With 65% of companies using open source software, it’s not just internet-scale companies that can benefit from formal open source programs.
Many internet-scale companies, including Google, Facebook, and Twitter, have established formal open source programs (sometimes referred to as open source program offices, or OSPOs for short), a designated place where open source consumption and production is supported inside a company. With such an office in place, any business can execute its open source strategies in clear terms, giving the company tools needed to make open source a success. An open source program office’s responsibilities may include establishing policies for code use, distribution, selection, and auditing; engaging with open source communities; training developers; and ensuring legal compliance.
Check out the initial round of keynotes announced for Open Networking Summit North America 2018.
Hear from industry visionaries and leaders on the latest updates and the future of Networking beyond SDN/NFV including 5G & IoT; cloud networking (Kubernetes & Cloud Foundry); AI & ML applied to networks; and the use of networking in industry verticals like FinTech and Automotive. Including:
Vint Cerf, Vice President and Chief Internet Evangelist, Google
Andre Fuetsch, President, AT&T Labs, and Chief Technology Officer, AT&T
Wendy Cartee, Senior Director of Cloud-Native Applications Marketing, VMware
We have opened the LinuxCon + ContainerCon + CloudOpen China (LC3) 2018 call for proposals, and we invite you to share your expertise in this exploding open source market. Proposals are due March 4, 2018.
We’re seeking a wide range of talks, from topics such as Open Source Business & Strategy, Linux Development, Cloud Native and Containers, Networking, AI and more.
Got a great idea, case study, or technical tutorial you’d like to share? Learn more about the CFP process and submit your speaking proposal before the CFP closes on March 4.
Technology is like a good soufflé. The original recipe might be developed by an individual, but it changes and evolves as other people take the recipe and make it even better. And when you get the perfect combination of ingredients, it can be amazing.
That’s the idea behind the first-ever INDEX community event coming up February 20-22 in San Francisco, which will feature a keynote presentation from The Linux Foundation’s executive director, Jim Zemlin. Harnessing the power of shared innovation is crucial to remaining competitive in today’s markets, and Jim will discuss building sustainable open source projects to advance the next generation of modern computing.
There has never been a more pressing time to speed technology innovation. We are on the verge of an era of disruption, with artificial Intelligence and blockchain being just two examples of this. The INDEX developer conference features more than 100 sessions and keynotes exploring these and other technologies, and it provides a forum where developers can collaborate to build the perfect soufflé, er, solution.
Linux Foundation project communities will be interested in the free Open Community meetings taking place on February 20. Cloud Foundry, Hyperledger, architect and Node-RED (both hosted with the JS Foundation), Kubernetes (a Cloud Native Computing Foundation project), Node.js, OpenAPI Spec and R statistical language community members will each get together for half-day sessions. Registration for those is free.
Don’t miss the opportunity to meet and build with developers February 20-22 at INDEX.
Red Hat announced intention to buy CoreOS might affect the rest of the container ecosystem. Container runtime development will go forward, with perhaps more emphasis on the Kubernetes container runtime interface (CRI-O) project. However, the engineers at Docker, CoreOS and Red Hat continue to make contributions to other container runtime projects, such as containerd, rkt and Atomic. CoreOS’ Container Linux appears to be end-of-life in favor of Red Hat’s offering. CoreOS-led etcd and Flannel are already core components of many Kubernetes stacks and that will likely continue. Red Hat may also take the container registry Quay and bundle it into their larger container offering.
Originally created as an internal solution by YouTube to handle scaling for massive amounts of storage, Vitess is a database orchestration system for horizontal scaling of MySQL through generalized sharding. By encapsulating shard-routing logic, Vitess allows application code and database queries to remain agnostic to the distribution of data onto multiple shards. With Vitess, organizations can even split and merge shards as needs grow, with an atomic cutover step that takes only a few seconds. Companies like BetterCloud, Flipkart, Quiz of Kings, Slack, Square Cash, Stitch Labs and YouTube are using Vitess across various stages of production and deployment. Organizations including Booking.com, GitHub, HubSpot, Slack, and Square are also active contributors to the project.
