
A founding platinum member of The Linux Foundation since its inception in 2007 and on the board of directors, Oracle is dedicated to the worldwide success of Linux for organizations of all sizes and across all industries. This year Oracle is a silver sponsor at Open Source Summit 2018. Please join us for an engaging Keynote Session by Greg Marsden: Preventing…
Click to Read More at Oracle Linux Kernel Development
Visit us at Open Source Summit – Vancouver, August 29-31

Oracle Database Runs Best on Oracle Linux

Why does Oracle Database run best on Oracle Linux? A new white paper is now available where you’ll learn what makes the Oracle Linux cloud-ready operating system a cost-effective and high-performance choice when modernizing infrastructure or consolidating Oracle Database instances. When you deploy Oracle Database on Oracle Linux, you can have the confidence that you are deploying on an operating system backed by…
Click to Read More at Oracle Linux Kernel Development
Oracle Database Runs Best on Oracle Linux

Why does Oracle Database run best on Oracle Linux? A new white paper is now available where you’ll learn what makes the Oracle Linux cloud-ready operating system a cost-effective and high-performance choice when modernizing infrastructure or consolidating Oracle Database instances. When you deploy Oracle Database on Oracle Linux, you can have the confidence that you are deploying on an operating system backed by…
Click to Read More at Oracle Linux Kernel Development
Oracle Database Runs Best on Oracle Linux

Why does Oracle Database run best on Oracle Linux? A new white paper is now available where you’ll learn what makes the Oracle Linux cloud-ready operating system a cost-effective and high-performance choice when modernizing infrastructure or consolidating Oracle Database instances. When you deploy Oracle Database on Oracle Linux, you can have the confidence that you are deploying on an operating system backed by…
Click to Read More at Oracle Linux Kernel Development
Systemd Timers: Three Use Cases

In this systemd tutorial series, we have already talked about systemd timer units to some degree, but, before moving on to the sockets, let’s look at three examples that illustrate how you can best leverage these units.
Simple cron-like behavior
This is something I have to do: collect popcon data from Debian every week, preferably at the same time so I can see how the downloads for certain applications evolve. This is the typical thing you can have a cron job do, but a systemd timer can do it too:
# cron-like popcon.timer [Unit] Description= Says when to download and process popcons [Timer] OnCalendar= Thu *-*-* 05:32:07 Unit= popcon.service [Install] WantedBy= basic.target
The actual popcon.service runs a regular wget job, so nothing special. What is new in here is the OnCalendar= directive. This is what lets you set a service to run on a certain date at a certain time. In this case, Thu means “run on Thursdays” and the *-*-* means “the exact date, month and year don’t matter“, which translates to “run on Thursday, regardless of the date, month or year“.
Then you have the time you want to run the service. I chose at about 5:30 am CEST, which is when the server is not very busy.
If the server is down and misses the weekly deadline, you can also work an anacron-like functionality into the same timer:
# popcon.timer with anacron-like functionality [Unit] Description=Says when to download and process popcons [Timer] Unit=popcon.service OnCalendar=Thu *-*-* 05:32:07 Persistent=true [Install] WantedBy=basic.target
When you set the Persistent= directive to true, it tells systemd to run the service immediately after booting if the server was down when it was supposed to run. This means that if the machine was down, say for maintenance, in the early hours of Thursday, as soon as it is booted again, popcon.service will be run immediately and then it will go back to the routine of running the service every Thursday at 5:32 am.
So far, so straightforward.
Delayed execution
But let’s kick thing up a notch and “improve” the systemd-based surveillance system. Remember that the system started taking pictures the moment you plugged in a camera. Suppose you don’t want pictures of your face while you install the camera. You will want to delay the start up of the picture-taking service by a minute or two so you can plug in the camera and move out of frame.
To do this; first change the Udev rule so it points to a timer:
ACTION=="add", SUBSYSTEM=="video4linux", ATTRS{idVendor}=="03f0",
ATTRS{idProduct}=="e207", TAG+="systemd", ENV{SYSTEMD_WANTS}="picchanged.timer",
SYMLINK+="mywebcam", MODE="0666"
The timer looks like this:
# picchanged.timer [Unit] Description= Runs picchanged 1 minute after the camera is plugged in [Timer] OnActiveSec= 1 m Unit= picchanged.path [Install] WantedBy= basic.target
The Udev rule gets triggered when you plug the camera in and it calls the timer. The timer waits for one minute after it starts (OnActiveSec= 1 m) and then runs picchanged.path, which monitors to see if the master image changes. The picchanged.path is also in charge of pulling in the webcam.service, the service that actually takes the picture.
