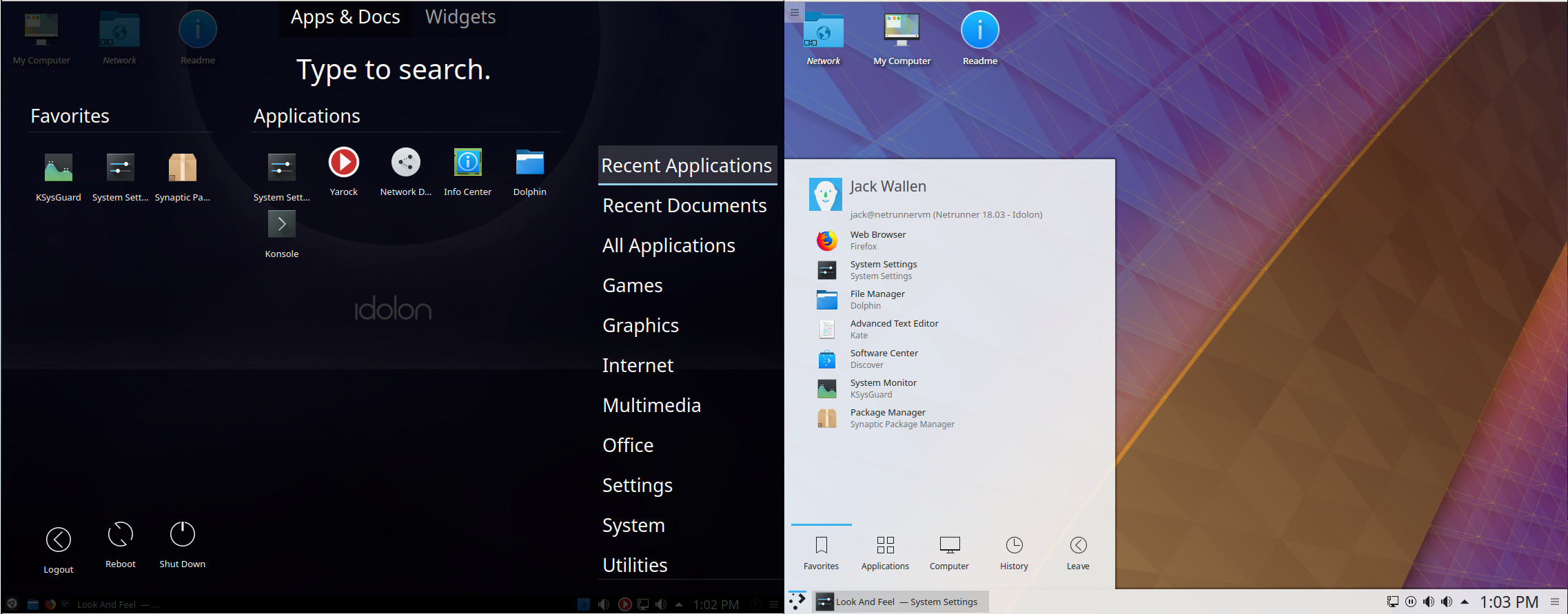
The changes made to the KDE Plasma do not detract from how efficient and user-friendly it is, they only enhance it. However, for those that prefer the default KDE Plasma desktop, it’s just a couple of clicks away. But if the likes of Mate or Cinnamon are up your alley, you’ll love what the developers have done with KDE. Either way, the desktop runs incredibly smoothly and performs like a champ (even when running as a VirtualBox virtual machine).
Take your pick
Whether you prefer a stable, bleeding edge, or minimal distribution, Netrunner has you covered. If you prefer the simplicity of Debian or the flexibility of Arch Linux, Netrunner still has you covered. No matter your pick, this flavor of Linux is a desktop that is sure to please most Linux users, regardless of experience or preference.
To download Netrunner, visit the distribution’s download page and select from the Debian-based, the Arch-based, or the core. You’ll only find 64-bit versions of each (as well as an Arm-based version), so make sure you have the proper hardware before starting the download.
Learn more about Linux through the free “Introduction to Linux” course from The Linux Foundation and edX.