If you want to buy a router specifically to be modded, you might be best served by working backward. Start by looking at the available offerings, picking one of them based on the feature set, and selecting a suitable device from the hardware compatibility list for that offering.
In this article. I’ve rounded up six of the most common varieties of third-party network operating systems, with the emphasis on what they give you and who they’re best suited for. Some of them are designed for embedded hardware or specific models of router only, some as more hardware-agnostic solutions, and some to serve as the backbone for x86-based appliances.
As the leader of an open source foundation, I have a unique perspective on the way open source technologies are catalyzing the digital transformation of enterprises around the world. More than half of the Fortune 100 is using Cloud Foundry. If you’re wondering why, there are two main reasons: one is the allure of open source, and the other is the strength of the platform itself.
Open and free
Open source is based on freedom. That freedom includes access to the source code, freedom to collaborate and, ultimately, the freedom to innovate. In open source, no one person or company owns a project. Open source is a philosophy and a movement, and what makes open source thrive is the community that grows up around it.
All participants in an open source ecosystem have the opportunity to shape and improve the software. Users can identify features they need and contribute code upstream. Everyone has a chance to make a difference.
In the past, many embedded projects used off-the-shelf distributions and stripped them down to bare essentials for a number of reasons. First, removing unused packages reduced storage requirements. Embedded systems are typically shy of large amounts of storage at boot time, and the storage available, in non-volatile memory, can require copying large amounts of the OS to memory to run. Second, removing unused packages reduced possible attack vectors. There is no sense hanging on to potentially vulnerable packages if you don’t need them. Finally, removing unused packages reduced distribution management overhead. Having dependencies between packages means keeping them in sync if any one package requires an update from the upstream distribution. That can be a validation nightmare.
Yet, starting with an existing distribution and removing packages isn’t as easy as it sounds. Removing one package might break dependencies held by a variety of other packages, and dependencies can change in the upstream distribution management.
Security is tantamount to peace of mind. After all, security is a big reason why so many users migrated to Linux in the first place. But why stop with merely adopting the platform, when you can also employ several techniques and technologies to help secure your desktop or server systems.
One such technology involves keys—in the form of PGP and SSH. PGP keys allow you to encrypt and decrypt emails and files, and SSH keys allow you to log into servers with an added layer of security.
Sure, you can manage these keys via the command-line interface (CLI), but what if you’re working on a desktop with a resplendent GUI? Experienced Linux users may cringe at the idea of shrugging off the command line, but not all users have the same skill set and comfort level there. Thus, the GUI!
In this article, I will walk you through the process of managing both PGP and SSH keys through the Seahorse GUI tool. Seahorse has a pretty impressive feature set; it can:
Encrypt/decrypt/sign files and text.
Manage your keys and keyring.
Synchronize your keys and your keyring with remote key servers.
Sign and publish keys.
Cache your passphrase.
Backup both keys and keyring.
Add an image in any GDK supported format as a OpenPGP photo ID.
Create, configure, and cache SSH keys.
For those that don’t know, Seahorse is a GNOME application for managing both encryption keys and passwords within the GNOME keyring. But fear not, Seahorse is available for installation on numerous desktops. And since Seahorse is found in the standard repositories, you can open up your desktop’s app store (such as Ubuntu Software or Elementary OS AppCenter) and install. To do this, locate Seahorse in your distribution’s application store and click to install. Once you have Seahorse installed, you’re ready to start making use of a very handy tool.
Let’s do just that.
PGP Keys
The first thing we’re going to do is create a new PGP key. As I said earlier, PGP keys can be used to encrypt email (with tools like Thunderbird’s Enigmail or the built-in encryption function with Evolution). A PGP key also allows you to encrypt files. Anyone with your public key will be able to decrypt those emails or files. Without a PGP key, no can do.