Start and stop Minetest server at a certain time every day
In the final example, let’s say you have decided to delegate parenting to systemd. I mean, systemd seems to be already taking over most of your life anyway. Why not embrace the inevitable?
So you have your Minetest service set up for your kids. You also want to give some semblance of caring about their education and upbringing and have them do homework and chores. What you want to do is make sure Minetest is only available for a limited time (say from 5 pm to 7 pm) every evening.
This is different from “starting a service at certain time” in that, writing a timer to start the service at 5 pm is easy…:
# minetest.timer [Unit] Description= Runs the minetest.service at 5pm everyday [Timer] OnCalendar= *-*-* 17:00:00 Unit= minetest.service [Install] WantedBy= basic.target
… But writing a counterpart timer that shuts down a service at a certain time needs a bigger dose of lateral thinking.
Let’s start with the obvious — the timer:
# stopminetest.timer [Unit] Description= Stops the minetest.service at 7 pm everyday [Timer] OnCalendar= *-*-* 19:05:00 Unit= stopminetest.service [Install] WantedBy= basic.target
The tricky part is how to tell stopminetest.service to actually, you know, stop the Minetest. There is no way to pass the PID of the Minetest server from minetest.service. and there are no obvious commands in systemd’s unit vocabulary to stop or disable a running service.
The trick is to use systemd’s Conflicts= directive. The Conflicts= directive is similar to systemd’s Wants= directive, in that it does exactly the opposite. If you have Wants=a.service in a unit called b.service, when it starts, b.service will run a.service if it is not running already. Likewise, if you have a line that reads Conflicts= a.service in your b.service unit, as soon as b.service starts, systemd will stop a.service.
This was created for when two services could clash when trying to take control of the same resource simultaneously, say when two services needed to access your printer at the same time. By putting a Conflicts= in your preferred service, you could make sure it would override the least important one.
You are going to use Conflicts= a bit differently, however. You will use Conflicts= to close down cleanly the minetest.service:
# stopminetest.service [Unit] Description= Closes down the Minetest service Conflicts= minetest.service [Service] Type= oneshot ExecStart= /bin/echo "Closing down minetest.service"
The stopminetest.service doesn’t do much at all. Indeed, it could do nothing at all, but just because it contins that Conflicts= line in there, when it is started, systemd will close down minetest.service.
There is one last wrinkle in your perfect Minetest set up: What happens if you are late home from work, it is past the time when the server should be up but playtime is not over? The Persistent= directive (see above) that runs a service if it has missed its start time is no good here, because if you switch the server on, say at 11 am, it would start Minetest and that is not what you want. What you really want is a way to make sure that systemd will only start Minetest between the hours of 5 and 7 in the evening:
# minetest.timer [Unit] Description= Runs the minetest.service every minute between the hours of 5pm and 7pm [Timer] OnCalendar= *-*-* 17..19:*:00 Unit= minetest.service [Install] WantedBy= basic.target
The line OnCalendar= *-*-* 17..19:*:00 is interesting for two reasons: (1) 17..19 is not a point in time, but a period of time, in this case the period of time between the times of 17 and 19; and (2) the * in the minute field indicates that the service must be run every minute. Hence, you would read this as “run the minetest.service every minute between 5 and 7 pm“.
There is still one catch, though: once the minetest.service is up and running, you want minetest.timer to stop trying to run it again and again. You can do that by including a Conflicts= directive into minetest.service:
# minetest.service [Unit] Description= Runs Minetest server Conflicts= minetest.timer [Service] Type= simple User= <your user name> ExecStart= /usr/bin/minetest --server ExecStop= /bin/kill -2 $MAINPID [Install] WantedBy= multi-user.targe
The Conflicts= directive shown above makes sure minetest.timer is stopped as soon as the minetest.service is successfully started.
Now enable and start minetest.timer:
systemctl enable minetest.timer systemctl start minetest.timer
And, if you boot the server at, say, 6 o’clock, minetest.timer will start up and, as the time falls between 5 and 7, minetest.timer will try and start minetest.service every minute. But, as soon as minetest.service is running, systemd will stop minetest.timer because it “conflicts” with minetest.service, thus avoiding the timer from trying to start the service over and over when it is already running.
It is a bit counterintuitive that you use the service to kill the timer that started it up in the first place, but it works.
Conclusion
You probably think that there are better ways of doing all of the above. I have heard the term “overengineered” in regard to these articles, especially when using systemd timers instead of cron.
But, the purpose of this series of articles is not to provide the best solution to any particular problem. The aim is to show solutions that use systemd units as much as possible, even to a ridiculous length. The aim is to showcase plenty of examples of how the different types of units and the directives they contain can be leveraged. It is up to you, the reader, to find the real practical applications for all of this.
Be that as it may, there is still one more thing to go: next time, we’ll be looking at sockets and targets, and then we’ll be done with systemd units.
Learn more about Linux through the free “Introduction to Linux” course from The Linux Foundation and edX.
5 Essential Tools for Linux Development

Linux has become a mainstay for many sectors of work, play, and personal life. We depend upon it. With Linux, technology is expanding and evolving faster than anyone could have imagined. That means Linux development is also happening at an exponential rate. Because of this, more and more developers will be hopping on board the open source and Linux dev train in the immediate, near, and far-off future. For that, people will need tools. Fortunately, there are a ton of dev tools available for Linux; so many, in fact, that it can be a bit intimidating to figure out precisely what you need (especially if you’re coming from another platform).
To make that easier, I thought I’d help narrow down the selection a bit for you. But instead of saying you should use Tool X and Tool Y, I’m going to narrow it down to five categories and then offer up an example for each. Just remember, for most categories, there are several available options. And, with that said, let’s get started.
Containers
Let’s face it, in this day and age you need to be working with containers. Not only are they incredibly easy to deploy, they make for great development environments. If you regularly develop for a specific platform, why not do so by creating a container image that includes all of the tools you need to make the process quick and easy. With that image available, you can then develop and roll out numerous instances of whatever software or service you need.
Using containers for development couldn’t be easier than it is with Docker. The advantages of using containers (and Docker) are:
-
Consistent development environment.
-
You can trust it will “just work” upon deployment.
-
Makes it easy to build across platforms.
-
Docker images available for all types of development environments and languages.
-
Deploying single containers or container clusters is simple.
Thanks to Docker Hub, you’ll find images for nearly any platform, development environment, server, service… just about anything you need. Using images from Docker Hub means you can skip over the creation of the development environment and go straight to work on developing your app, server, API, or service.
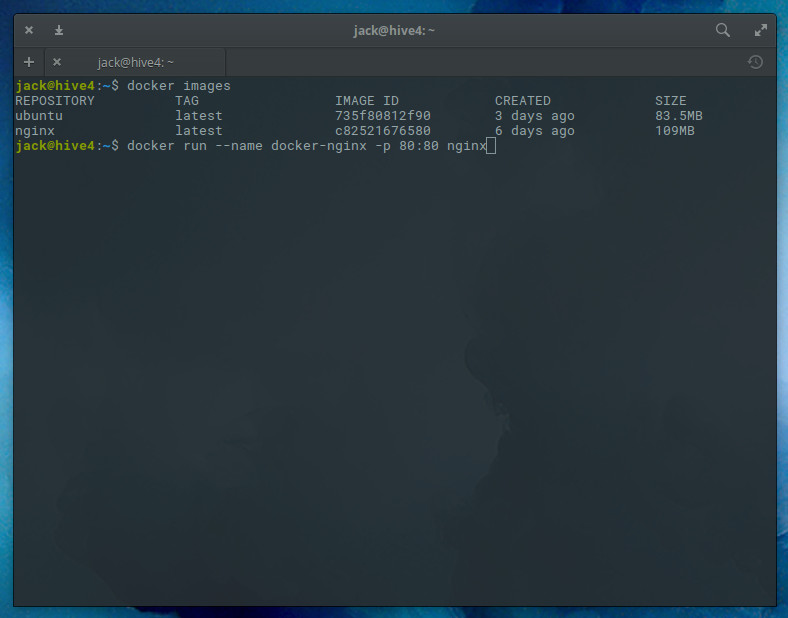
Docker is easily installable of most every Linux platform. For example: To install Docker on Ubuntu, you only have to open a terminal window and issue the command:
sudo apt-get install docker.io
With Docker installed, you’re ready to start pulling down specific images, developing, and deploying (Figure 1).