Creating a new PGP key pair is incredibly simple with Seahorse. Here’s what you do:
Open the Seahorse app
Click the + button in the upper left corner of the main pane
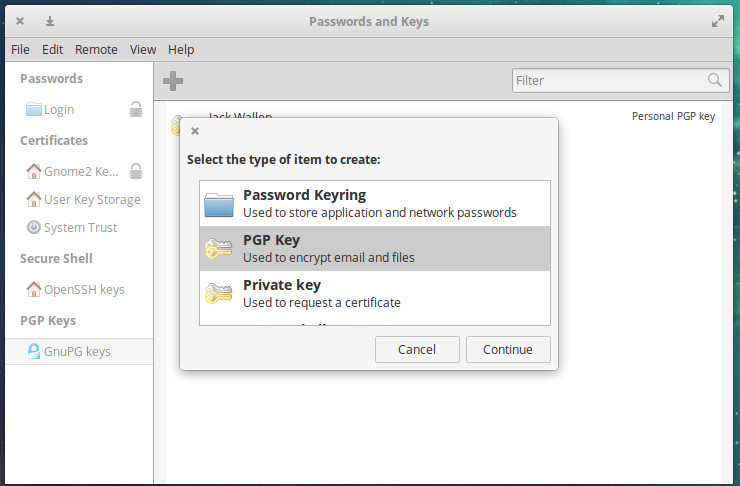
Select PGP Key (Figure 1)
Click Continue
When prompted, type a full name and email address
Click Create
Figure 1: Creating a PGP key with Seahorse.
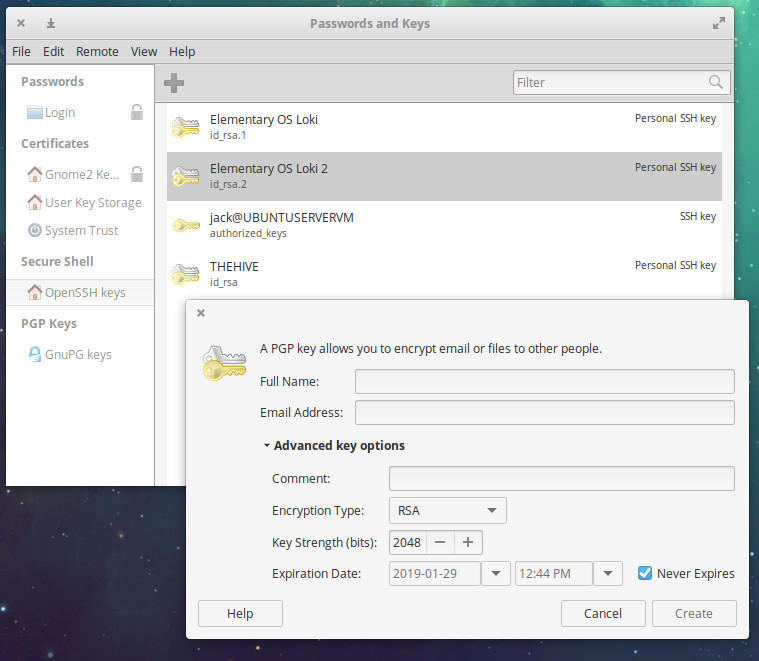
While creating your PGP key, you can click to expand the Advanced key options section, where you can configure a comment for the key, encryption type, key strength, and expiration date (Figure 2).
Figure 2: PGP key advanced options.