Version control system
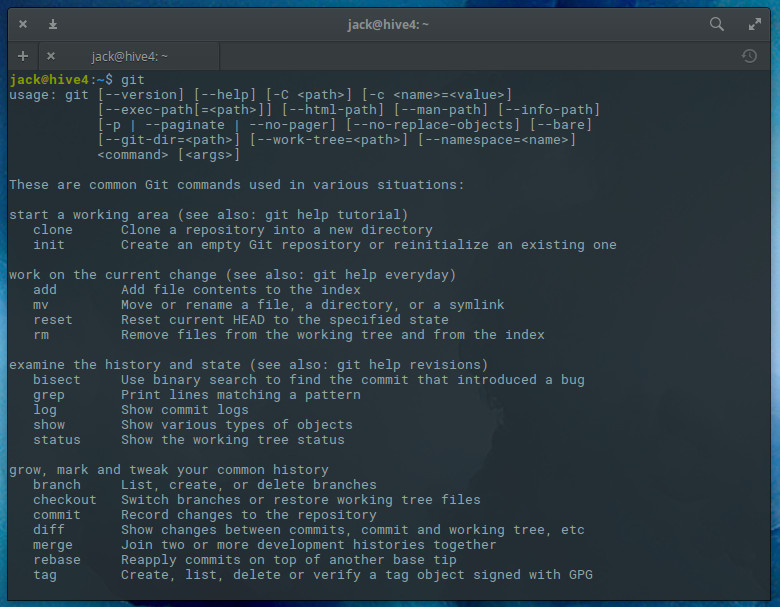
If you’re working on a large project or with a team on a project, you’re going to need a version control system. Why? Because you need to keep track of your code, where your code is, and have an easy means of making commits and merging code from others. Without such a tool, your projects would be nearly impossible to manage. For Linux users, you cannot beat the ease of use and widespread deployment of Git and GitHub. If you’re new to their worlds, Git is the version control system that you install on your local machine and GitHub is the remote repository you use to upload (and then manage) your projects. Git can be installed on most Linux distributions. For example, on a Debian-based system, the install is as simple as:
sudo apt-get install git
Once installed, you are ready to start your journey with version control (Figure 2).
Github requires you to create an account. You can use it for free for non-commercial projects, or you can pay for commercial project housing (for more information check out the price matrix here).
Text editor
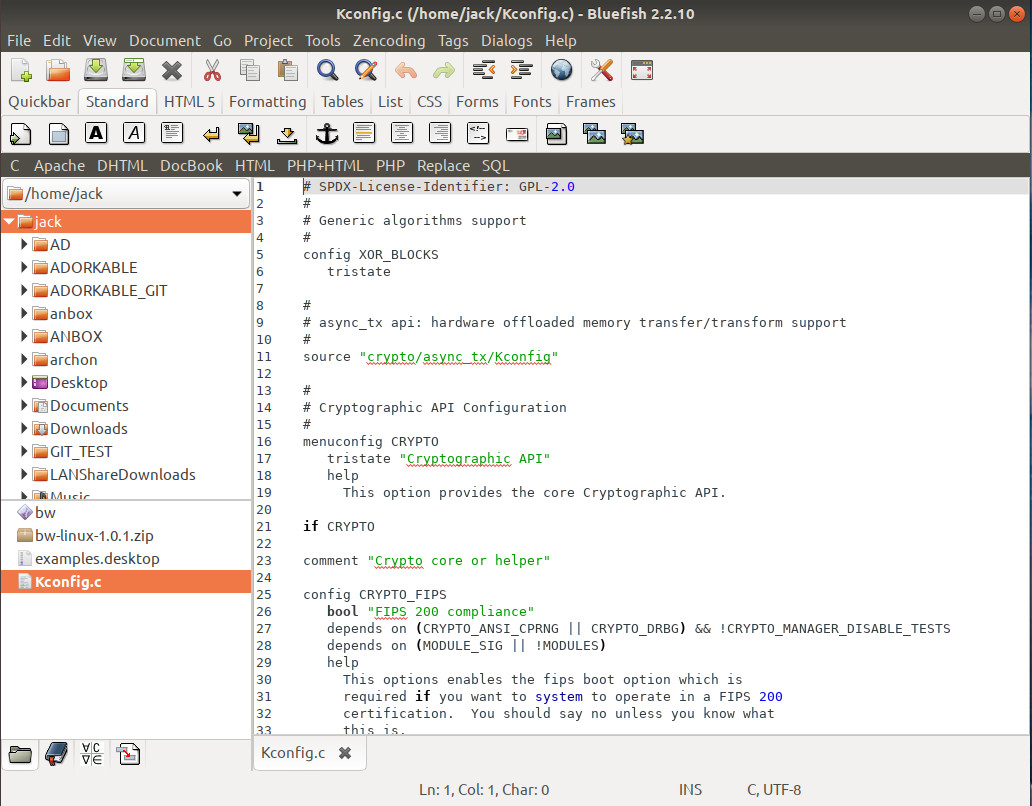
Let’s face it, developing on Linux would be a bit of a challenge without a text editor. Of course what a text editor is varies, depending upon who you ask. One person might say vim, emacs, or nano, whereas another might go full-on GUI with their editor. But since we’re talking development, we need a tool that can meet the needs of the modern day developer. And before I mention a couple of text editors, I will say this: Yes, I know that vim is a serious workhorse for serious developers and, if you know it well vim will meet and exceed all of your needs. However, getting up to speed enough that it won’t be in your way, can be a bit of a hurdle for some developers (especially those new to Linux). Considering my goal is to always help win over new users (and not just preach to an already devout choir), I’m taking the GUI route here.
As far as text editors are concerned, you cannot go wrong with the likes of Bluefish. Bluefish can be found in most standard repositories and features project support, multi-threaded support for remote files, search and replace, open files recursively, snippets sidebar, integrates with make, lint, weblint, xmllint, unlimited undo/redo, in-line spell checker, auto-recovery, full screen editing, syntax highlighting (Figure 3), support for numerous languages, and much more.
IDE
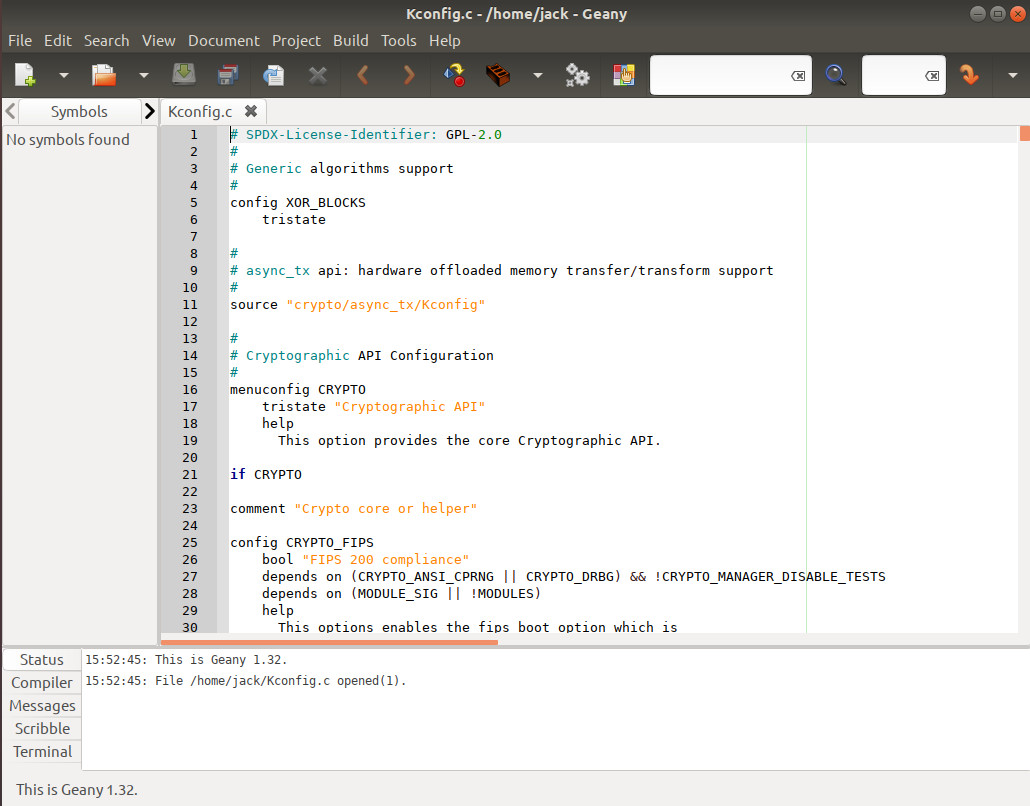
Integrated Development Environment (IDE) is a piece of software that includes a comprehensive set of tools that enable a one-stop-shop environment for developing. IDEs not only enable you to code your software, but document and build them as well. There are a number of IDEs for Linux, but one in particular is not only included in the standard repositories it is also very user-friendly and powerful. That tool in question is Geany. Geany features syntax highlighting, code folding, symbol name auto-completion, construct completion/snippets, auto-closing of XML and HTML tags, call tips, many supported filetypes, symbol lists, code navigation, build system to compile and execute your code, simple project management, and a built-in plugin system.