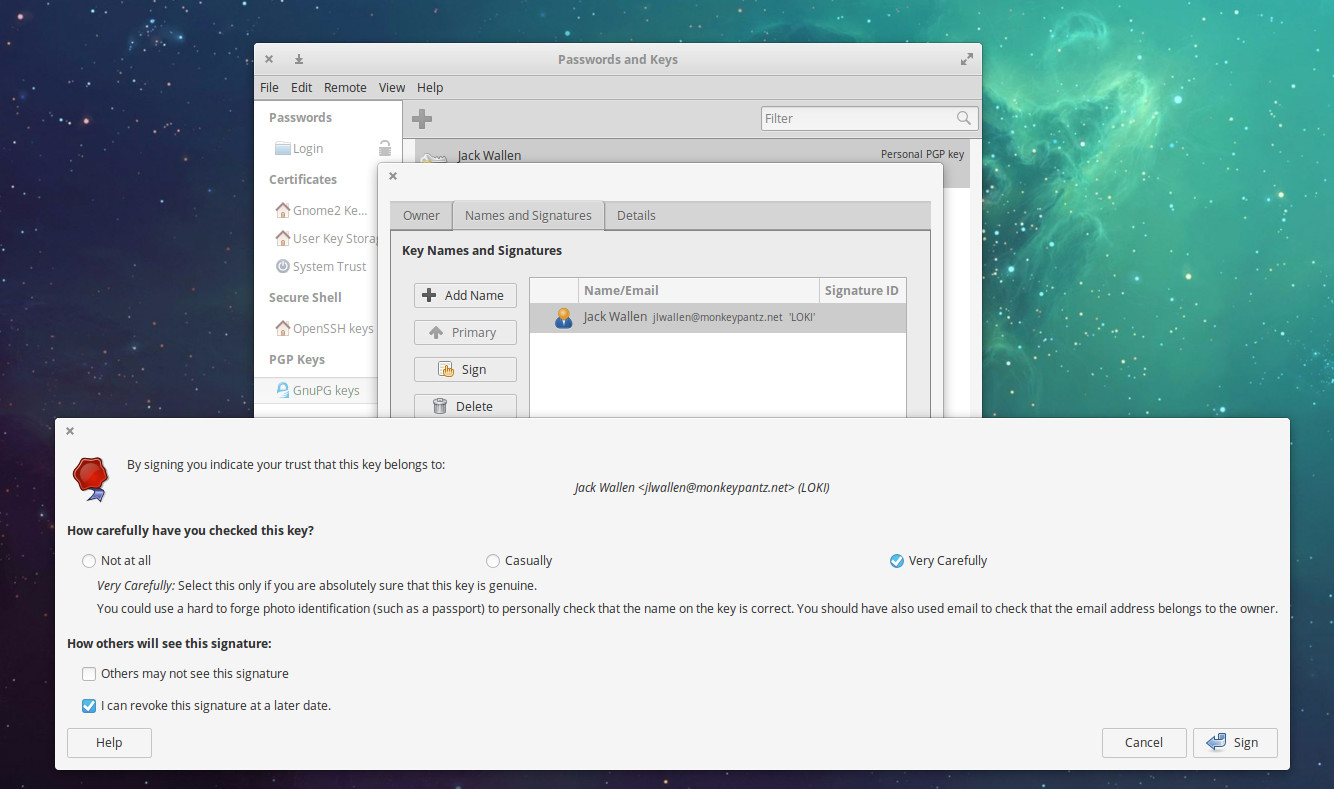
The comment section is very handy to help you remember a key’s purpose (or other informative bits). With your PGP created, double-click on it from the key listing. In the resulting window, click on the Names and Signatures tab. In this window, you can sign your key (to indicate you trust this key). Click the Sign button and then (in the resulting window) indicate how carefully you’ve checked this key and how others will see the signature (Figure 3).
Figure 3: Signing a key to indicate trust level.
Signing keys is very important when you’re dealing with other people’s keys, as a signed key will ensure your system (and you) you’ve done the work and can fully trust an imported key.
Speaking of imported keys, Seahorse allows you to easily import someone’s public key file (the file will end in .asc). Having someone’s public key on your system means you can decrypt emails and files sent to you from them. However, Seahorse has suffered a known bug for quite some time. The problem is that Seahorse imports using gpg version one, but displays with gpg version two. This means, until this long-standing bug is fixed, importing public keys will always fail. If you want to import a public PGP key into Seahorse, you’re going to have to use the command line. So, if someone has sent you the file olivia.asc, and you want to import it so it can be used with Seahorse, you would issue the command gpg2 –import olivia.asc. That key would then appear in the GnuPG Keys listing. You can open the key, click the I trust signatures button, and then click the Sign this key button to indicate how carefully you’ve checked the key in question.
SSH Keys
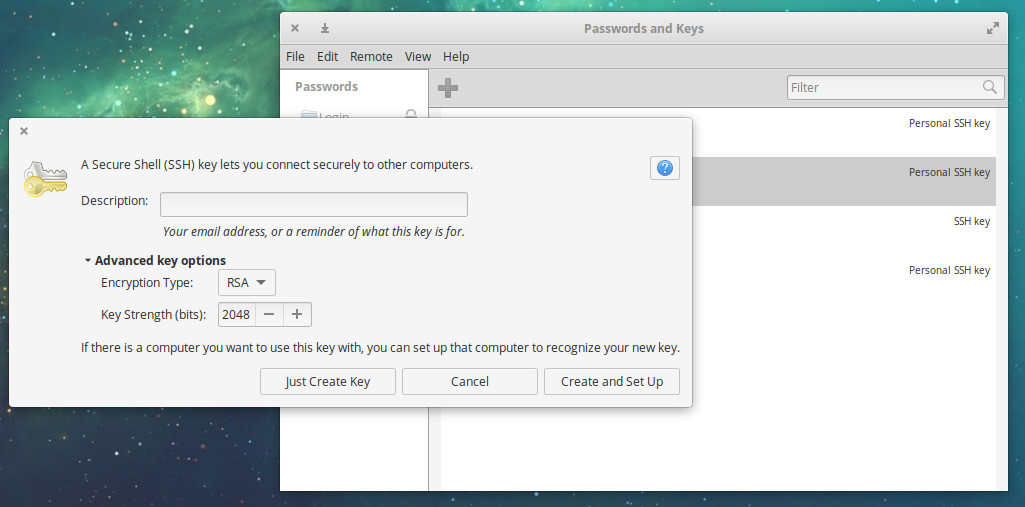
Now we get to what I consider to be the most important aspect of Seahorse—SSH keys. Not only does Seahorse make it easy to generate an SSH key, it makes it easy to send that key to a server, so you can take advantage of SSH key authentication. Here’s how you generate a new key and then export it to a remote server.
Open up Seahorse
Click the + button
Select Secure Shell Key
Click Continue
Give the key a description
Click Create and Set Up
Type and verify a passphrase for the key
Click OK
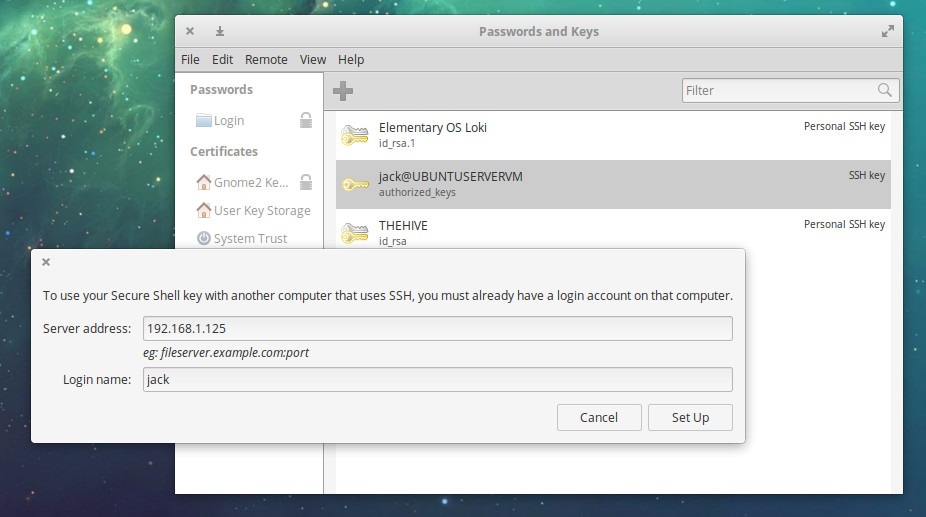
Type the address of the remote server and a remote login name found on the server (Figure 4)
Type the password for the remote user
Click OK
Figure 4: Uploading an SSH key to a remote server.
The new key will be uploaded to the remote server and is ready to use. If your server is set up for SSH key authentication, you’re good to go.
Do note, during the creation of an SSH key, you can click to expand the Advanced key options and configure Encryption Type and Key Strength (Figure 5).
Figure 5: Advanced SSH key options.
A must-use for new Linux users
Any new-to-Linux user should get familiar with Seahorse. Even with its flaws, Seahorse is still an incredibly handy tool to have at the ready. At some point, you will likely want (or need) to encrypt or decrypt an email/file, or manage secure shell keys for SSH key authentication. If you want to do this, while avoiding the command line, Seahorse is the tool to use.
Learn more about Linux through the free “Introduction to Linux” course from The Linux Foundation and edX.