Geany can be easily installed on your system. For example, on a Debian-based distribution, issue the command:
sudo apt-get install geany
Once installed, you’re ready to start using this very powerful tool that includes a user-friendly interface (Figure 4) that has next to no learning curve.
diff tool
There will be times when you have to compare two files to find where they differ. This could be two different copies of what was the same file (only one compiles and the other doesn’t). When that happens, you don’t want to have to do that manually. Instead, you want to employ the power of tool like Meld. Meld is a visual diff and merge tool targeted at developers. With Meld you can make short shrift out of discovering the differences between two files. Although you can use a command line diff tool, when efficiency is the name of the game, you can’t beat Meld.
Meld allows you to open a comparison between to files and it will highlight the differences between each. Meld also allows you to merge comparisons either from the right or the left (as the files are opened side by side – Figure 5).
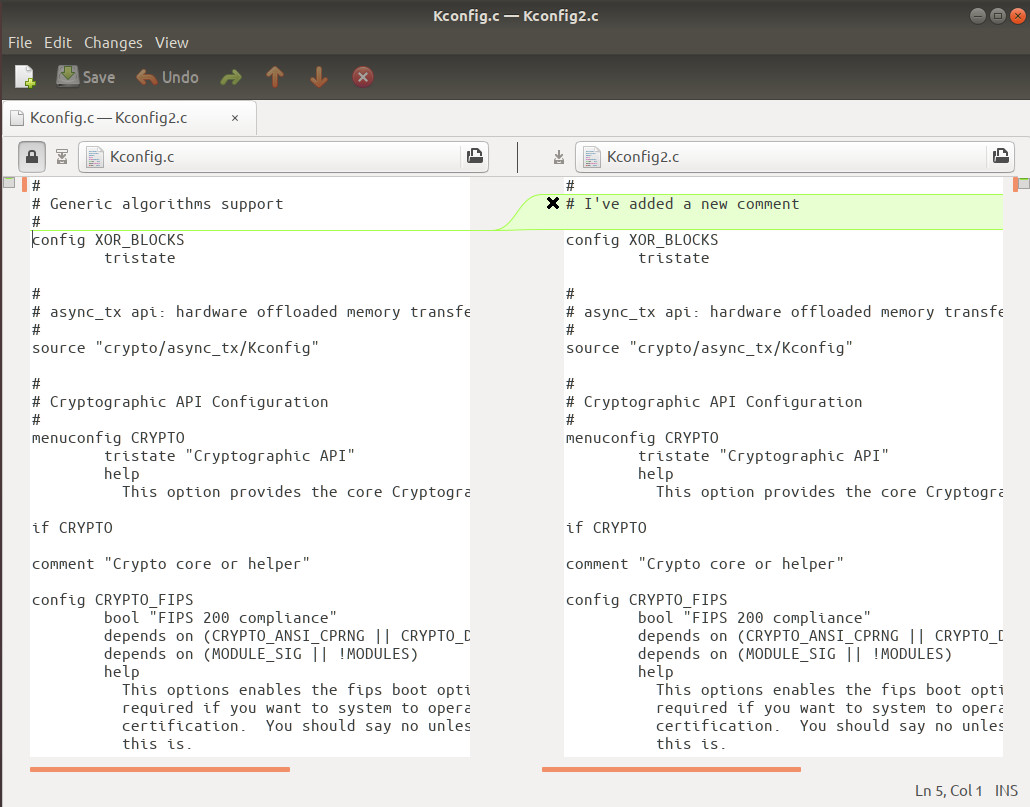
Meld can be installed from most standard repositories. On a Debian-based system, the installation command is:
sudo apt-get install meld
Working with efficiency
These five tools not only enable you to get your work done, they help to make it quite a bit more efficient. Although there are a ton of developer tools available for Linux, you’re going to want to make sure you have one for each of the above categories (maybe even starting with the suggestions I’ve made).
Learn more about Linux through the free “Introduction to Linux” course from The Linux Foundation and edX.